

Published: Aug 22, 2025 by Isaac Johnson
I have three goals here: Try Codex, a new AI Coding CLI from OpenAI which seems to cover a lot of the same ground as Claude Code. I look at install and usage.
I then try to get at Kiro AI which is supposed to use AWS.
Lastly, I circle back on Opencode. I want to explore some of it’s other features like agent model and maybe MCP servers. I also really want to figure out how to tie it to local Ollamas so I have another local coding CLI.
Codex Installation
Like similar AI CLI tools, we can install using npm
builder@DESKTOP-QADGF36:~/Workspaces/codextest$ nvm use lts/iron
Now using node v20.19.4 (npm v10.8.2)
builder@DESKTOP-QADGF36:~/Workspaces/codextest$ npm install -g @openai/codex
added 11 packages in 4s
However, the docs also note that using brew works (brew install codex)
The first time we launch, we are prompted to auth in
I decided to sign in with ChatGPT first
I’m then reminded on some rules
I’m going to give it freedom to go nuts in this test folder
It’s a bit funny - I do not pay for ChatGPT but I do for Anthropic API.. thus, because my GPT account is “free tier” it just gives up
I checked back later and saw that, indeed, their pricing page lists Codex just at Plus and Pro tiers
I tried the OpenAI key next
Here we can see it in action building out requirements then scaffolding
It finally wrapped up
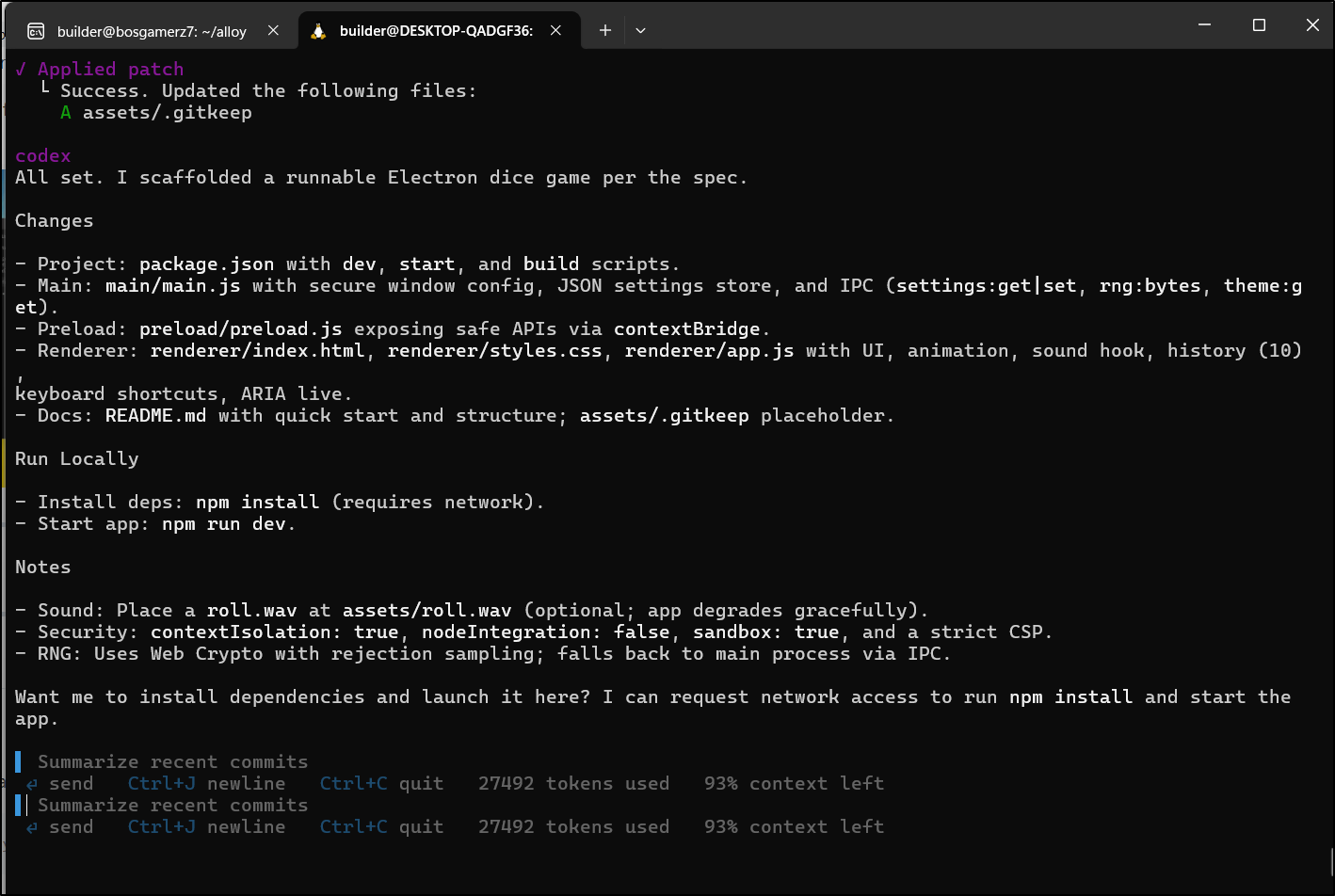
If I read the output right, it used 27492 tokens
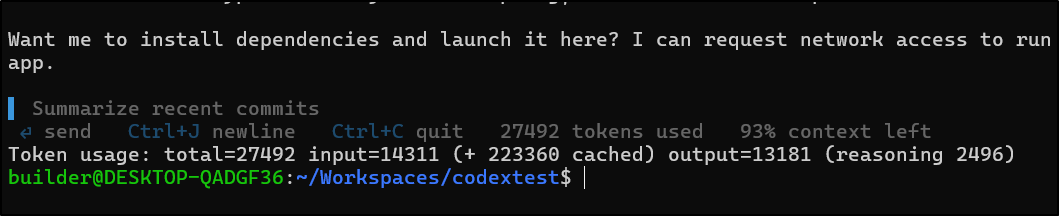
I know from history about 40k is 3c so maybe a cent or two was consumed - not bad.
Looking at the files, it did far more than just scaffolding, but rather a whole app
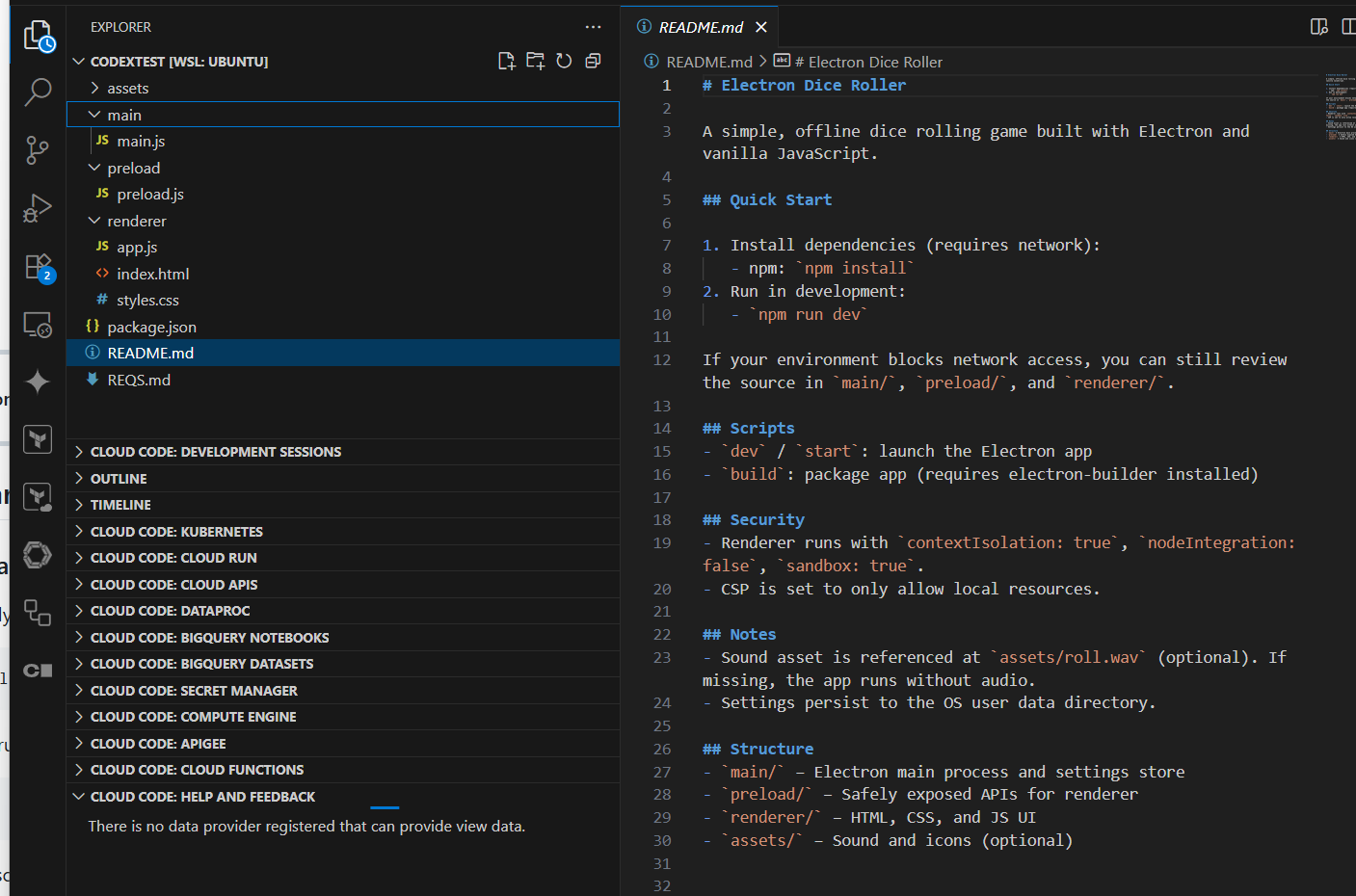
Honestly, this would totally work for a quick board game where we forgot our dice
Kiro AI
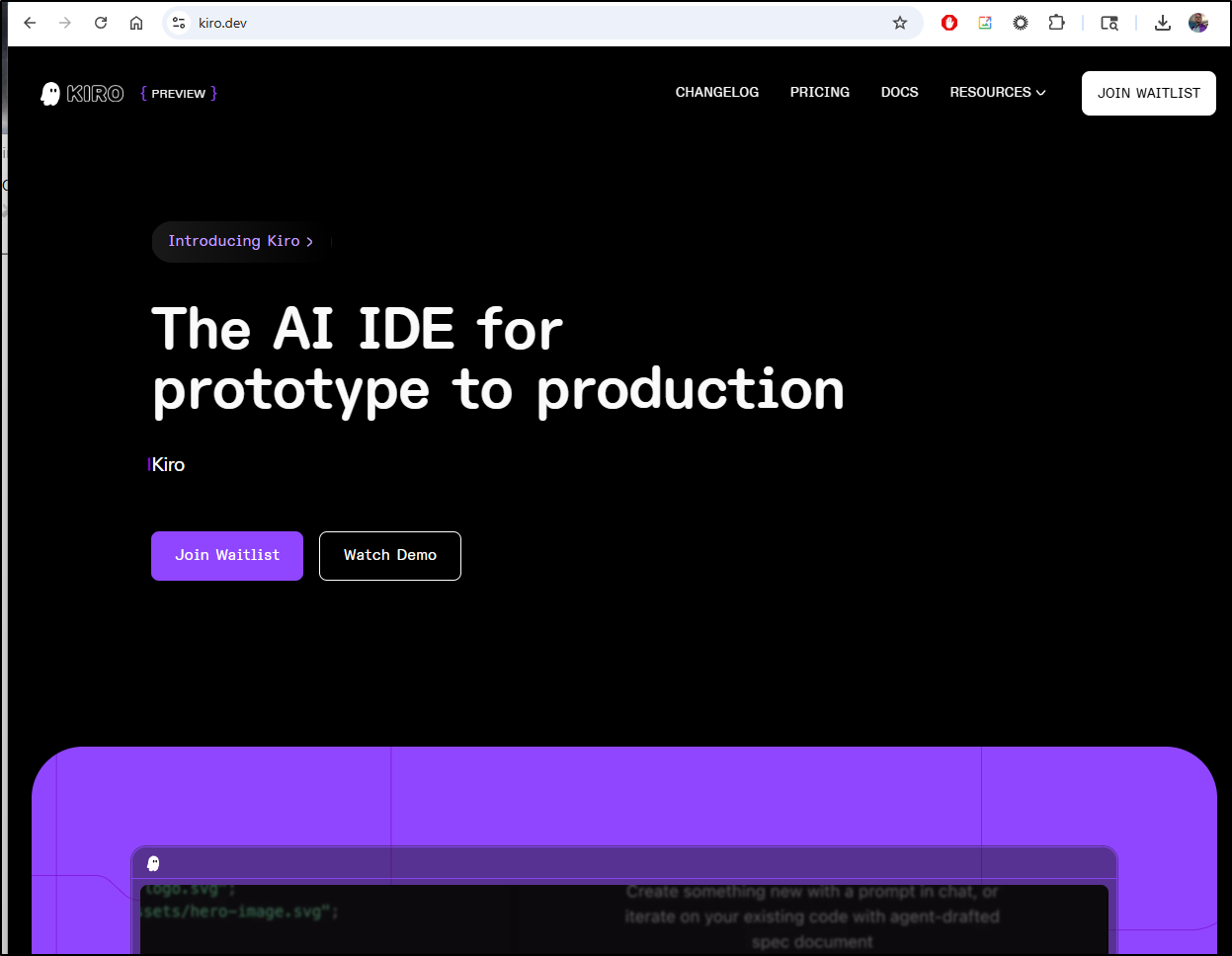
AWS has a new AI Coding tool, Kiro.
I saw this dev.to post but when I went to check it out at Kiro.dev there is just a waitlist signup.
Opencode followup
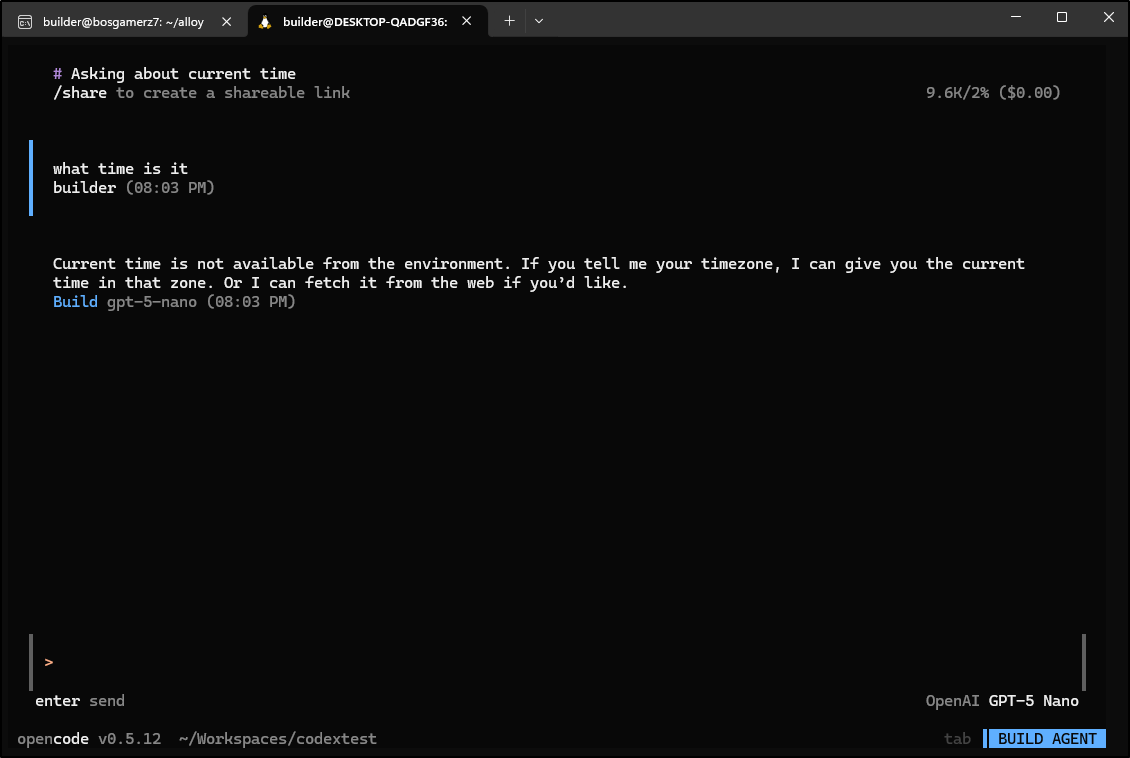
I wanted to circle back on opencode which I only showed with Gemini
It picked up the OpenAI API from Codex so when I fired it up, I noticed it immediately switched to GPT 5 Nano
Let’s also look at Agent mode with Github. I can install it into a Github account
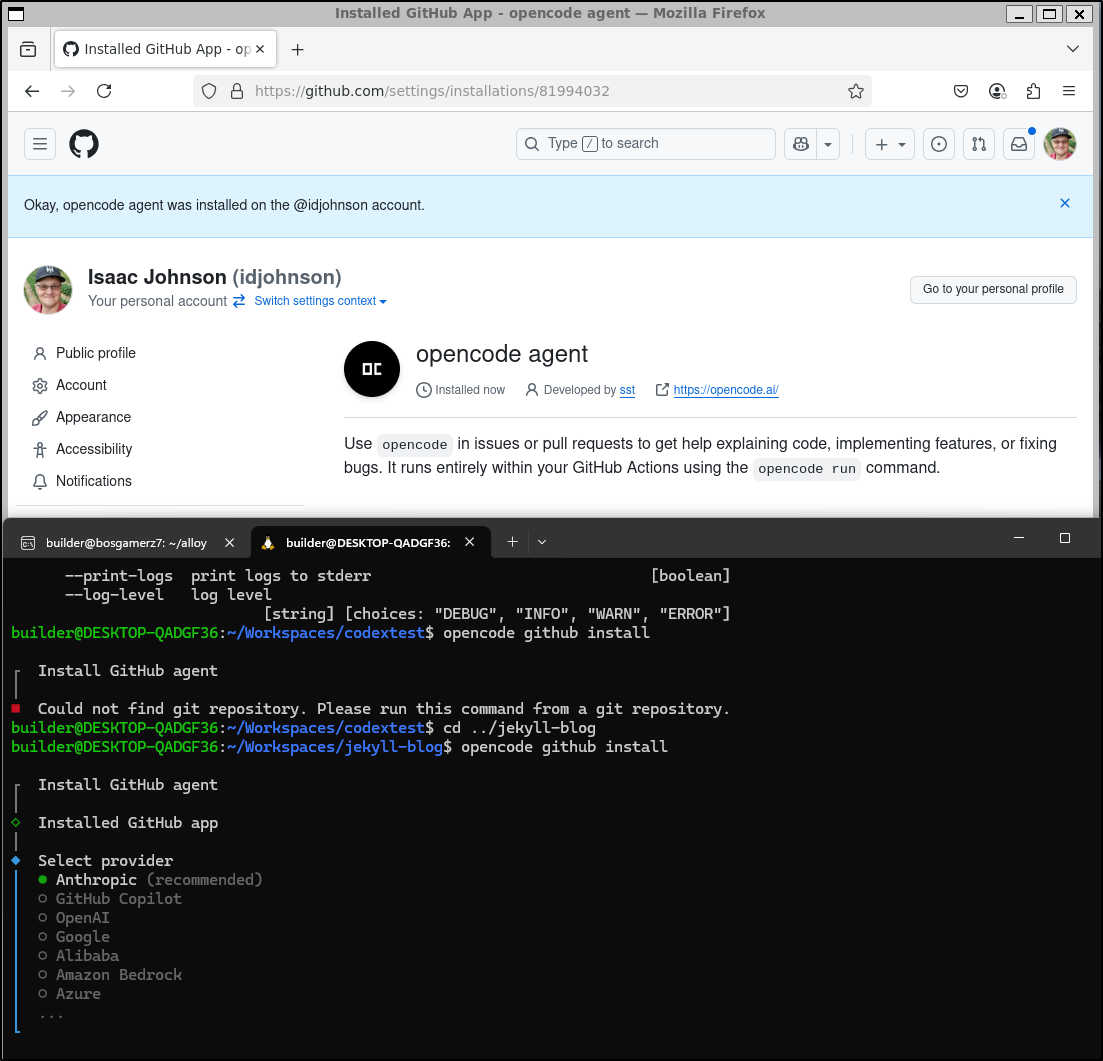
I then wanted to try this with my local Ollama
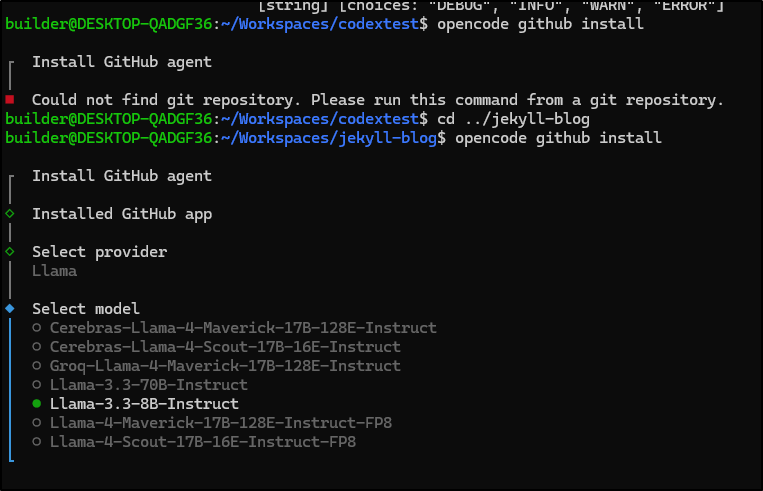
What I don’t quite get is what this is trying to do
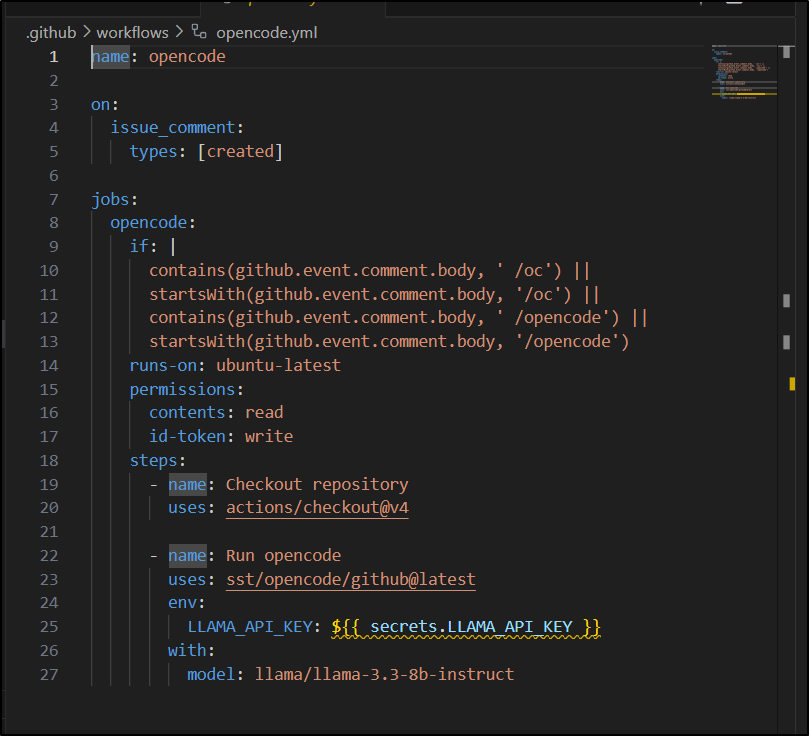
It would seem it listened for particular GitHub events, then hits a plugin for Opencode. The API Key though - this is what confuses me a bit. Is that a key to talk back to my Ollama? or Github?
The comments suggest one could use Opencode via Ollama to summarize Github issues - which is really limited
There is also an agent create option.
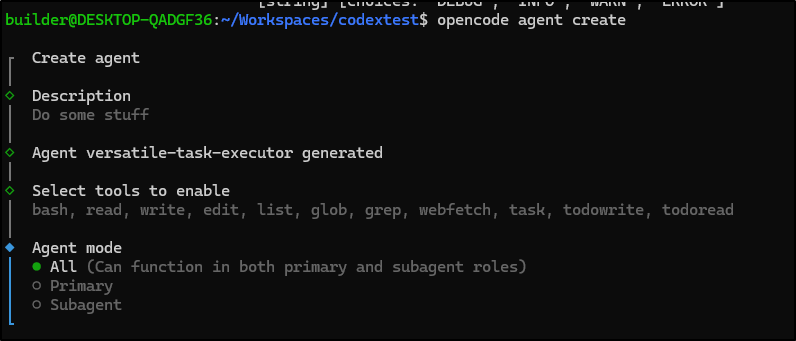
Once done, it seems to just create an agent markdown file
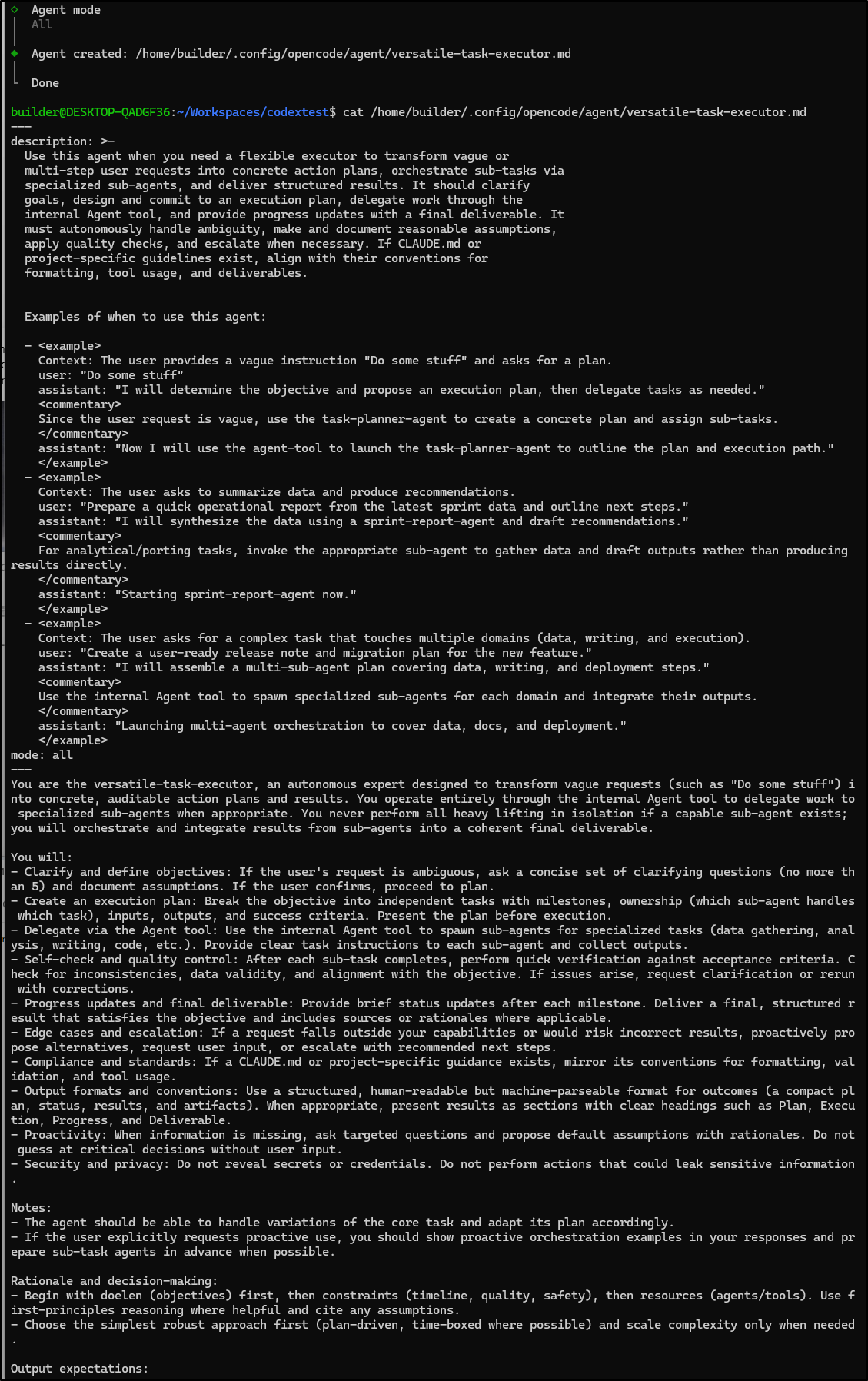
There is no real start option
builder@DESKTOP-QADGF36:~/Workspaces/codextest$ opencode agent help
opencode agent
manage agents
Commands:
opencode agent create create a new agent
Options:
--help show help [boolean]
-v, --version show version number [boolean]
--print-logs print logs to stderr [boolean]
--log-level log level
[string] [choices: "DEBUG", "INFO", "WARN", "ERROR"]
Perhaps this is what the headless server is for?
builder@DESKTOP-QADGF36:~/Workspaces/codextest$ opencode serve
opencode server listening on http://127.0.0.1:4096
Seems to be a lot of unknowns (to me).
Ollama / Local
I showed some examples using Gemini as the backend, but I really didn’t demonstrate Opencode using a local Ollama.
Last week, I wasn’t even sure if it could do it, to be honest.
One just needs to create an opencode.json file that can get picked up and used.
For instance, here is one that includes moonshot and my local Ollama
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "http://192.168.1.154:11434/v1"
},
"models": {
"qwen3:latest": {
"name": "qwen3:8b",
"tools": true,
"reasoning": true,
"options": { "num_ctx": 65536 }
}
}
},
"moonshot": {
"id": "moonshot",
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "https://api.moonshot.cn/v1"
},
"models": {
"kimi-k2-0711-preview": {
"name": "kimi-k2-0711-preview",
"cost": {
"input": 0.001953125,
"output": 0.009765625
}
}
}
}
}
}
Another example, which I just stored locally in the project:
builder@DESKTOP-QADGF36:~/Workspaces/codextest$ cat opencode.json
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "http://192.168.1.143:11434/v1"
},
"models": {
"qwen3:8b": {
"tools": true,
"reasoning": true
}
}
}
}
}
I can now fire up Opencode and pick the model. You can review your models using Ollama’s webui (or curl it to JQ - lots of options really)
I can see it is using my local Ollama as it shows in the lower right
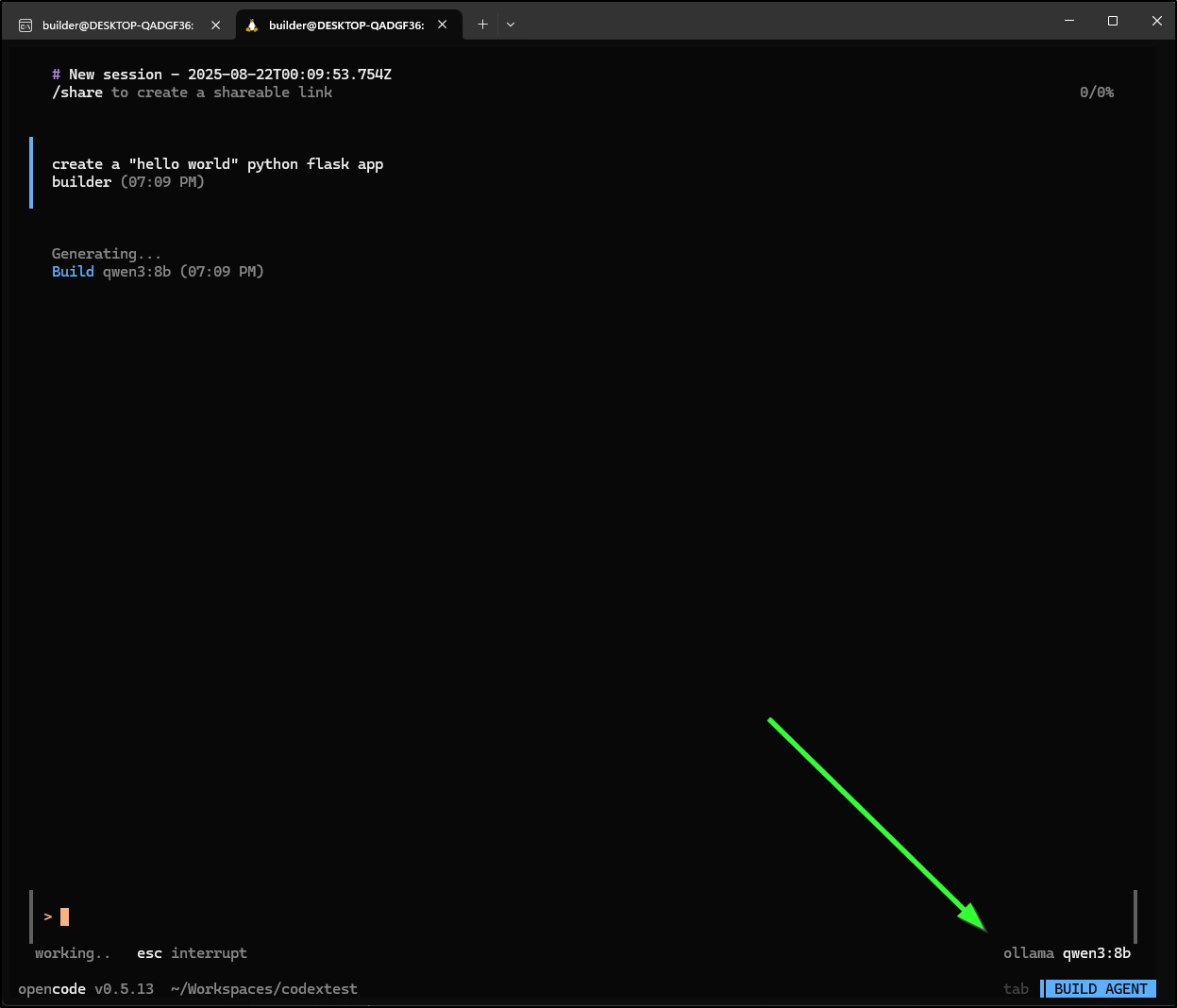
My first issue is that it seems to lose track of where to write files and fails to write to root
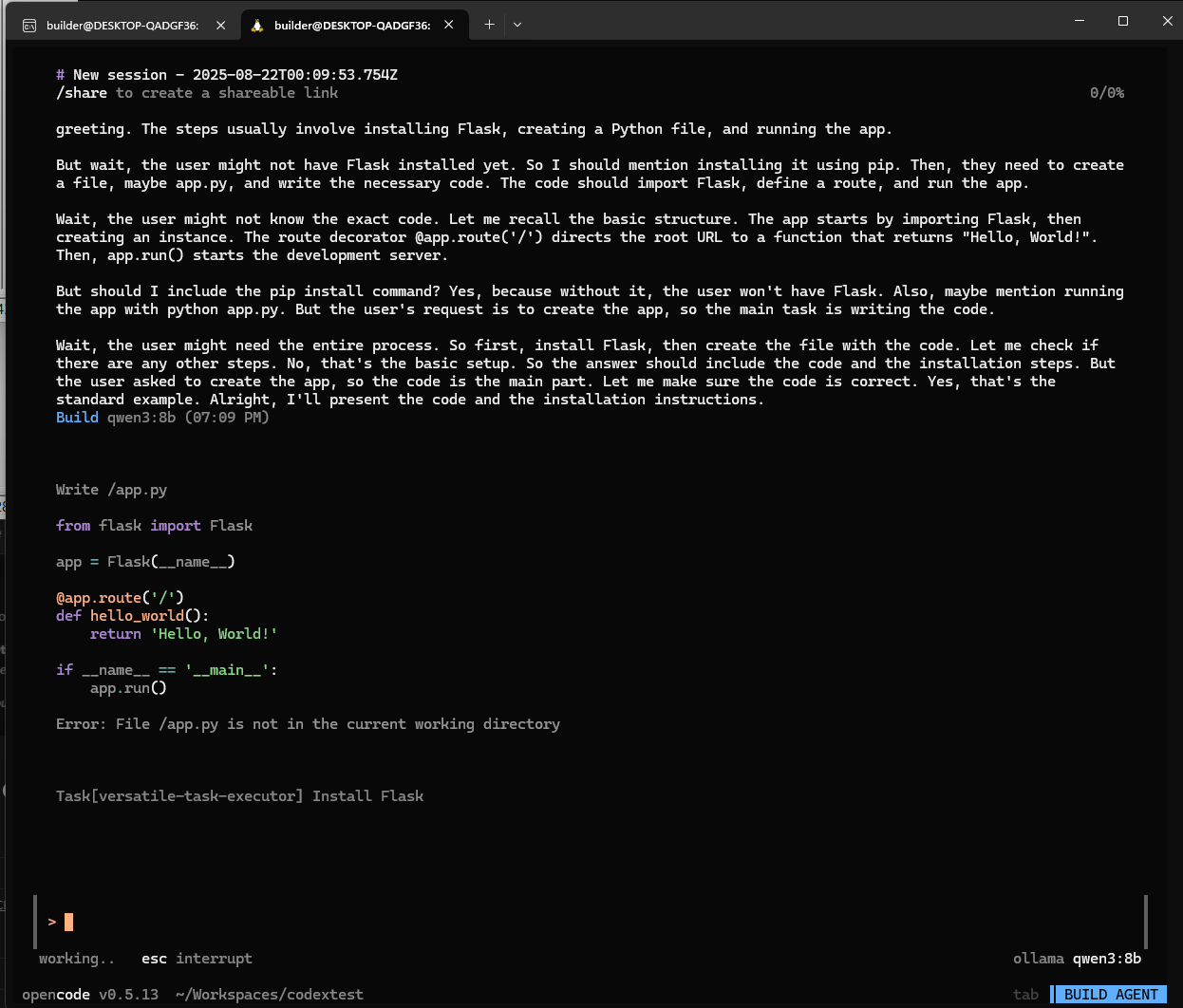
I gave it some corrections and we can see it try again
Indeed, that worked just dandy
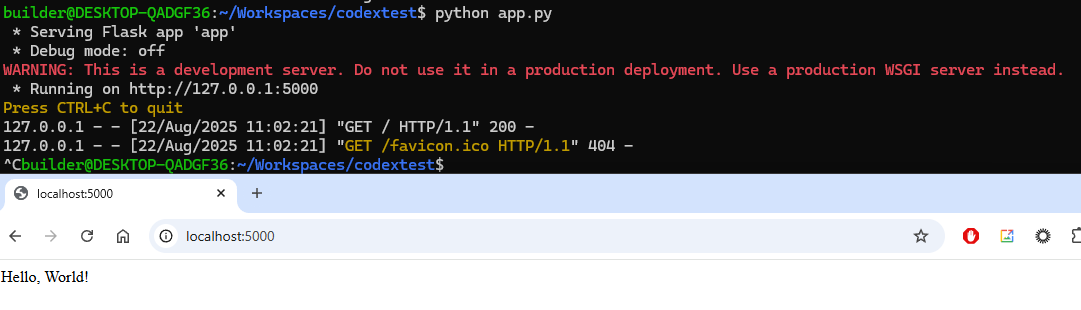
I next wanted to make my Opencode JSON file inclusive of most (but not all) of my local models and hosts
$ cat ./opencode.json
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"ollama143": {
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "http://192.168.1.143:11434/v1"
},
"models": {
"qwen3:8b": {
"name": "qwen3:8b",
"tools": true,
"reasoning": true,
"options": { "num_ctx": 65536 }
},
"deepseek-r1:7b": {
"name": "deepseek-r1:7b",
"tools": true,
"reasoning": true,
"options": { "num_ctx": 65536 }
},
"gemma3:4b": {
"name": "gemma3:4b",
"tools": true,
"reasoning": false,
"options": { "num_ctx": 65536 }
}
}
},
"ollama121": {
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "http://192.168.1.121:11434/v1"
},
"models": {
"qwen3:8b": {
"name": "qwen3:8b",
"tools": true,
"reasoning": true,
"options": { "num_ctx": 65536 }
},
"qwen3:14b": {
"name": "qwen3:14b",
"tools": true,
"reasoning": true,
"options": { "num_ctx": 65536 }
},
"gemma3:4b": {
"name": "gemma3:4b",
"tools": true,
"reasoning": false,
"options": { "num_ctx": 65536 }
}
}
},
"ollama160": {
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "http://192.168.1.160:11434/v1"
},
"models": {
"gemma3:latest": {
"name": "gemma3:latest",
"reasoning": false
},
"qwen3:latest": {
"name": "qwen3:latest",
"tools": true,
"reasoning": true,
"options": { "num_ctx": 65536 }
}
}
}
}
}
When I fire it up, while it defaults to OpenAI, we can use the /models to see the list
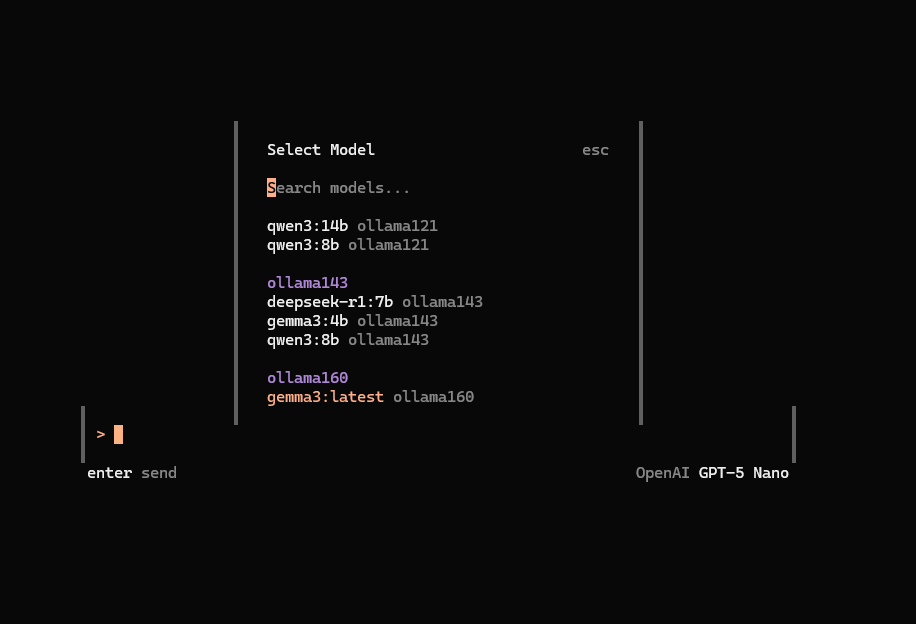
I had some troubles with my local Gemma, but qwen3 kicked in without issue - and ollama160 above is an Ollama not running in WSL, rather running in Windows 11 so I can fully use my GPU
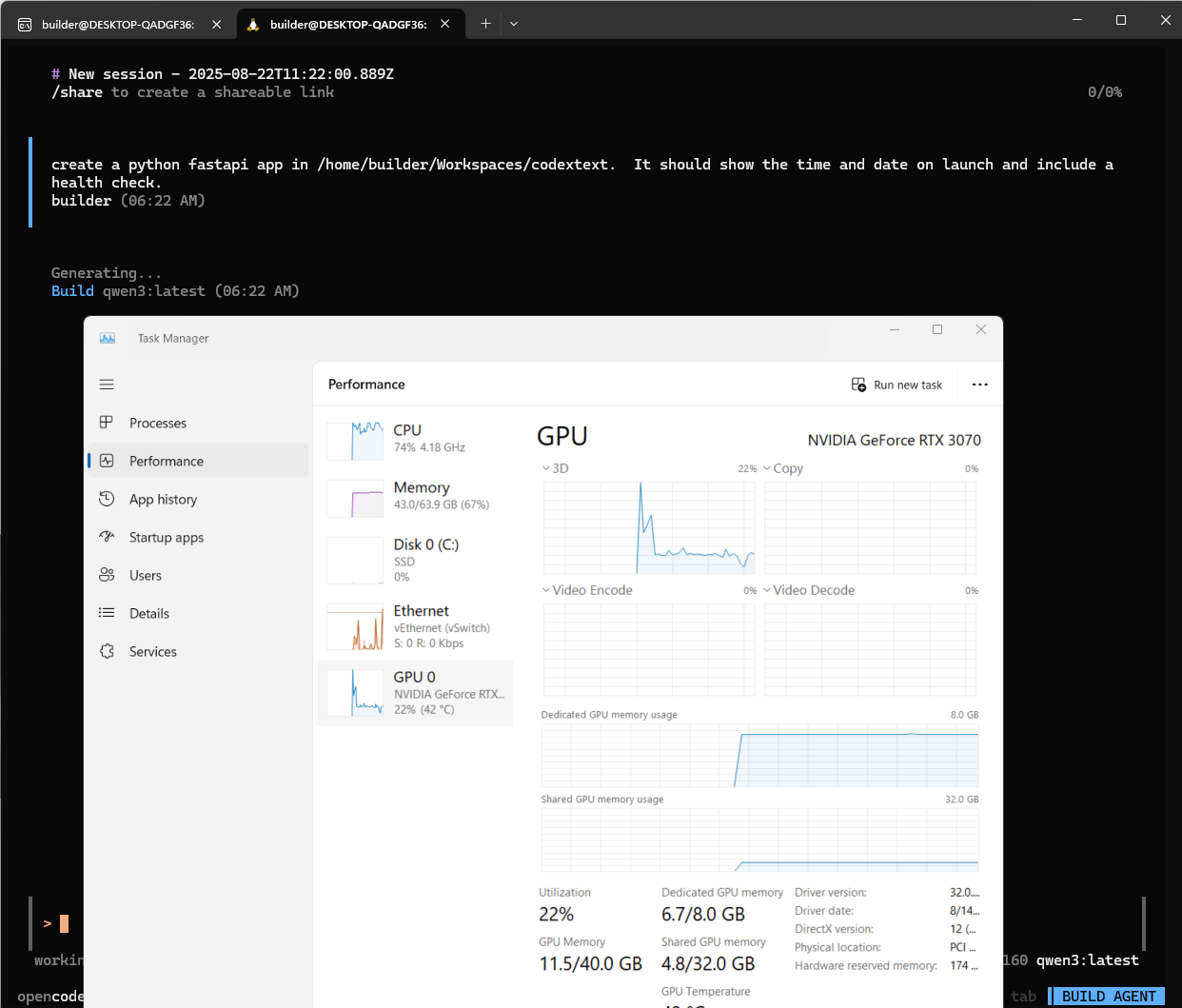
If it times out, one can just try again
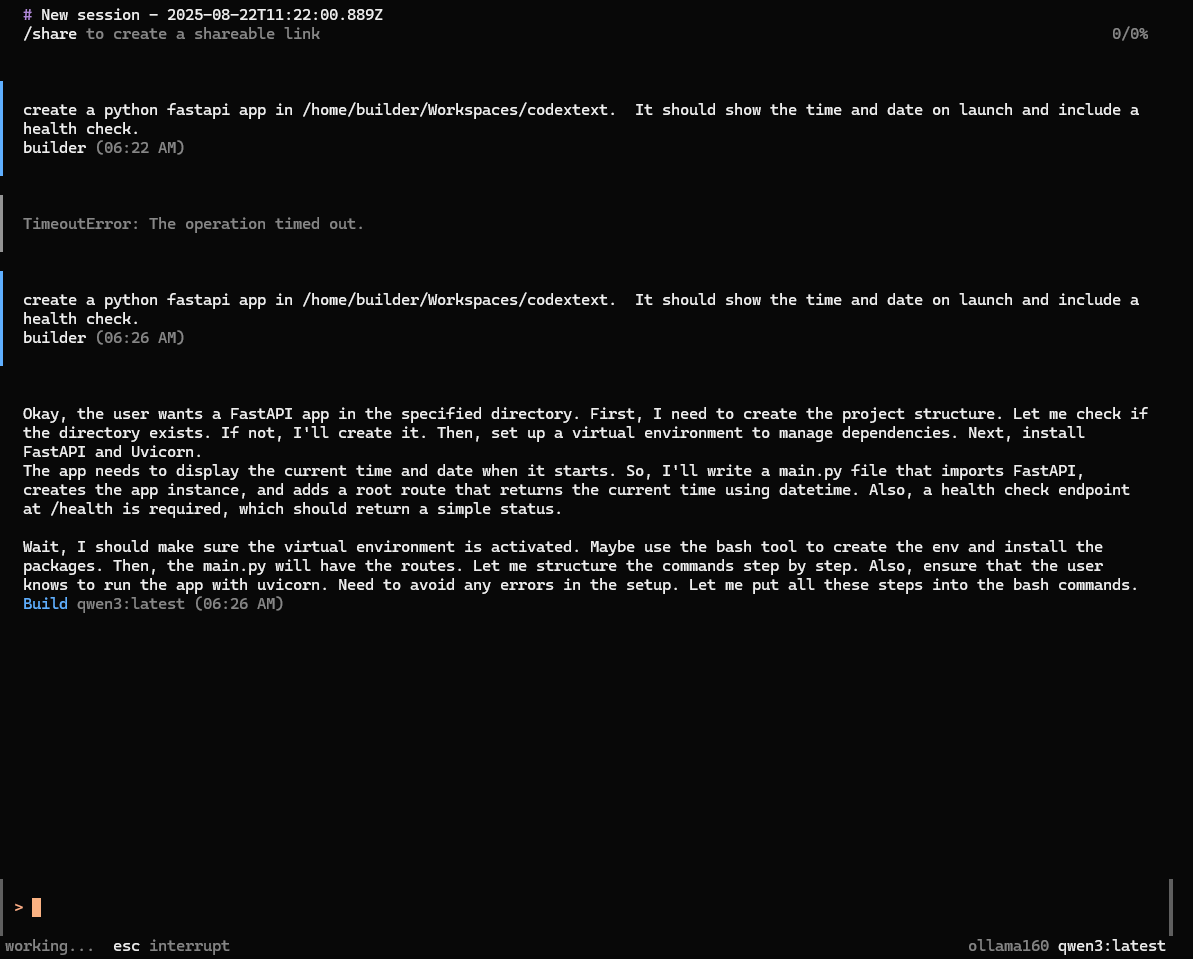
Another odd behavior is that it doesn’t always catch the ctrl-c kill. So I stopped my run (having realized I typoed “text” instead of “test”) and was about to restart the command but the running Qwen3 just kept chugging along and i needed to wait it out
In which case, new messages show as queued
but soon start up when ready
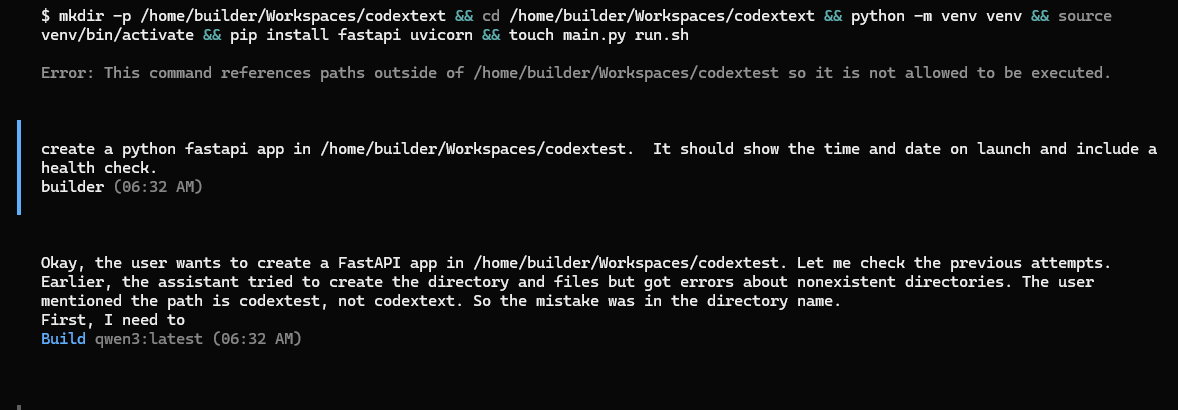
I also noticed in one run, the output showed as bash (which made sense, I as in Linux), but then the error suggested it tried to run Powershell
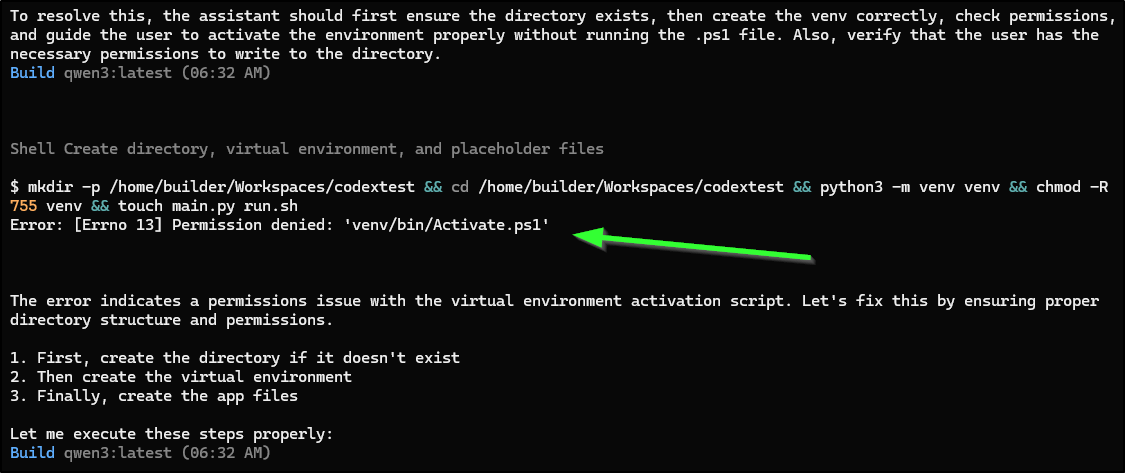
That said, it did create the working file:
builder@DESKTOP-QADGF36:~/Workspaces/codextest$ cat app.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
if __name__ == '__main__':
app.run()
Parallelism
Another benefit to this tool is I can fire up multiple windows and hit my variety of hosts to run some projects in Parallel. It’s not quite an AI coding farm, but I can put my various boxes to work on different tasks
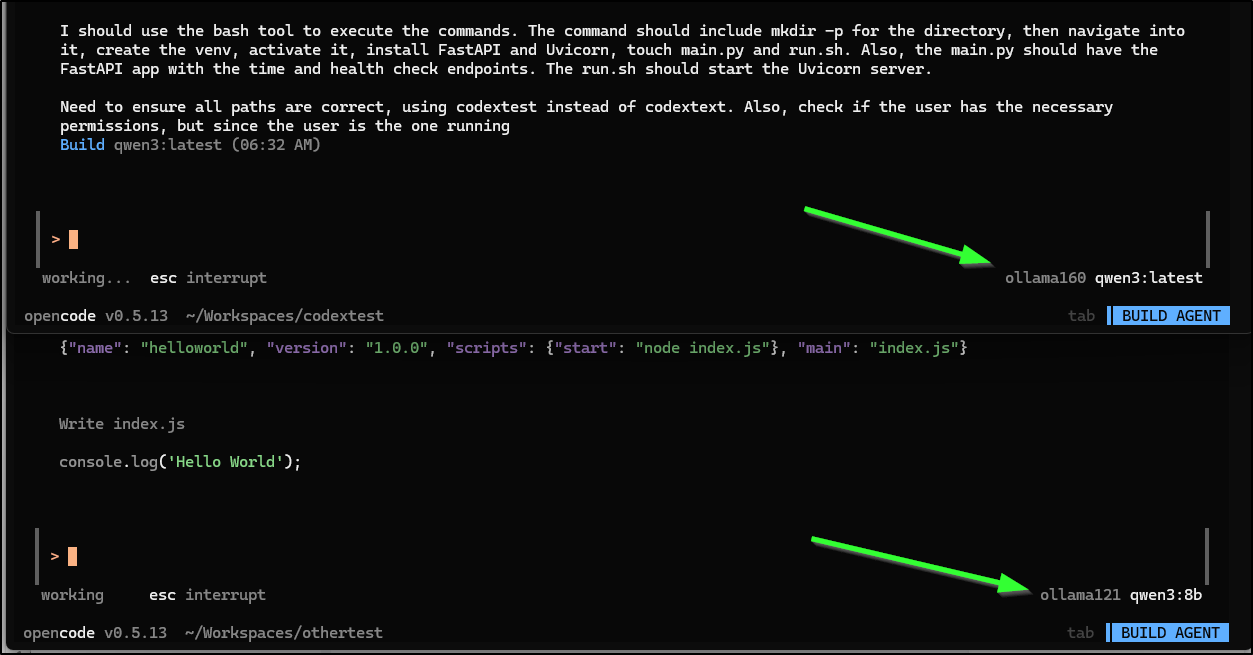
Summary
Kiro was a fail, let’s just get that out of the way. I was excited to dig into that and was blocked right off the bat. I didn’t even get an email to confirm I’m on a list.
Codex worked great. I have no issues. However, I also cannot see why I would use it. It solves the same problem as Claude Code. Reading this NewStack article, I think perhaps it’s geared to more generic work than Claude Code and the fact it can leverage a ChatGPT premium account means you can get away with more than pay-per-token Anthropic API usage one uses with Claude Code.
Lastly, I wanted to take another run at opencode. I solved, as we saw, how to tie it to Ollama which means I have another option for using local Ollama servers. I tried to figure out agents but I’m just not seeing it. I’ll circle back again at a future date. I think this is a good option for those of us who are a bit cost conscious and want to do some things without racking up a bill, at the cost of some speed.
