

Published: Mar 6, 2025 by Isaac Johnson
Every now and then I like to put out a post about all the small issues and cleanups I need to take care of on a regular basis.
Today we’ll cover Gitlab auth issues and tweaking Gitlab schedules.
I will cover backing up private GIT repos from Forgejo to Gitea, then from Github to Forgejo.
Then, I will talk about handling NAS reboots after pushed patches and wrap by covering what happens to Rancher K3s after year (namely, rotating cluster creds) before wrapping with a disk space issue that keeps coming back every few months (solving it with Ansible)
Gitlab
For the longest time I’ve seen regular emails about a docker job in Gitlab (I’ve clearly abandoned) that has been failing
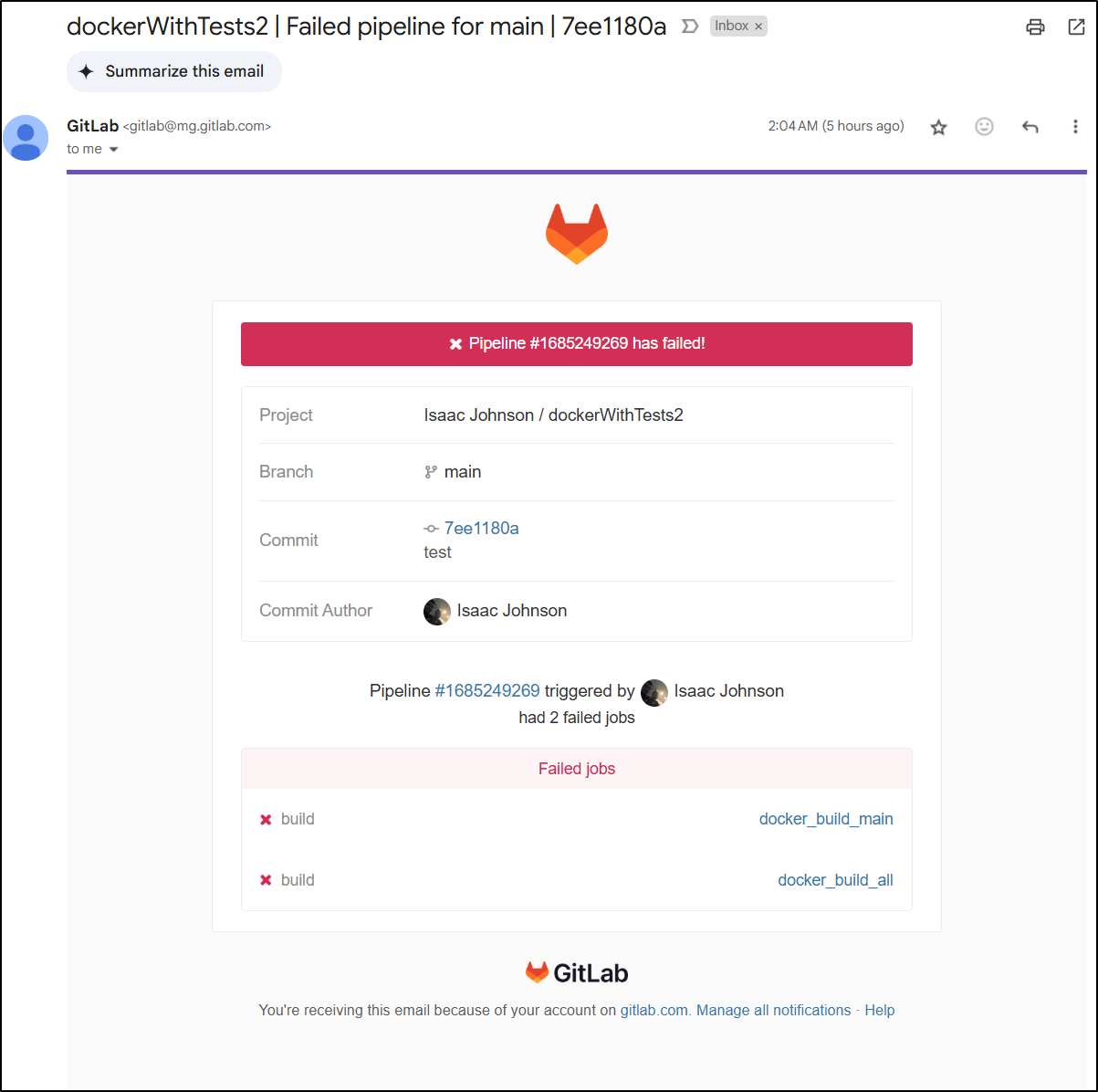
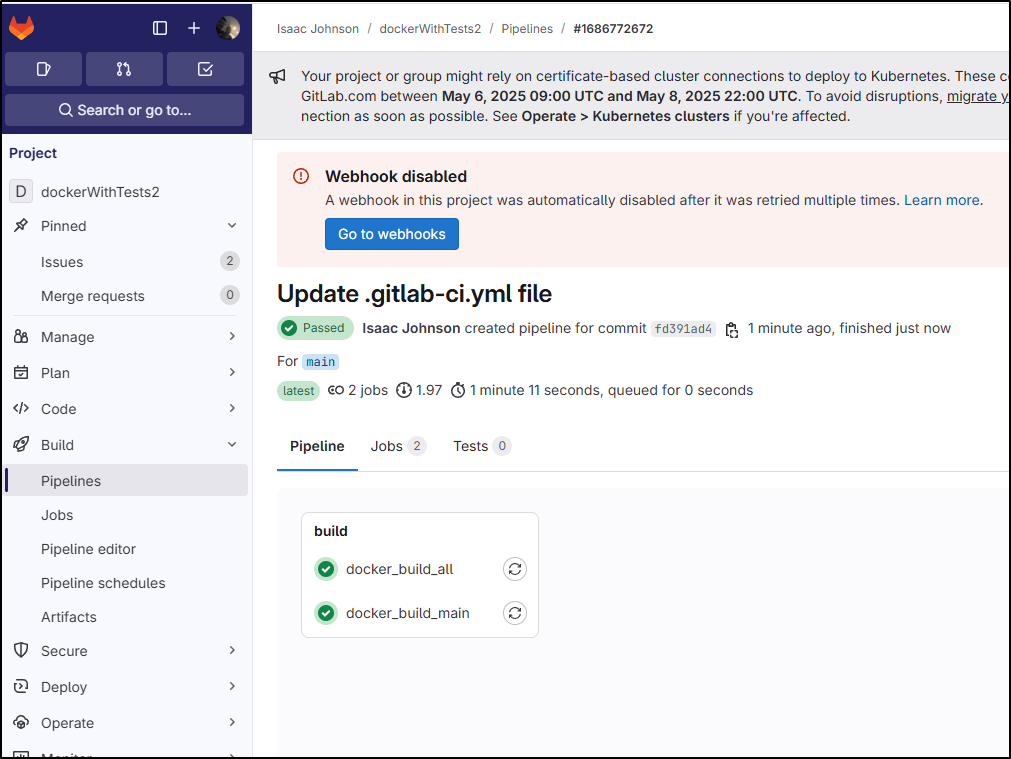
If I go to the pipeline details page, I can see both jobs are failing
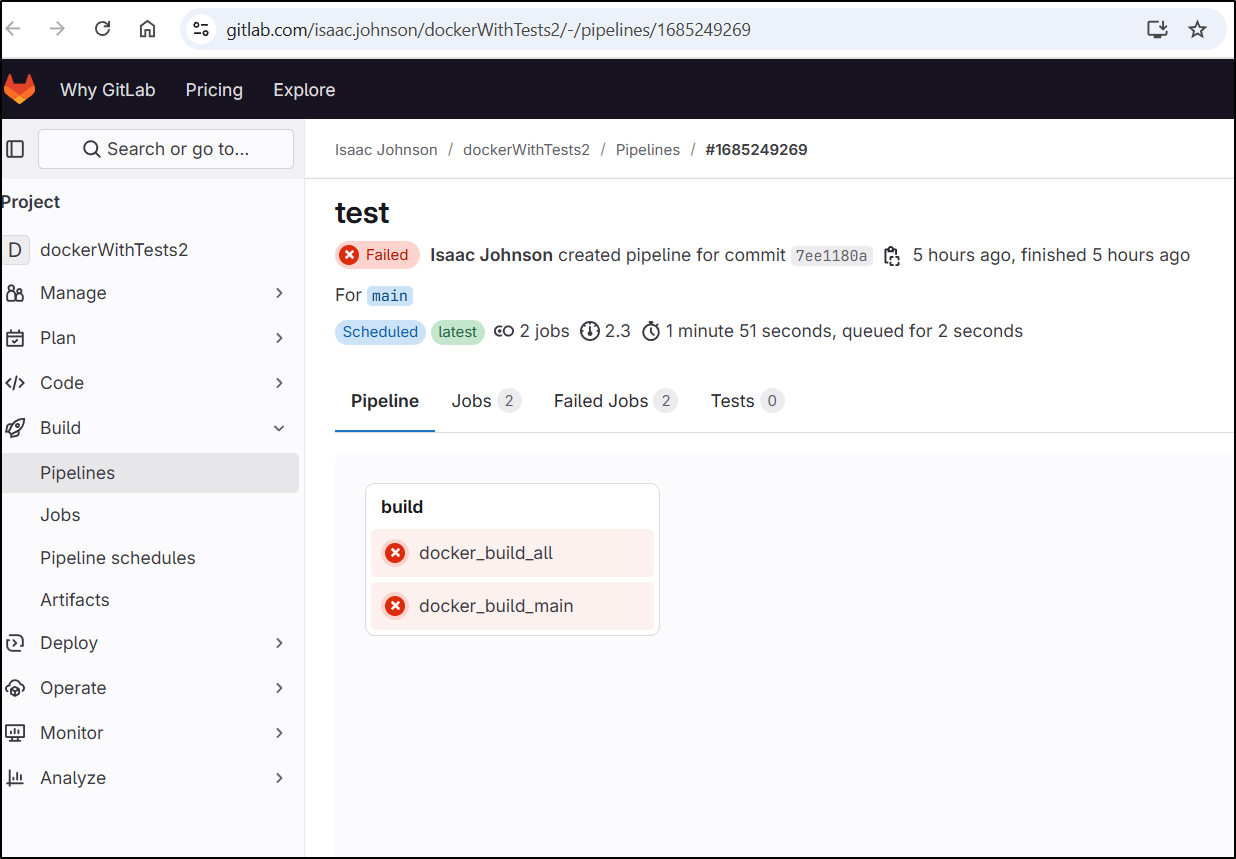
The two issues seem to be an expired cred for logging into the Gitlab registry
$ set +x
$ docker login registry.gitlab.com -u $GITLAB_REGISTRY_USER -p $GITLAB_REGISTRY_PASSWORD
WARNING! Using --password via the CLI is insecure. Use --password-stdin.
Error response from daemon: Get "https://registry.gitlab.com/v2/": unauthorized: HTTP Basic: Access denied. If a password was provided for Git authentication, the password was incorrect or you're required to use a token instead of a password. If a token was provided, it was either incorrect, expired, or improperly scoped. See https://gitlab.com/help/user/profile/account/two_factor_authentication_troubleshooting.md#error-http-basic-access-denied-if-a-password-was-provided-for-git-authentication-
Cleaning up project directory and file based variables
00:00
ERROR: Job failed: exit code 1
And an always-auth error for npm, but that too uses a token in the URL (perhaps it’s expired)
sing docker image sha256:b8b766f73aa0a7076042bf2610b0a0fa0bd055884539b1d207db00fda1f01210 for node:latest with digest node@sha256:a182b9b37154a3e11e5c1d15145470ceb22069646d0b7390de226da2548aa2a7 ...
$ echo "@nodewithtests:registry=https://gitlab.com/api/v4/projects/36439577/packages/npm/">.npmrc
$ npm config set -- '//gitlab.com/api/v4/projects/36439577/packages/npm/:_authToken' "${CI_JOB_TOKEN}"
$ npm config set always-auth true
npm error `always-auth` is not a valid npm option
npm error A complete log of this run can be found in: /root/.npm/_logs/2025-02-24T08_02_56_414Z-debug-0.log
Cleaning up project directory and file based variables
00:01
ERROR: Job failed: exit code 1
As we can see, I haven’t really touched this repo since 2022
I think the format has changed slightly for both the docker login (using stdin) and npm (adding =)
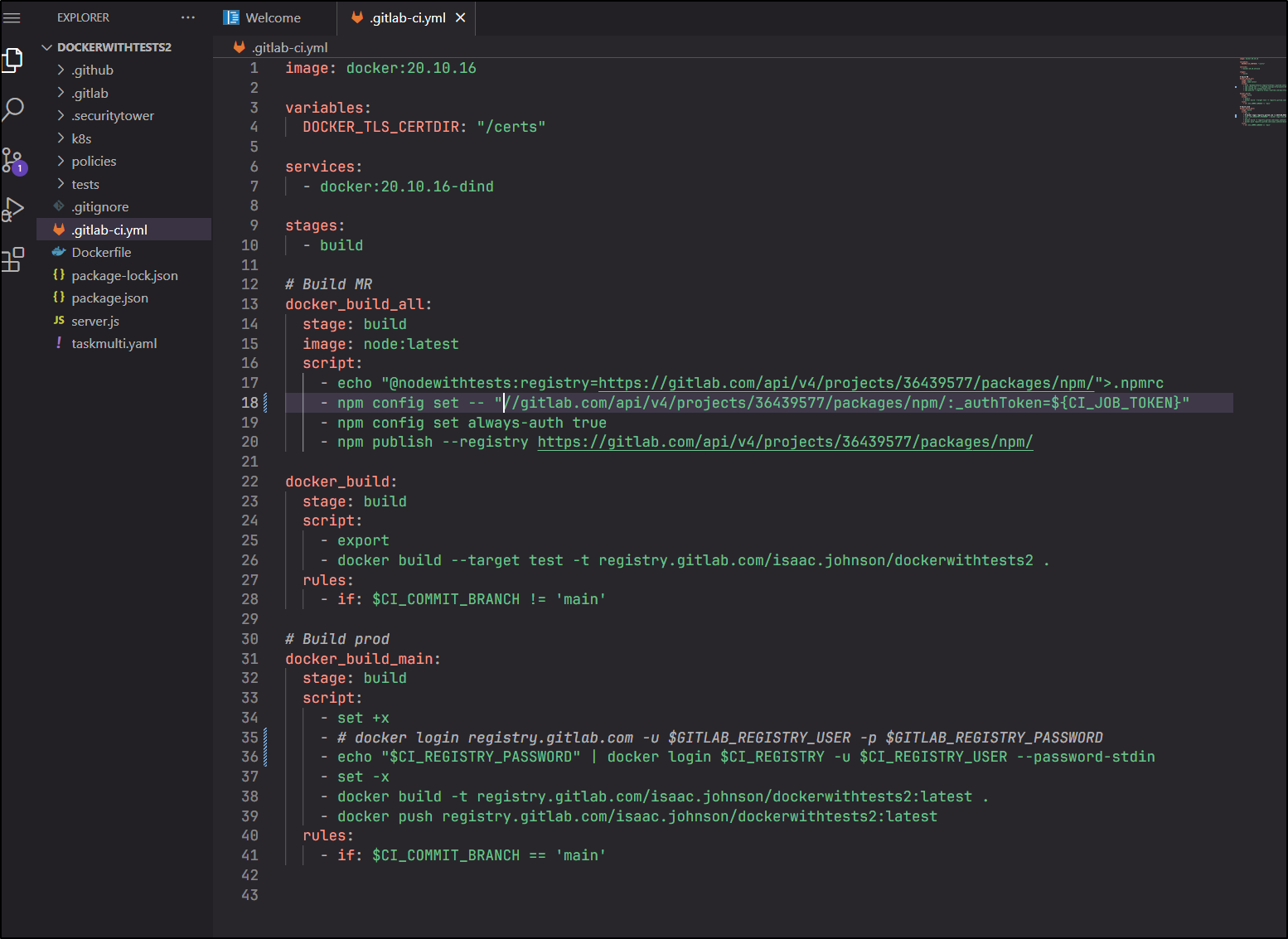
I’ll try pushing to main
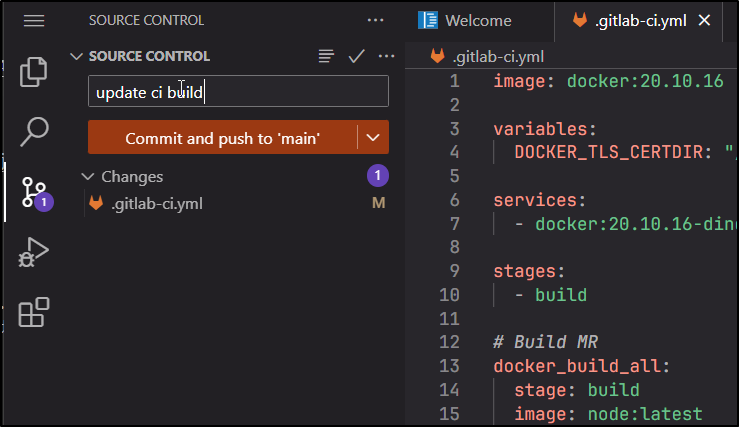
It didn’t like the comment line, so I removed it. Then it started a build
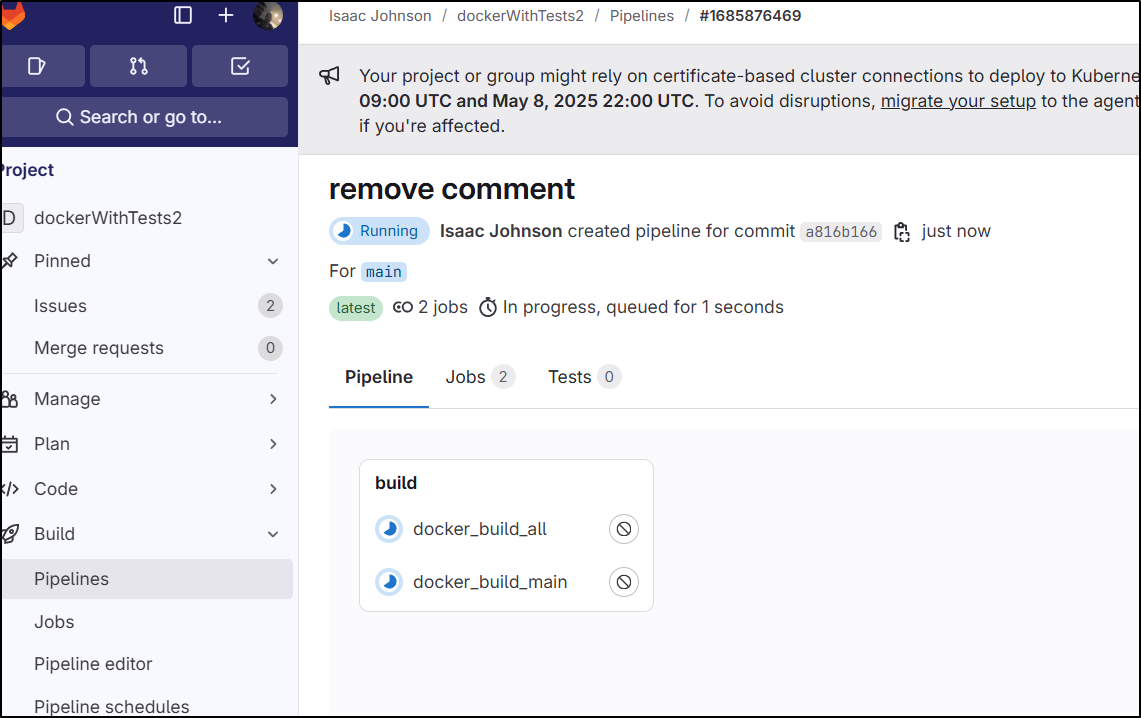
This fixed the docker_build_main block
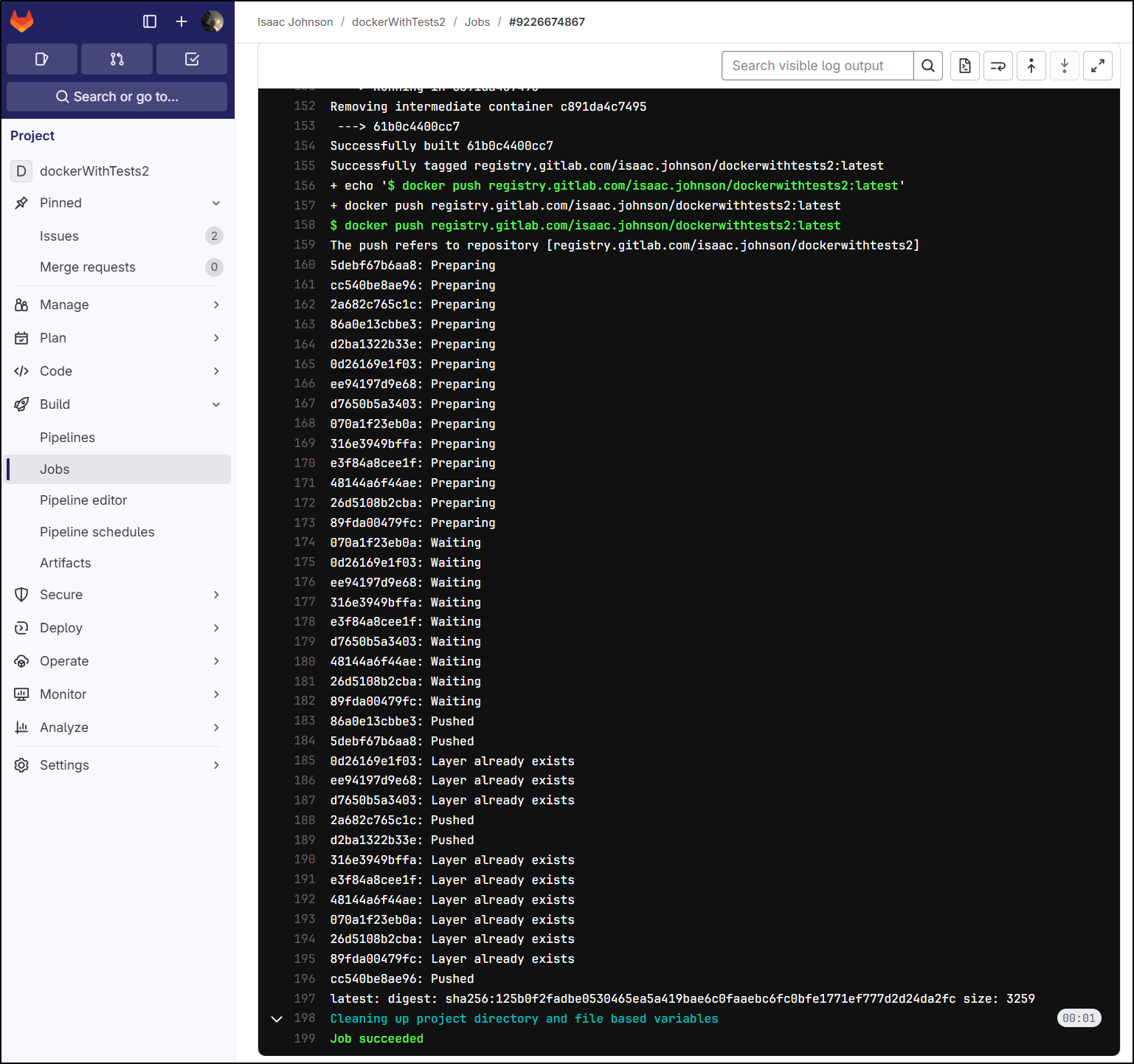
But not the always-auth in the docker build all
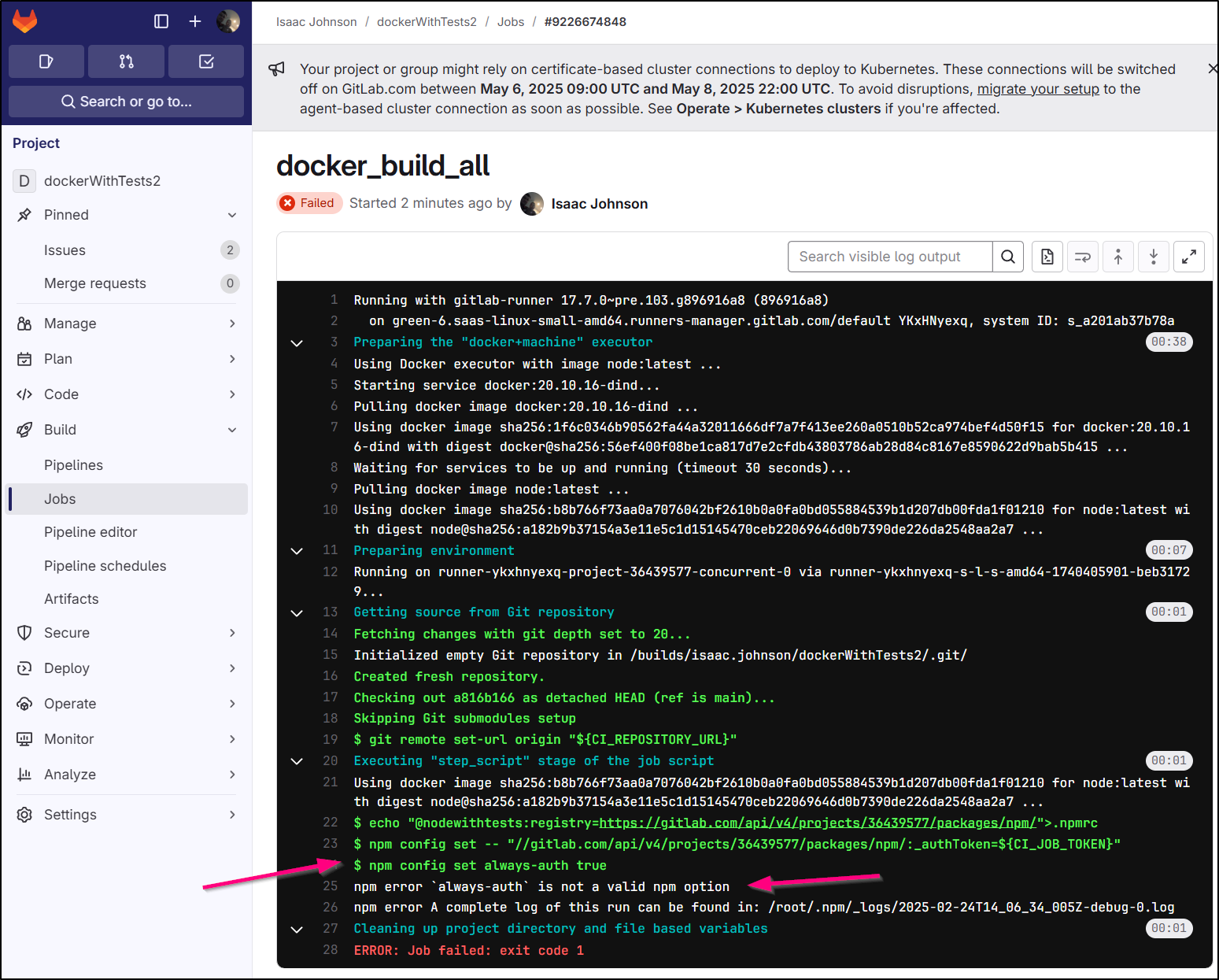
I actually had to iterate this a few times to get it fixed
I needed to tweak how we set npm to auth and then also auto-increment the package version (as they are immutable)
image: docker:20.10.16
variables:
DOCKER_TLS_CERTDIR: "/certs"
services:
- docker:20.10.16-dind
stages:
- build
# Build MR
docker_build_all:
stage: build
image: node:latest
script:
- current_version=$(node -p "require('./package.json').version")
- build_number=$CI_PIPELINE_IID
- new_version="${current_version}-build.${build_number}"
- echo "${new_version}"
- npm version "${new_version}" --no-git-tag-version
- cat package.json
- echo "@nodewithtests:registry=https://gitlab.com/api/v4/projects/36439577/packages/npm/">.npmrc
- echo "//gitlab.com/api/v4/projects/36439577/packages/npm/:_authToken=\"${CI_JOB_TOKEN}\"">>.npmrc
- npm config set @nodewithtests:registry=https://gitlab.com/api/v4/projects/36439577/packages/npm/
- npm publish --registry https://gitlab.com/api/v4/projects/36439577/packages/npm/
docker_build:
stage: build
script:
- export
- docker build --target test -t registry.gitlab.com/isaac.johnson/dockerwithtests2 .
rules:
- if: $CI_COMMIT_BRANCH != 'main'
# Build prod
docker_build_main:
stage: build
script:
- set +x
- echo "$CI_REGISTRY_PASSWORD" | docker login $CI_REGISTRY -u $CI_REGISTRY_USER --password-stdin
- set -x
- docker build -t registry.gitlab.com/isaac.johnson/dockerwithtests2:latest .
- docker push registry.gitlab.com/isaac.johnson/dockerwithtests2:latest
rules:
- if: $CI_COMMIT_BRANCH == 'main'
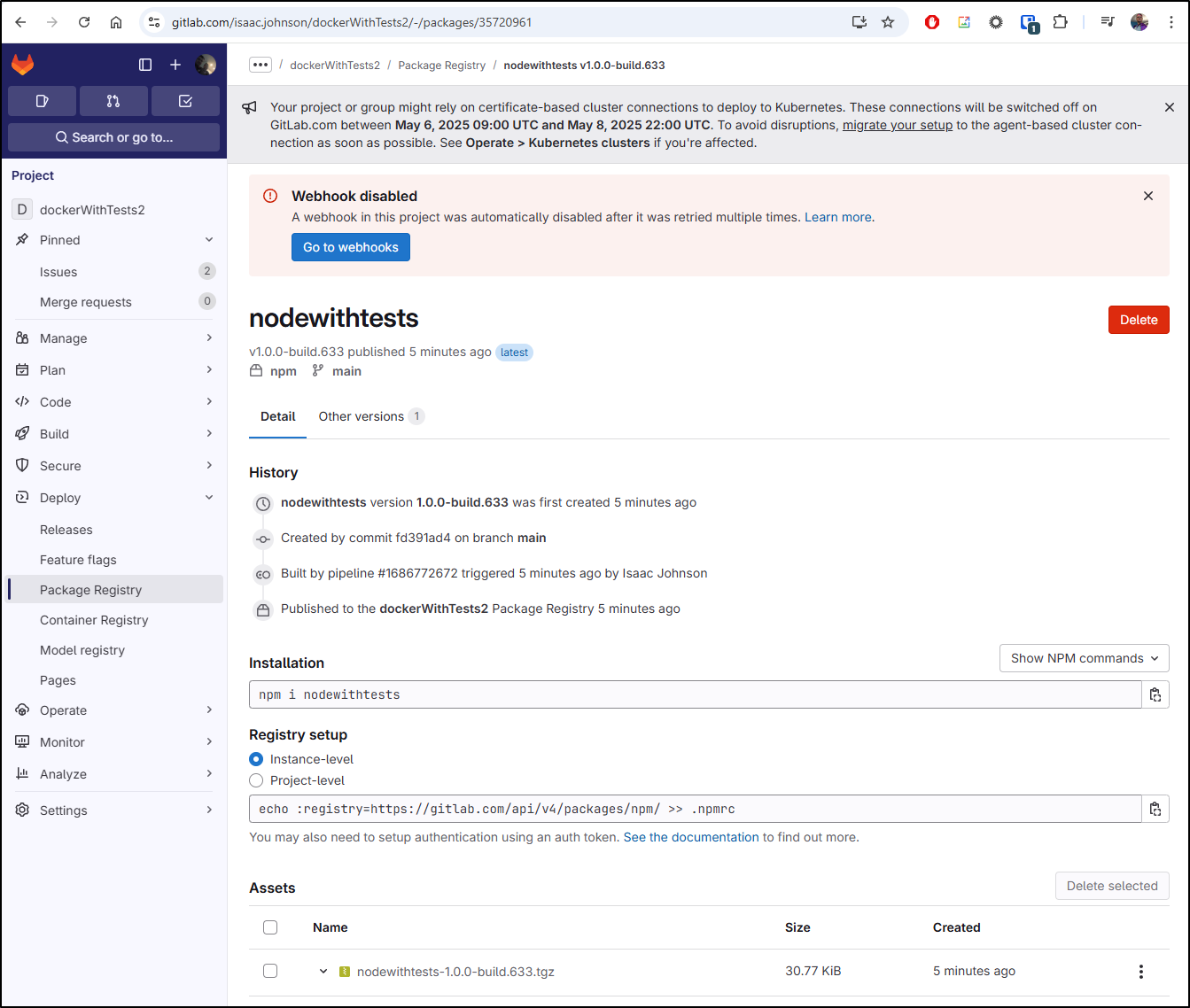
If I go to my package registry, I can see this latest package
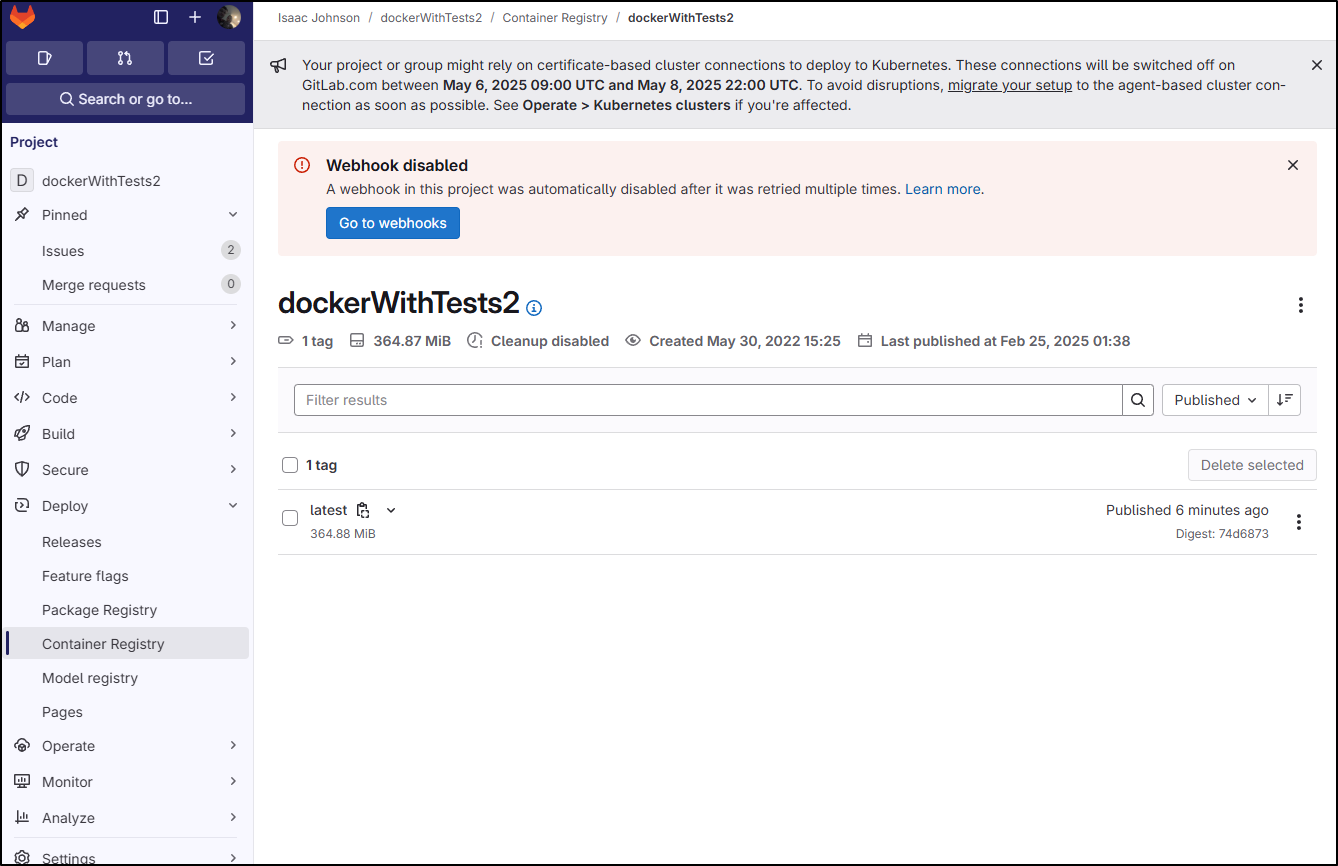
And while we see the container was first created in 2022, the latest image just happened
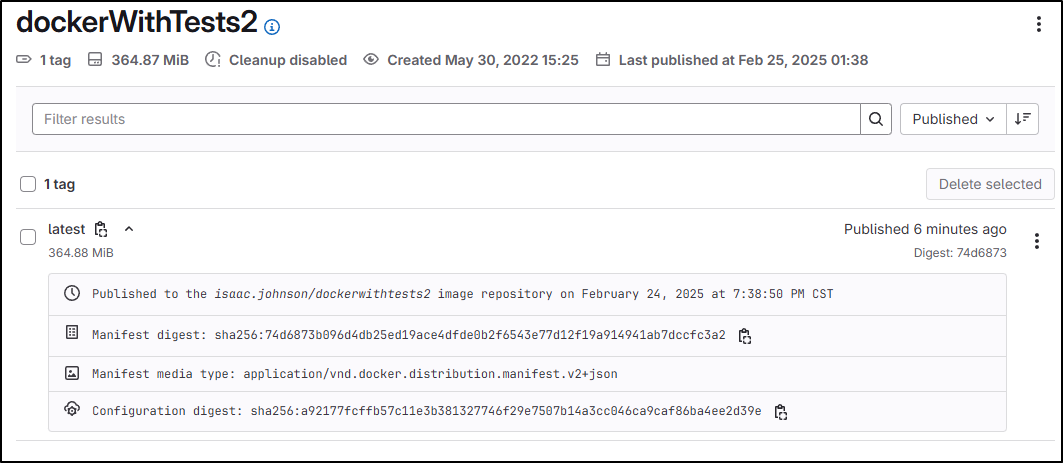
And I can expand the image details to see more
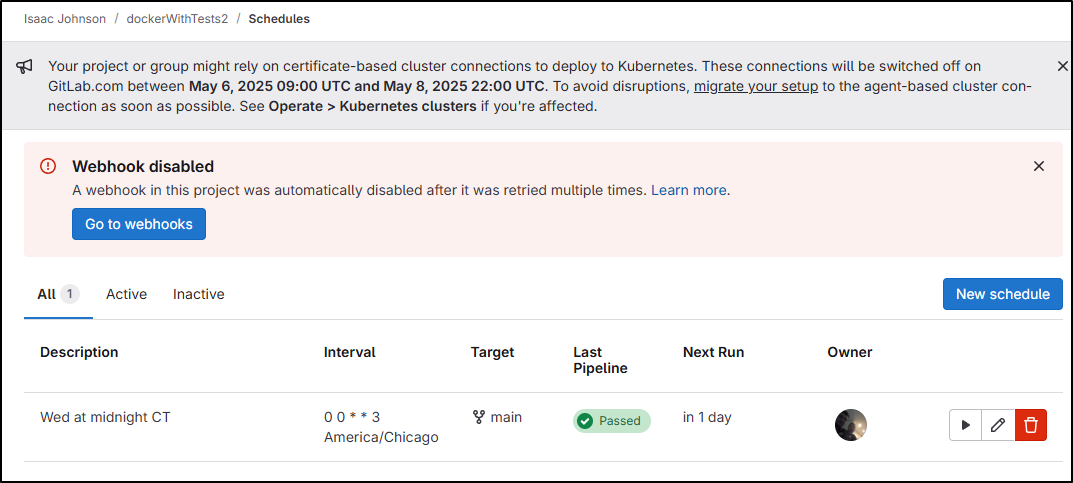
Trimming my Gitlab schedule
This has built daily for 3 years and that’s using cycles of Gitlab I really don’t need to:
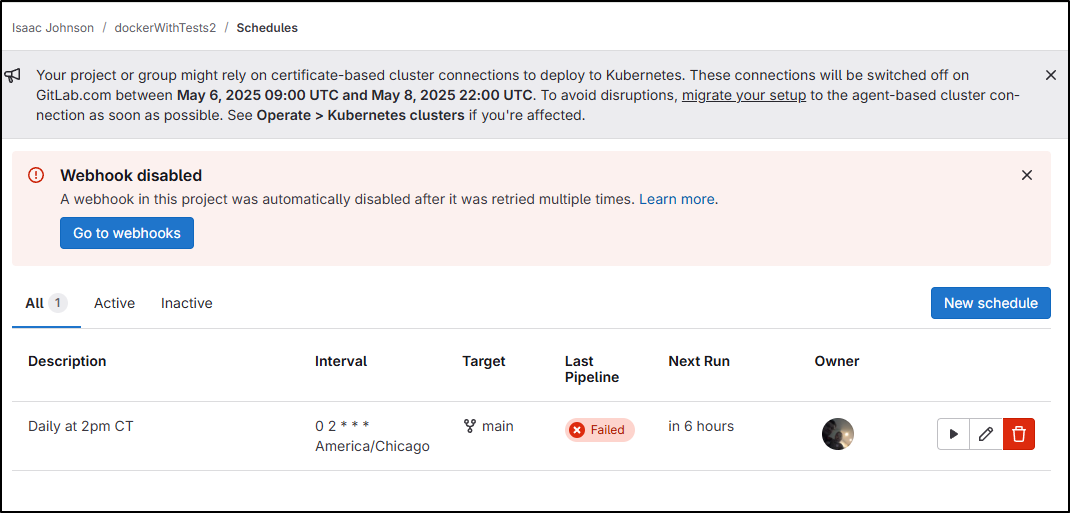
I’ll change it to be midnight on Wednesdays to reduce usage
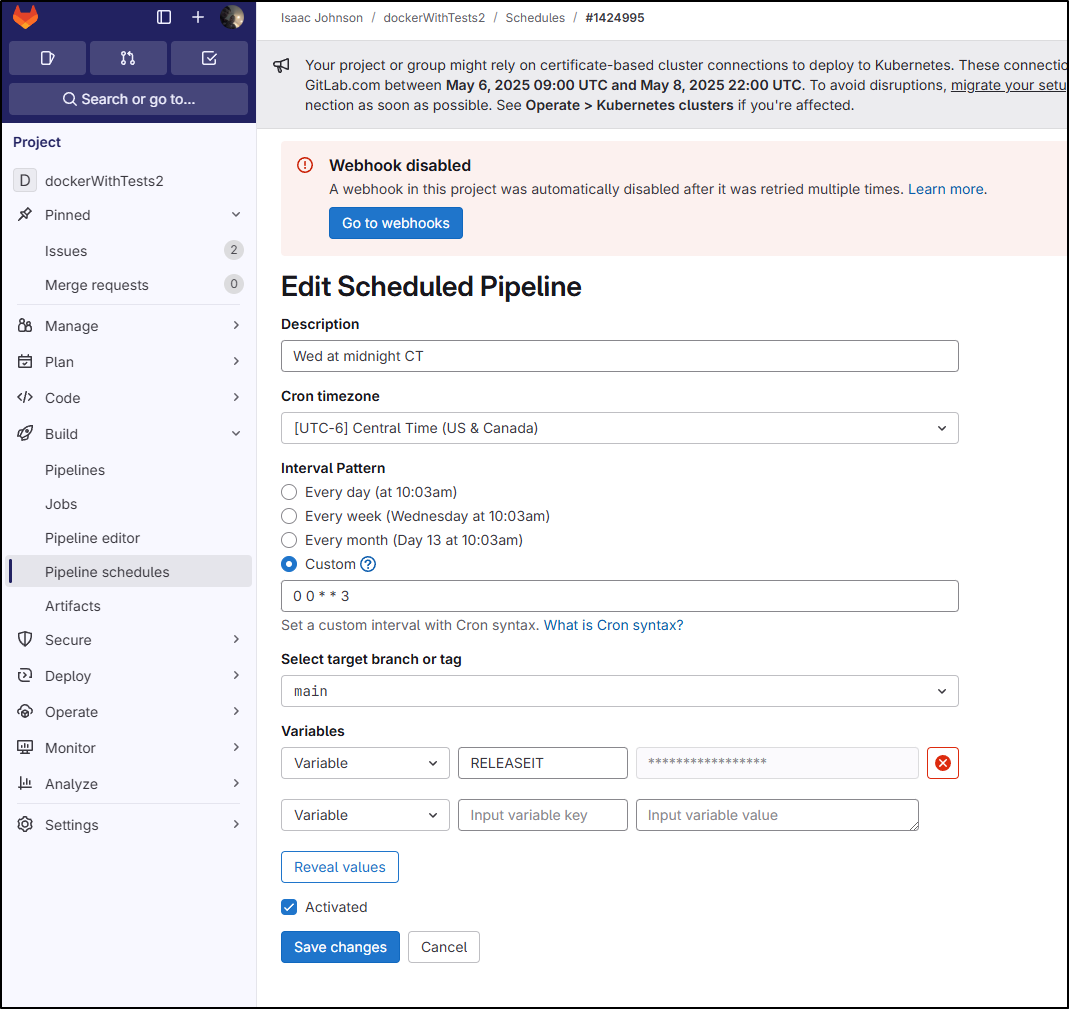
Though I don’t like seeing a Failed build indicator, so I can run a scheduled build
And it’s running
Now I can see it passed so our scheduled job is now showing green/good:
Backing up private GIT Repos
One thing I like to periodically do is setup my private repos to sync out to a secondary or even tertiary location for DR.
Recently, for another post that will happen later this month, I’ve been working on building out a Flask app base - something I could use as a base for a multitude of apps.
I’ve been using my Forgejo instance for this
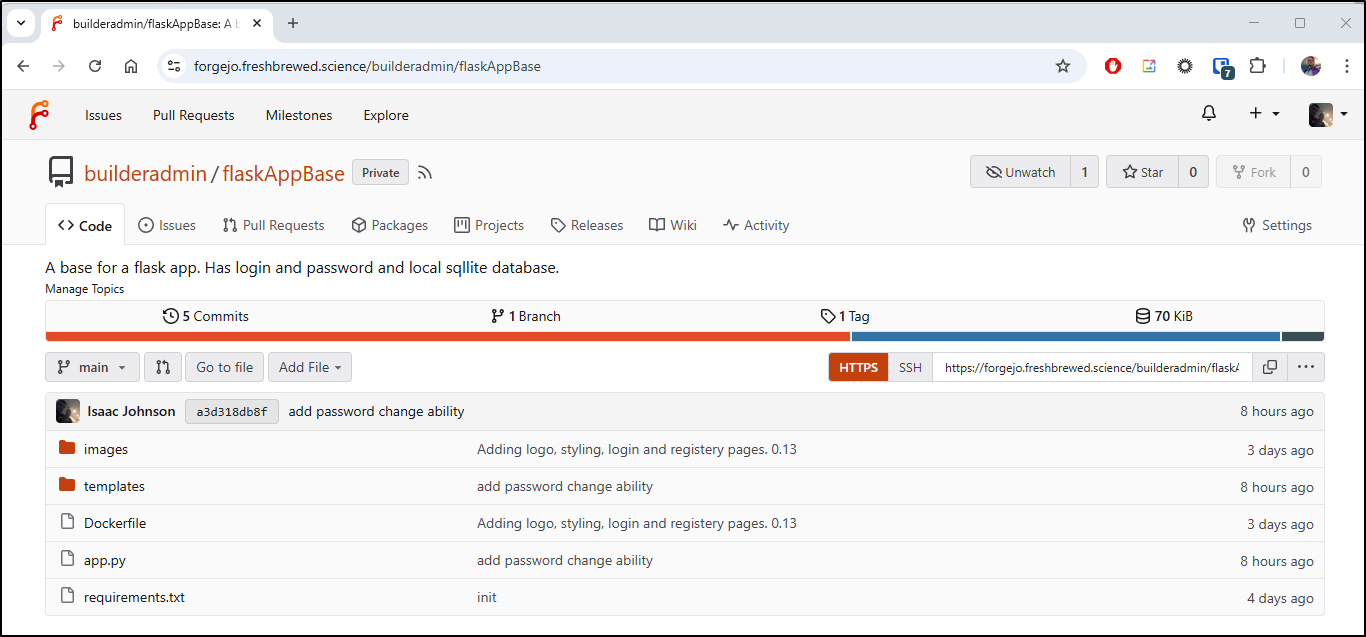
However, I have no Mirrors setup as we can see in the Repository settings

I’ll start by creating a new repo in my Gitea instance
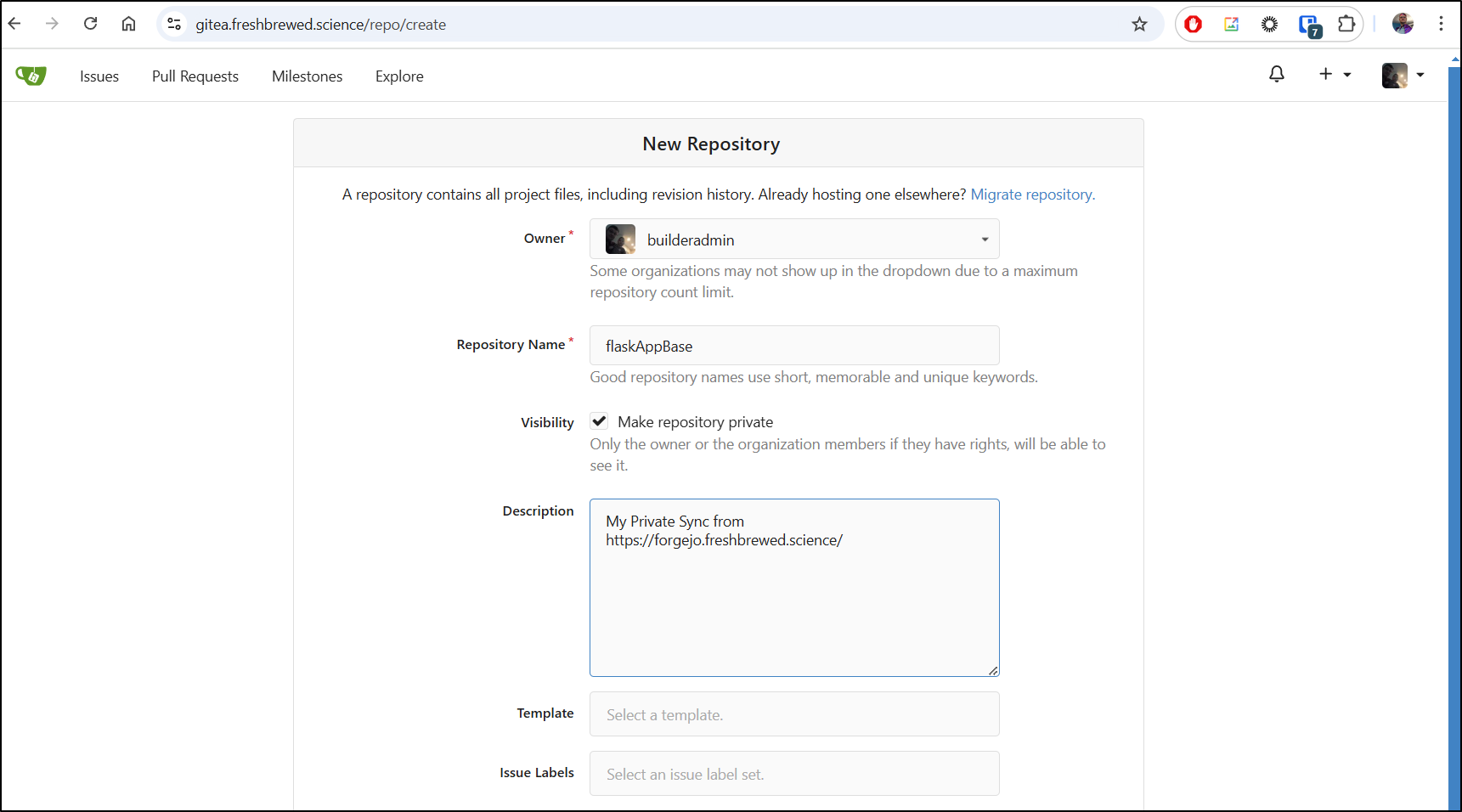
making sure to not initialize it
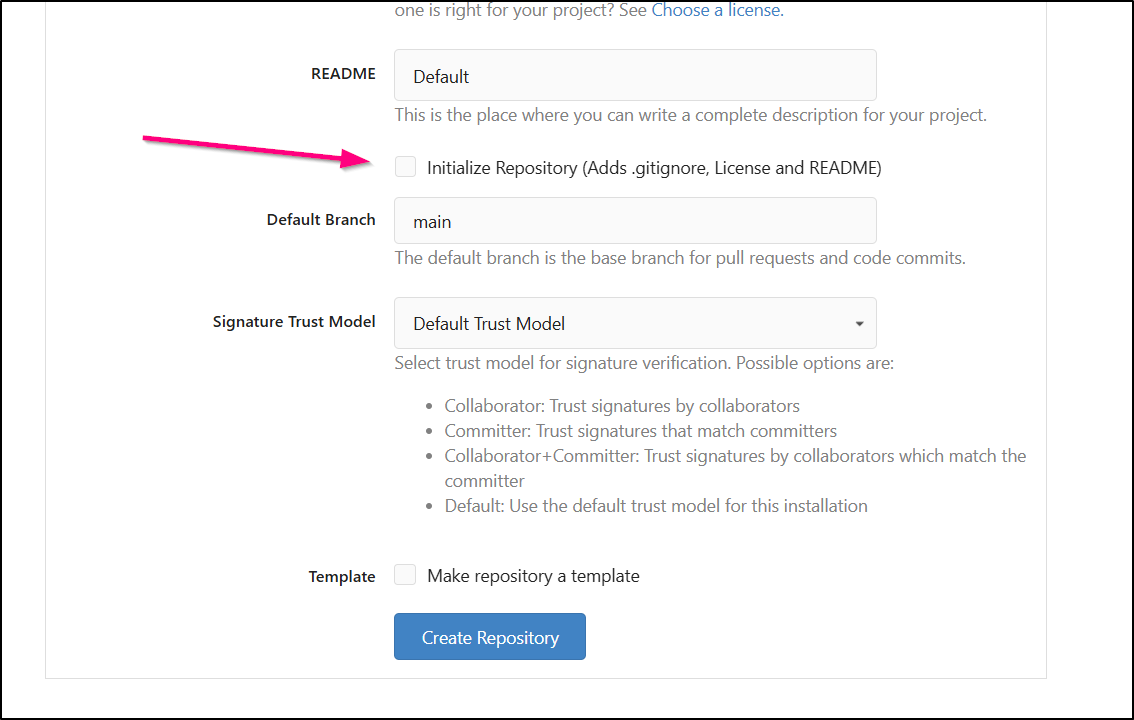
I can now see the steps to publish to it after I clicked create
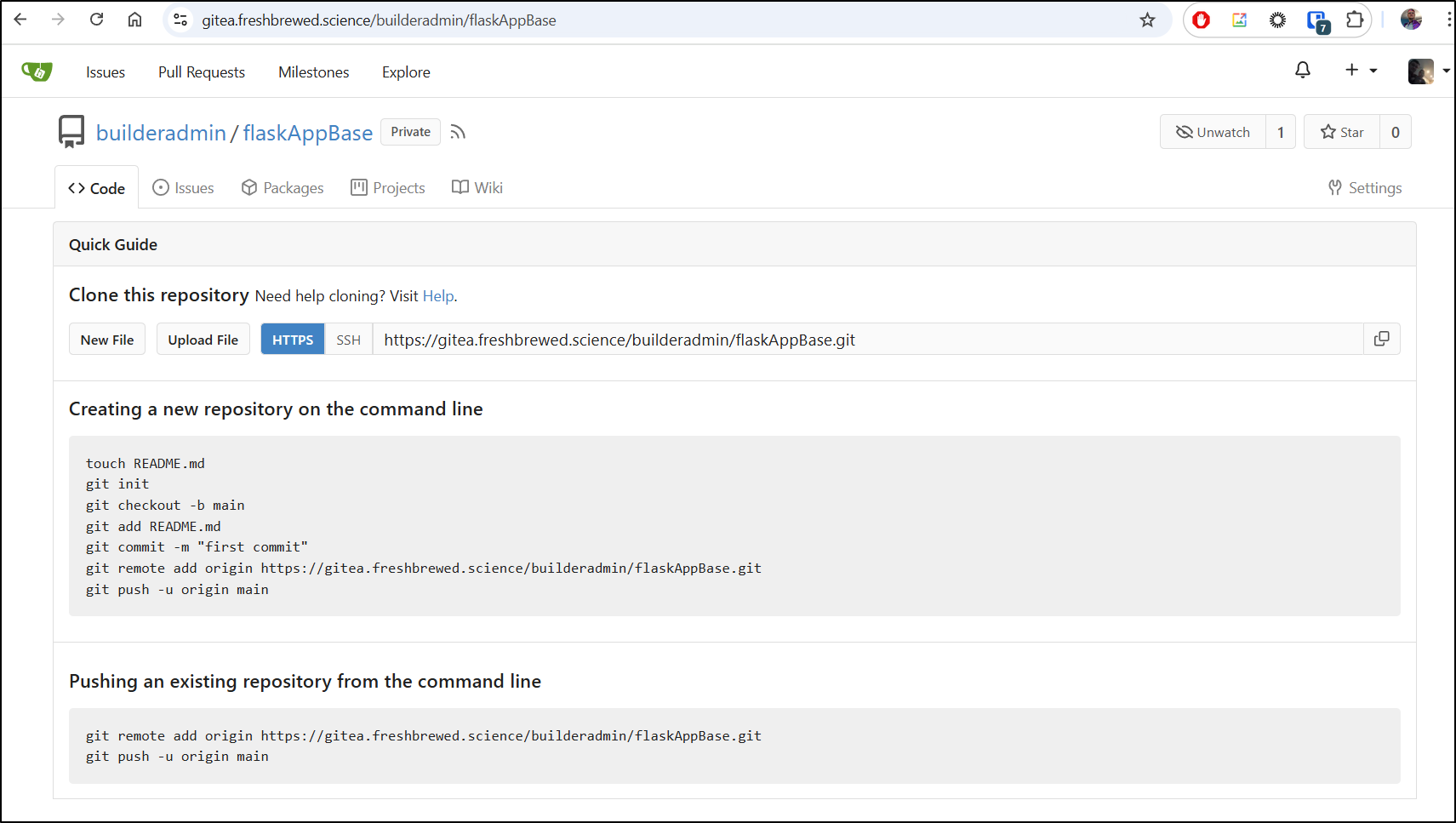
Now in Forgejo, I add the Push settings
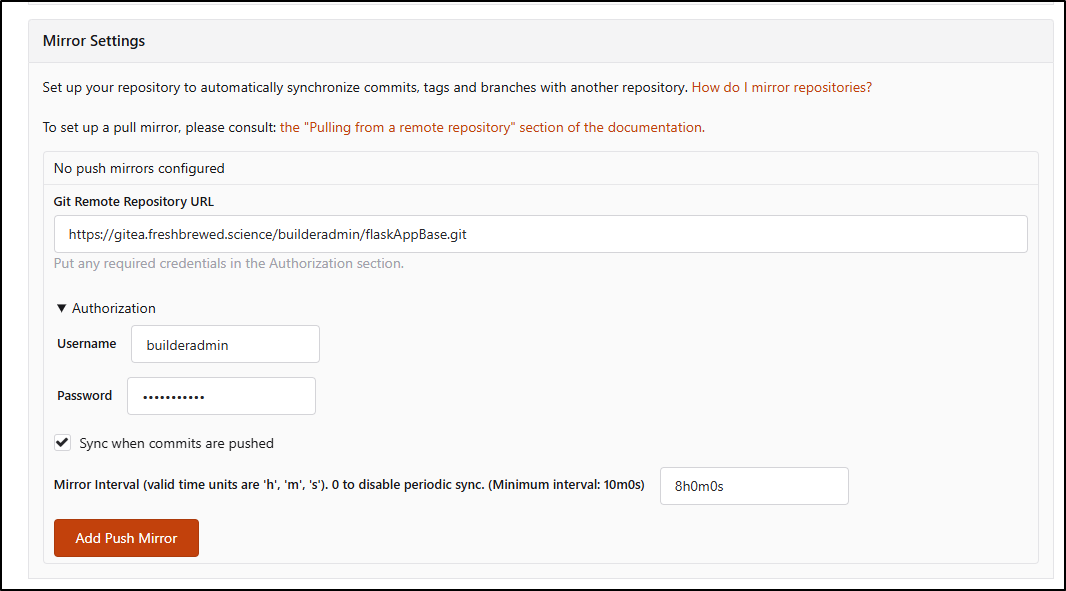
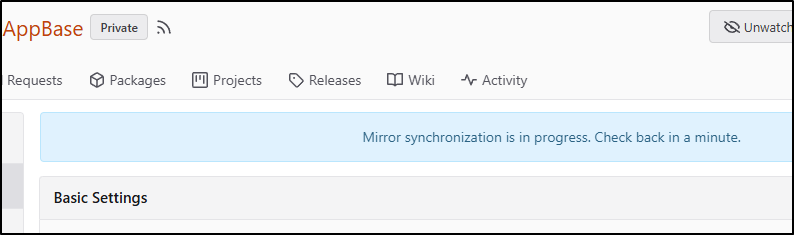
Once added, I can click Sync to create an initial sync (and verify connectivity)

A subtle blue box shows up to indicate it’s trying to push
However, a quick refresh shows it indeed pushed to Gitea
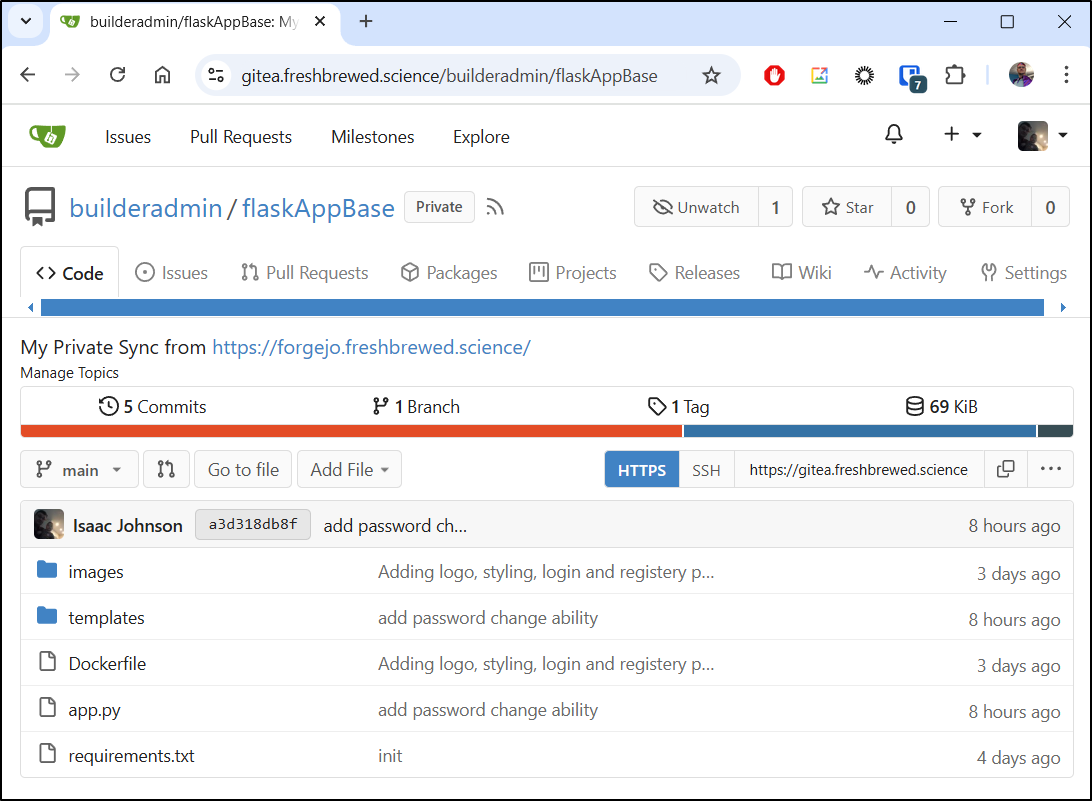
But what happens if we break other repos. Say, for instance, I completely forgot my password, reset it then realized other repos were using that former account
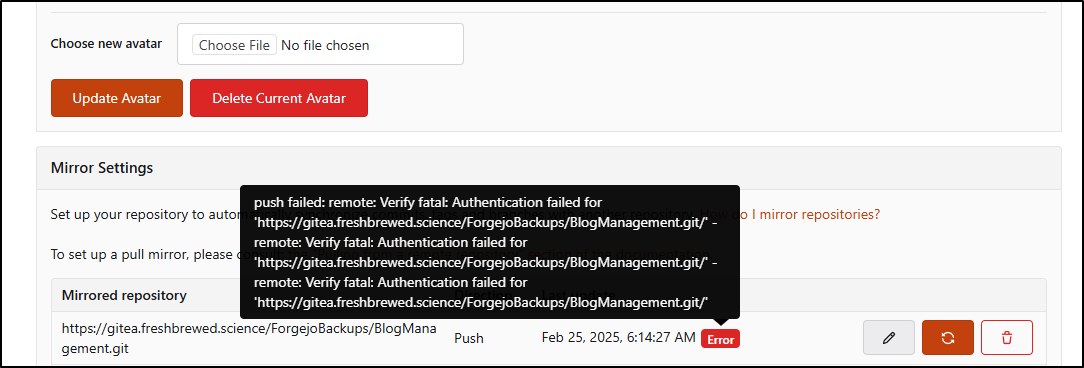
It’s actually really easy to fix:
Backing up Github
First, let me be clear and say I like Github, I use Github and I highly doubt they are going to drop repos or free tier support.
But years ago I would have said the same of Flickr and Google Code. Let’s just be a bit safe on, frankly, where most of my writing has gone for 6+ years and get a copy locally.
I’ll create a “New Migration” in Forgejo
I’ll pick Github from the next page

I now need to enter my URL and a valid GH PAT that can clone it
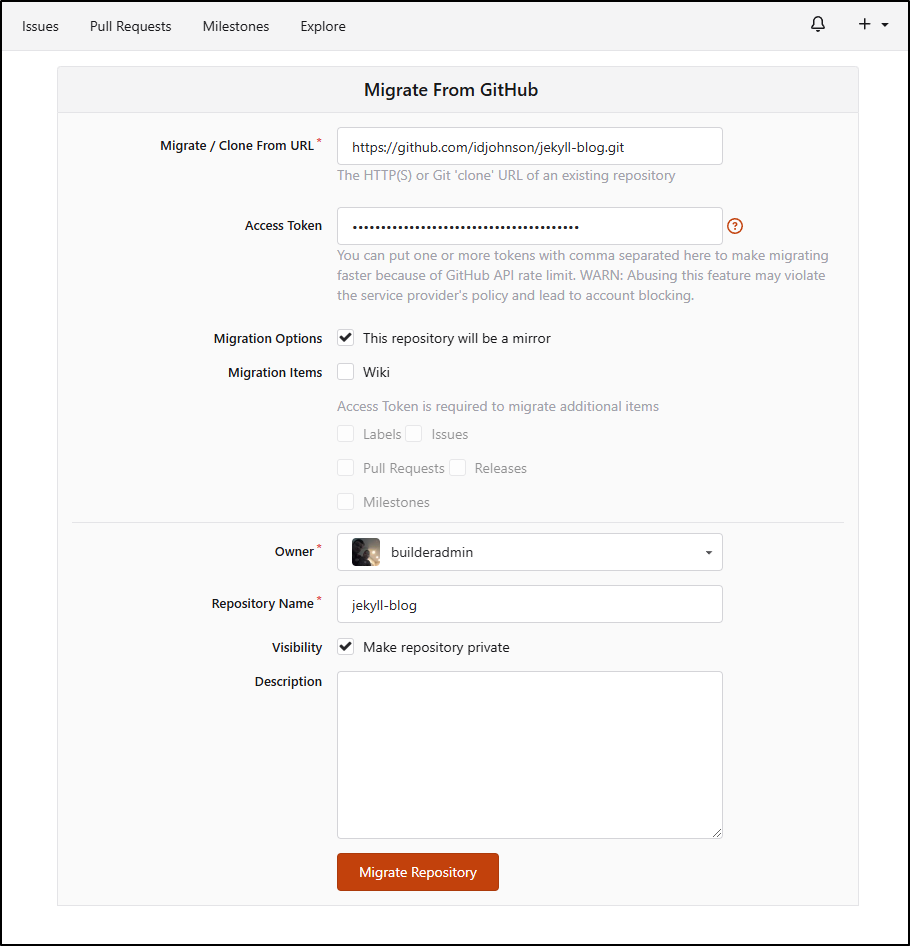
This is a huge repo (nearly 10Gb expanded) so I’ll check back on this in a bit

Surprisingly, when synced it was just 4.1Gb on disk
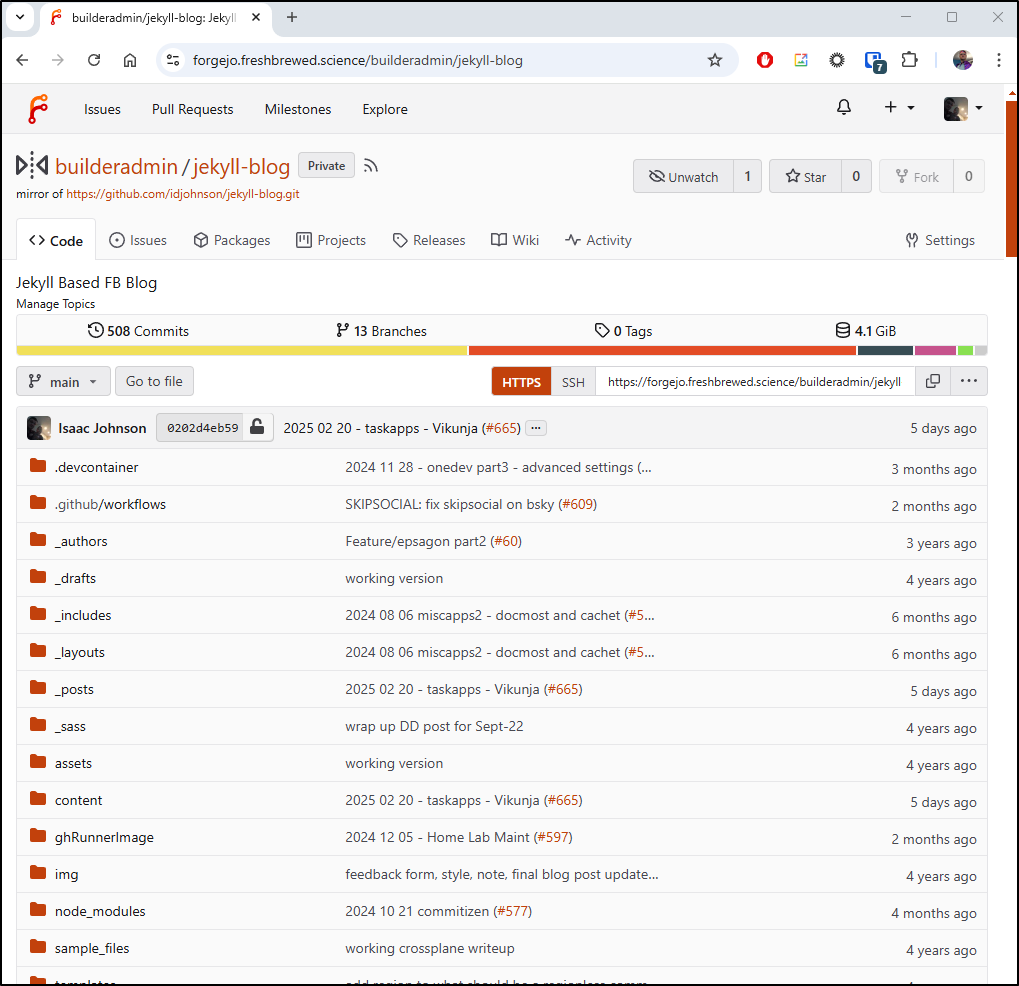
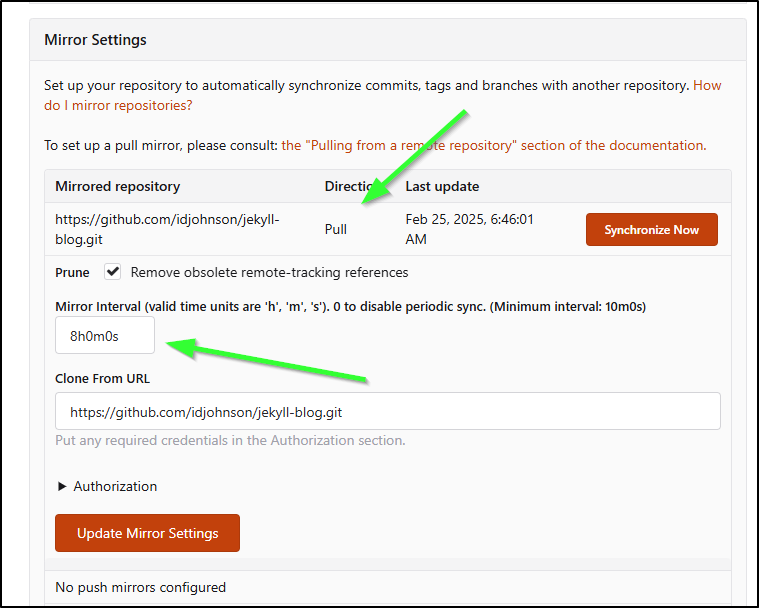
In Mirror settings, we can see the direction is set to pull and to do it every 8h
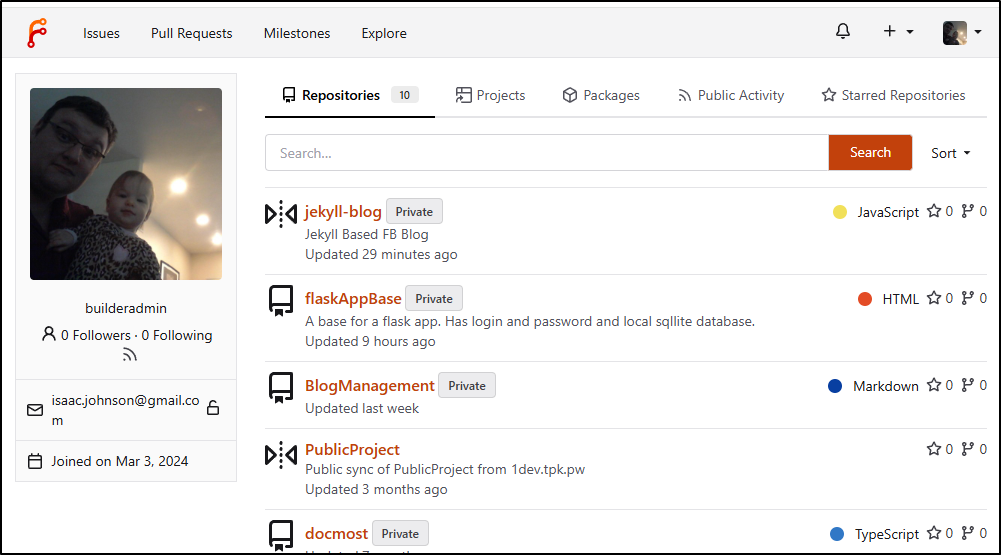
When viewing Repositories in Forgejo, the “Pull” ones have a different icon making it clear that they are sync repos
NAS reboots
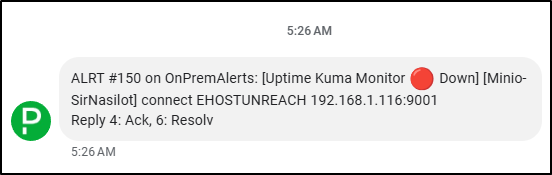
I was eating breakfast when Pagerduty went off
Logging into my Uptime Kuma instance, I could see it was about that time my newer NAS, Sir Nasilot went down - at least for Minio
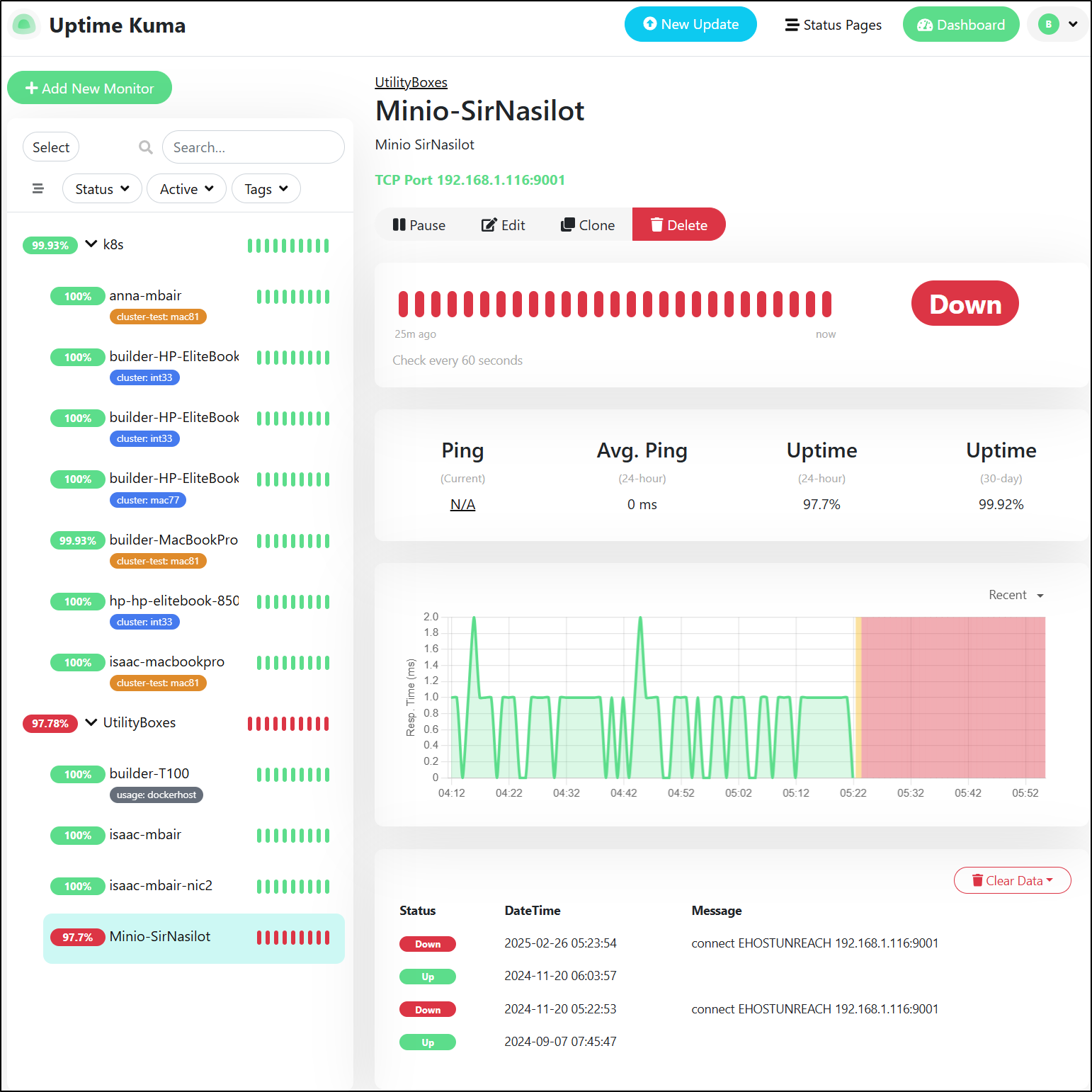
Indeed, it seems to have rebooted for some reason at around 5:20a
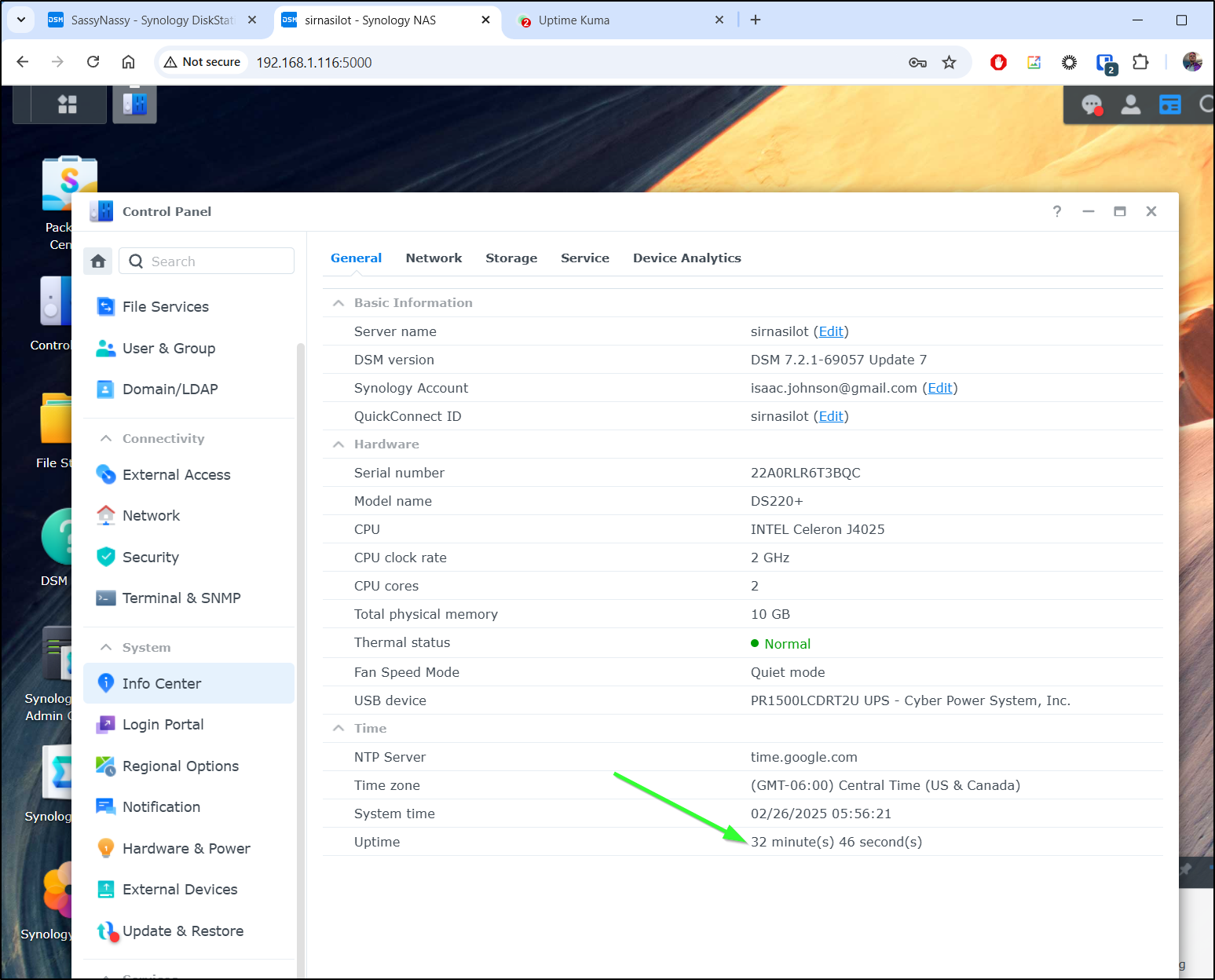
I had to refresh my memory by looking at the blog post where I launched Minio on that NAS, but the last time I basically did:
ijohnson@sirnasilot:~/minio/docs/orchestration/docker-compose$ sudo docker-compose up
First, I logged in to the NAS via SSH and checked uptime.
builder@DESKTOP-QADGF36:~$ ssh ijohnson@192.168.1.116
ijohnson@192.168.1.116's password:
Using terminal commands to modify system configs, execute external binary
files, add files, or install unauthorized third-party apps may lead to system
damages or unexpected behavior, or cause data loss. Make sure you are aware of
the consequences of each command and proceed at your own risk.
Warning: Data should only be stored in shared folders. Data stored elsewhere
may be deleted when the system is updated/restarted.
ijohnson@sirnasilot:~$ uptime
06:01:10 up 37 min, 1 user, load average: 2.04, 1.94, 1.85 [IO: 1.63, 1.32, 1.16 CPU: 0.50, 0.63, 0.66]
As expected, it had restarted. I quick checked my Minio drives were still in tackt
ijohnson@sirnasilot:~/minio/docs/orchestration/docker-compose$ sudo ls /volume1/minio/
data1 data1-1 data1-2 data2 data2-1 data2-2 data3-1 data3-2 data4-1 data4-2 drive1 drive2
I’m going to try to fix this for next time by adding a restart: always to the minio service common block
version: '3.7'
# Settings and configurations that are common for all containers
x-minio-common: &minio-common
image: quay.io/minio/minio:RELEASE.2024-08-29T01-40-52Z
command: server --console-address ":9001" http://minio{1...4}/data{1...2}
restart: always
Then launching
ijohnson@sirnasilot:~/minio/docs/orchestration/docker-compose$ sudo docker-compose up -d
[+] Running 0/4
⠼ Container docker-compose-minio1-1 Recreate 20.5s
⠼ Container docker-compose-minio2-1 Recreate 20.5s
⠼ Container docker-compose-minio4-1 Recreate 20.5s
⠼ Container docker-compose-minio3-1 Recreate 20.5s
It took a beat but they start to all restart
ijohnson@sirnasilot:~/minio/docs/orchestration/docker-compose$ sudo docker-compose up -d
[+] Running 1/5
⠿ Container docker-compose-minio1-1 Starting 42.0s
⠿ Container docker-compose-minio2-1 Starting 42.0s
⠿ Container docker-compose-minio4-1 Starting 42.0s
⠿ Container docker-compose-minio3-1 Starting 42.0s
⠿ Container docker-compose-nginx-1 Recreated 3.1s
and running

I was going to go down the path of setting up new systemctl entries but I noticed on a quick check, Portainer came back on automatically so I must have docker set to automatically start already.
Heading back to Uptime, I can see it’s happy again
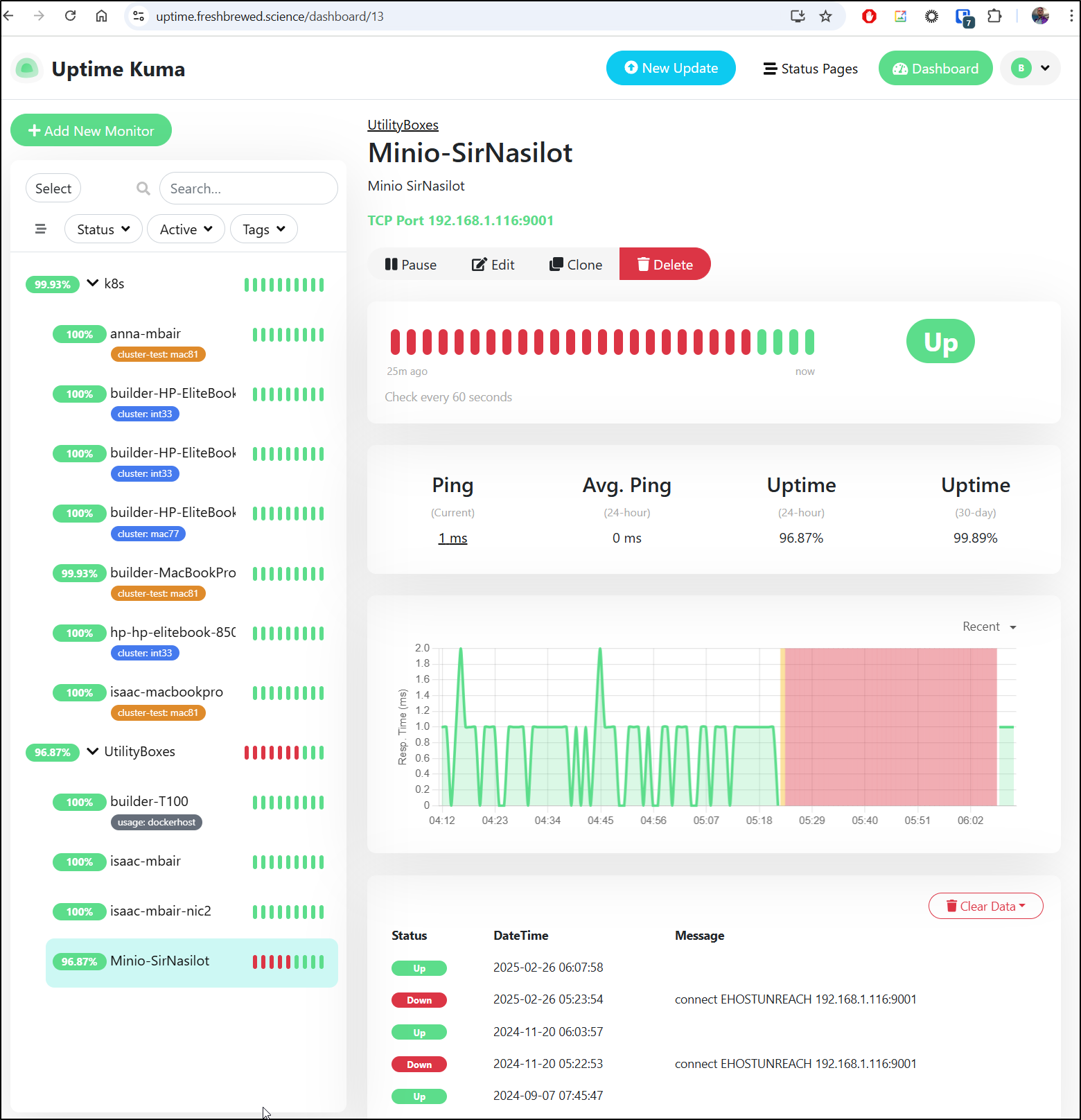
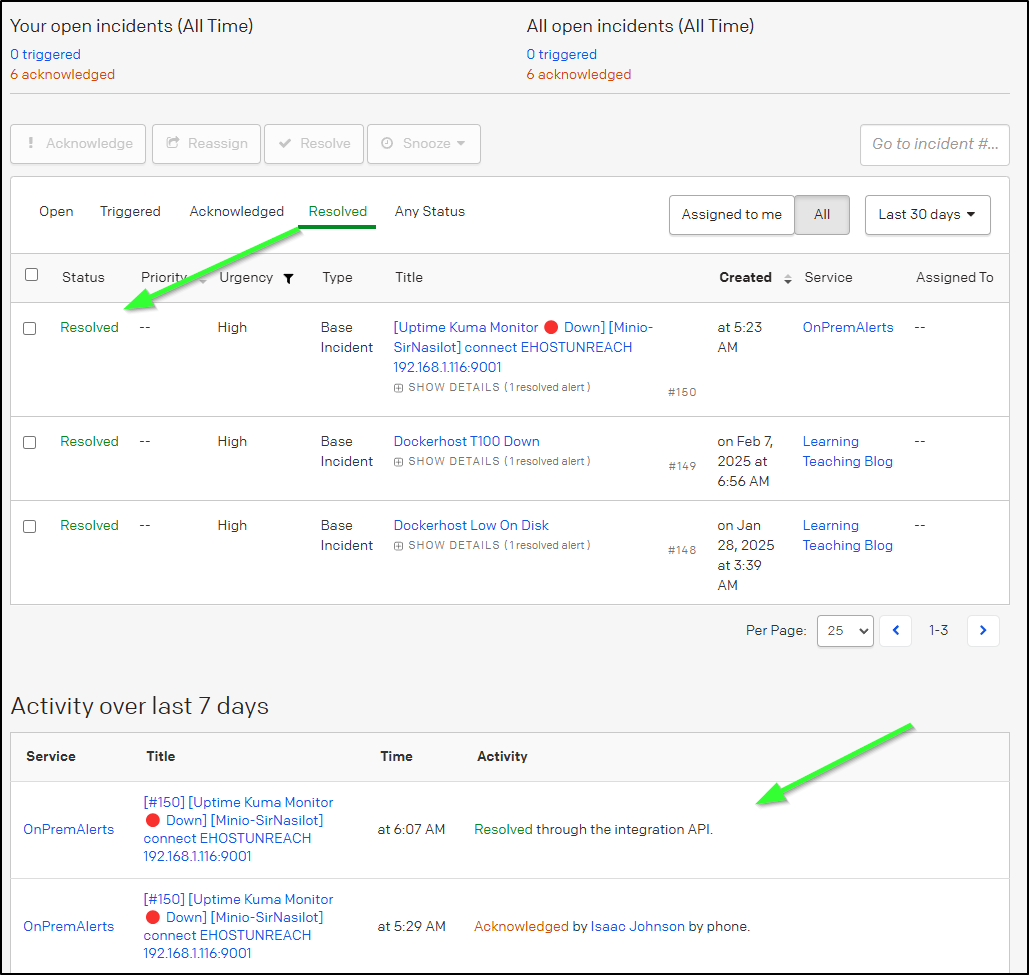
Lastly, like any good SRE, I’ll head to PD and resolve the incident…
Only I saw that Uptime Kuma Auto-resolved it already!
Just to wrap this up, I lastly wanted to figure out why my NAS restarted (SREs always end with an RCA).
The Log Center showed that, indeed, an update was pushed the NAS restarted itself
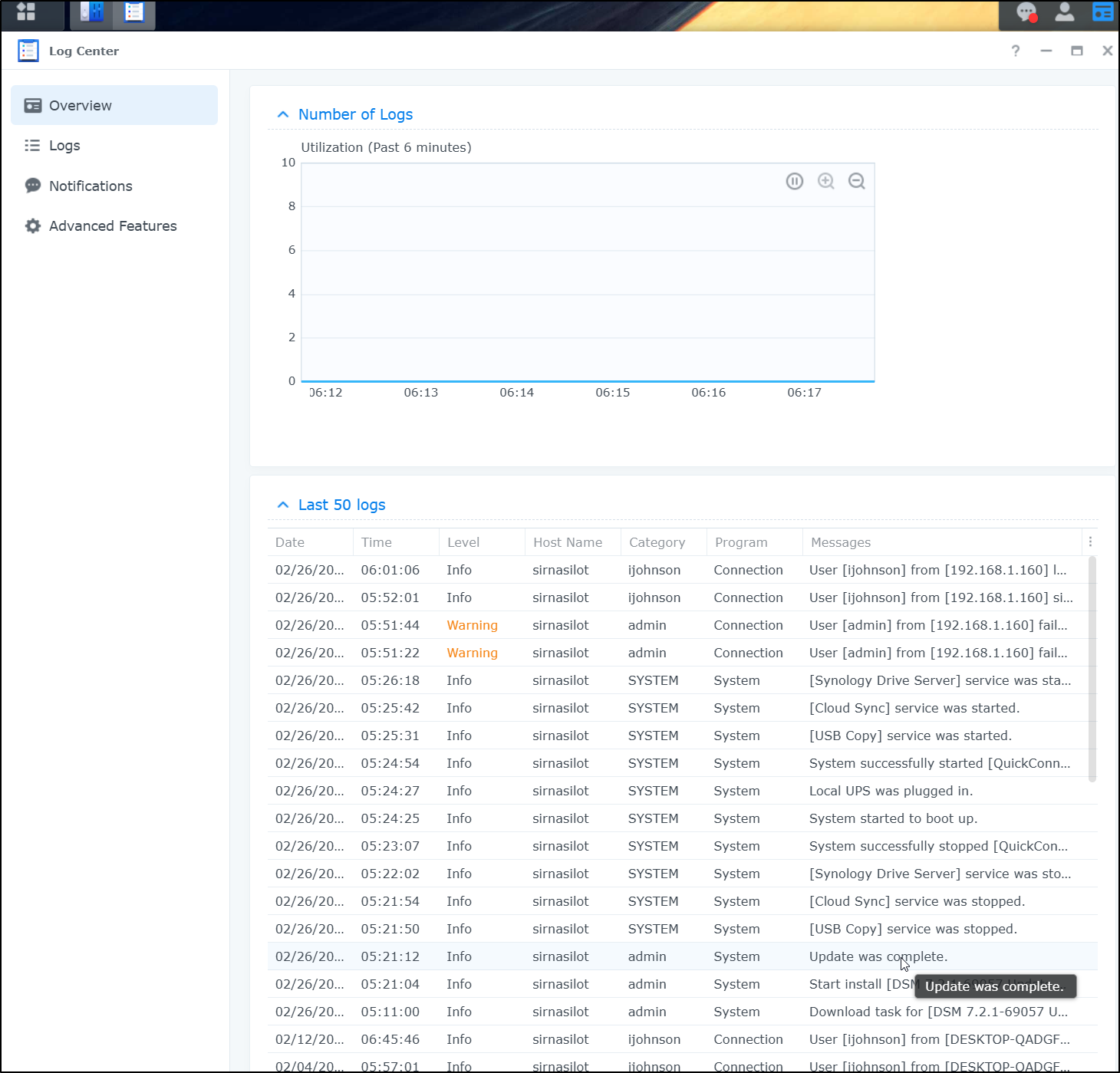
I knew I had an update queued for a long time but it was mostly because I wasn’t keen on loosing Plex which was getting removed.
Rancher Cluster Credentials Expiring
Only this afternoon, while testing, I found my Kubernetes cluster was unavailable.
builder@DESKTOP-QADGF36:~/Workspaces/flaskAppBase$ kubectl get po
E0301 15:26:09.133587 76894 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
E0301 15:26:09.136020 76894 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
E0301 15:26:09.138572 76894 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
E0301 15:26:09.141218 76894 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
E0301 15:26:09.143543 76894 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
error: You must be logged in to the server (the server has asked for the client to provide credentials)
My first step was to check Uptime Kuma, but all was well
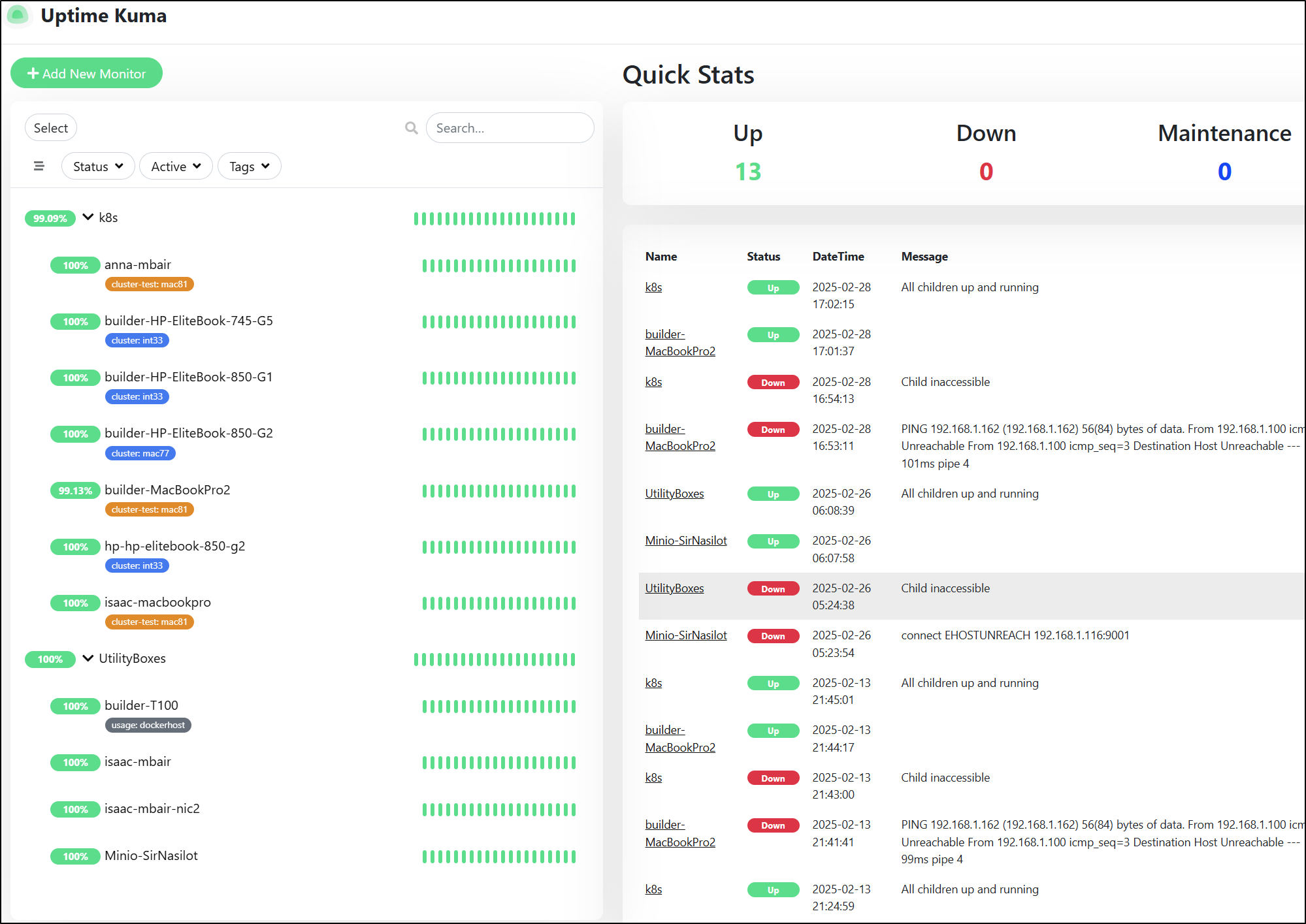
I SSH’ed to the box and it took was rejecting Kubectl commands
builder@builder-HP-EliteBook-745-G5:~$ kubectl get nodes
E0301 15:28:36.005589 3210949 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
E0301 15:28:36.009744 3210949 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
E0301 15:28:36.011761 3210949 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
E0301 15:28:36.013842 3210949 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
E0301 15:28:36.015964 3210949 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
error: You must be logged in to the server (the server has asked for the client to provide credentials)
I did a stop and start of k3s and tried again
builder@builder-HP-EliteBook-745-G5:~$ sudo systemctl stop k3s
builder@builder-HP-EliteBook-745-G5:~$ sudo systemctl start k3s
builder@builder-HP-EliteBook-745-G5:~$ kubectl get nodes
E0301 15:28:33.519086 3210780 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
E0301 15:28:33.521830 3210780 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
E0301 15:28:33.524901 3210780 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
E0301 15:28:33.528266 3210780 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
E0301 15:28:33.530369 3210780 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
error: You must be logged in to the server (the server has asked for the client to provide credentials)
My last shot was to try the K3s kubeconfig explicitly
builder@builder-HP-EliteBook-745-G5:~$ kubectl get nodes --kubeconfig=/etc/rancher/k3s/k3s.yaml
NAME STATUS ROLES AGE VERSION
hp-hp-elitebook-850-g2 Ready <none> 361d v1.26.14+k3s1
builder-hp-elitebook-850-g1 Ready <none> 365d v1.26.14+k3s1
builder-hp-elitebook-745-g5 Ready control-plane,master 365d v1.26.14+k3s1
builder-hp-elitebook-850-g2 Ready <none> 222d v1.26.14+k3s1
I copied it locally and tested.
Then I needed to update my AKV so I could fix my other systems
$ az keyvault secret set --name int33-int --vault-name idjakv --subscription Pay-As-You-Go --file /home/builder/.kube/int33-config
$ az keyvault secret set --name ext33-int --vault-name idjakv --subscription Pay-As-You-Go --file /home/builder/.kube/ext33-config
Cleanup Aisle 100
Yet again, right before publishing this, I got another “Dockerhost Low on Disk” page
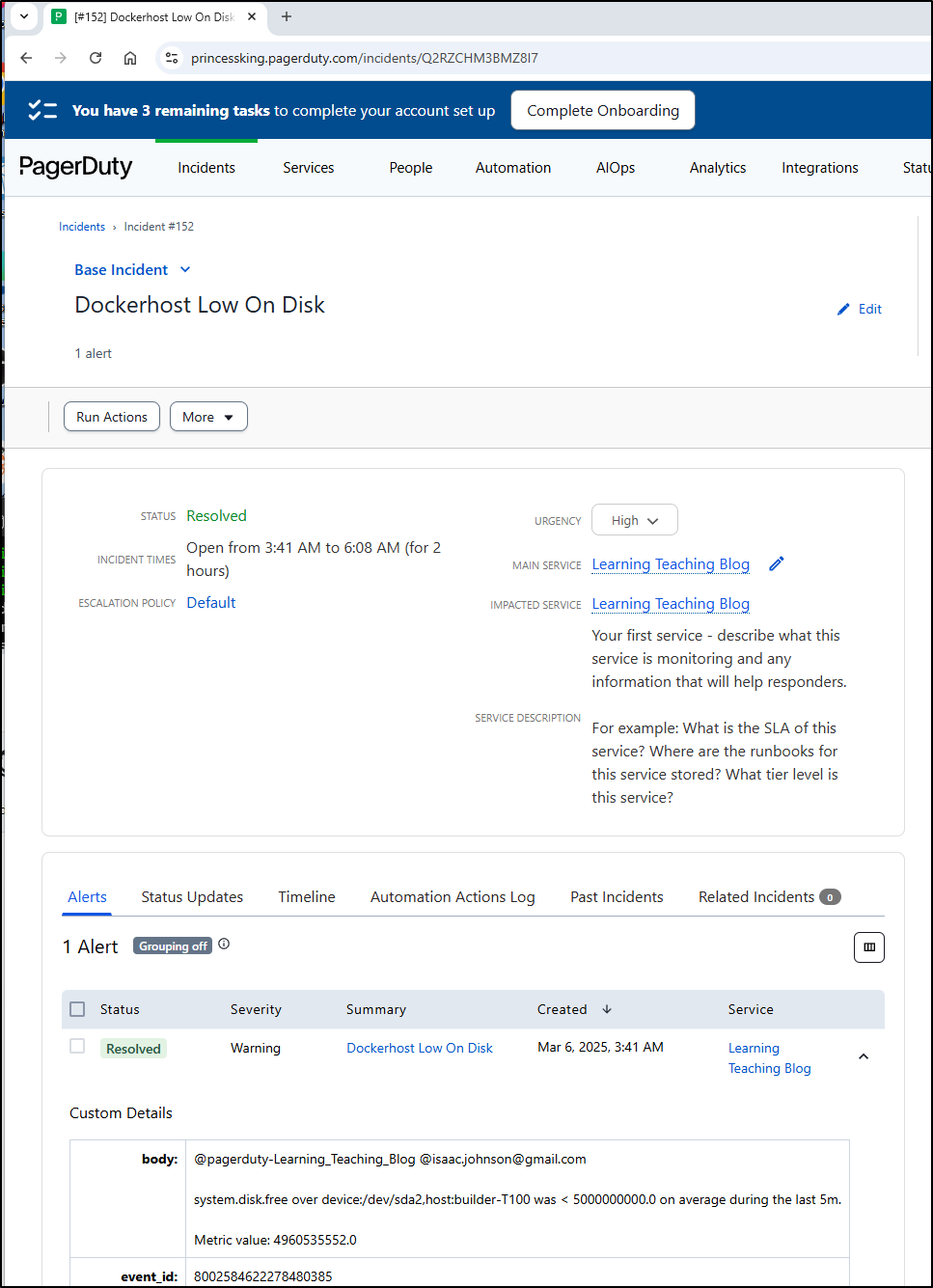
Logging in I can see it’s up to 99% again
builder@builder-T100:~$ df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 766M 4.4M 761M 1% /run
/dev/sda2 234G 218G 4.3G 99% /
tmpfs 3.8G 29M 3.8G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
efivarfs 192K 98K 90K 53% /sys/firmware/efi/efivars
/dev/sda1 511M 6.1M 505M 2% /boot/efi
192.168.1.116:/volume1/docker-filestation 8.8T 1.5T 7.4T 17% /mnt/filestation
192.168.1.116:/volume1/k3sPrimary01 8.8T 1.5T 7.4T 17% /mnt/sirnasilotk3sprimary01
192.168.1.129:/volume1/linuxbackups 5.5T 2.8T 2.7T 51% /mnt/linuxbackups
192.168.1.129:/volume1/postgres-prod-dbbackups 5.5T 2.8T 2.7T 51% /mnt/psqlbackups
tmpfs 766M 112K 766M 1% /run/user/1000
shm 64M 0 64M 0% /var/snap/microk8s/common/run/containerd/io.containerd.grpc.v1.cri/sandboxes/1fcb89ed5aef602c714be9857d3c9937d3675abb5401ff4019b27489febd7e3f/shm
shm 64M 0 64M 0% /var/snap/microk8s/common/run/containerd/io.containerd.grpc.v1.cri/sandboxes/d463eedcd95a6403a5562538d4fb5fd129413091fda302f21397e2180bc5a42f/shm
shm 64M 0 64M 0% /var/snap/microk8s/common/run/containerd/io.containerd.grpc.v1.cri/sandboxes/60cf4b31896504e82aae703bf435141218b883993cecb1ea405a504c8871793d/shm
shm 64M 0 64M 0% /var/snap/microk8s/common/run/containerd/io.containerd.grpc.v1.cri/sandboxes/b465837d18737941440ba0d6b2f5948fc4f75f8a992fa6630686aef59fda9b37/shm
shm 64M 0 64M 0% /var/snap/microk8s/common/run/containerd/io.containerd.grpc.v1.cri/sandboxes/548f92eb04ae5f05e0a8ed1526070f9745fc8d3061a091c1ce5a24f9079374bf/shm
shm 64M 0 64M 0% /var/snap/microk8s/common/run/containerd/io.containerd.grpc.v1.cri/sandboxes/8806006f967c1e0b0d16f3f072db3483f11d647c67540d689941cbfcc49bcf34/shm
shm 64M 0 64M 0% /var/snap/microk8s/common/run/containerd/io.containerd.grpc.v1.cri/sandboxes/b650bbcff28b70bfca917d14d1bcf4229086b452cca478fd0ecaffdf9f965731/shm
shm 64M 0 64M 0% /var/snap/microk8s/common/run/containerd/io.containerd.grpc.v1.cri/sandboxes/333988ab998de4528d0d4d4dd757cf74dc43fd84c88c2c13e9800bc5047401e4/shm
I know I encountered this before and indeed, looking back at old posts, I found this article from December where a backup folder had filled up.
Checking now, it again was way oversized
113G ./sirnasilot-backups
builder@builder-T100:~$ cd sirnasilot-backups/
builder@builder-T100:~/sirnasilot-backups$ ls
sirnasilot_backup_2025-01-19_03h33m.tgz sirnasilot_backup_2025-02-04_03h33m.tgz sirnasilot_backup_2025-02-20_03h33m.tgz
sirnasilot_backup_2025-01-20_03h33m.tgz sirnasilot_backup_2025-02-05_03h33m.tgz sirnasilot_backup_2025-02-21_03h33m.tgz
sirnasilot_backup_2025-01-21_03h33m.tgz sirnasilot_backup_2025-02-06_03h33m.tgz sirnasilot_backup_2025-02-22_03h33m.tgz
sirnasilot_backup_2025-01-22_03h33m.tgz sirnasilot_backup_2025-02-07_03h33m.tgz sirnasilot_backup_2025-02-23_03h33m.tgz
sirnasilot_backup_2025-01-23_03h33m.tgz sirnasilot_backup_2025-02-08_03h33m.tgz sirnasilot_backup_2025-02-24_03h33m.tgz
sirnasilot_backup_2025-01-24_03h33m.tgz sirnasilot_backup_2025-02-09_03h33m.tgz sirnasilot_backup_2025-02-25_03h33m.tgz
sirnasilot_backup_2025-01-25_03h33m.tgz sirnasilot_backup_2025-02-10_03h33m.tgz sirnasilot_backup_2025-02-26_03h33m.tgz
sirnasilot_backup_2025-01-26_03h33m.tgz sirnasilot_backup_2025-02-11_03h33m.tgz sirnasilot_backup_2025-02-27_03h33m.tgz
sirnasilot_backup_2025-01-27_03h33m.tgz sirnasilot_backup_2025-02-12_03h33m.tgz sirnasilot_backup_2025-02-28_03h33m.tgz
sirnasilot_backup_2025-01-28_03h33m.tgz sirnasilot_backup_2025-02-13_03h33m.tgz sirnasilot_backup_2025-03-01_03h33m.tgz
sirnasilot_backup_2025-01-29_03h33m.tgz sirnasilot_backup_2025-02-14_03h33m.tgz sirnasilot_backup_2025-03-02_03h33m.tgz
sirnasilot_backup_2025-01-30_03h33m.tgz sirnasilot_backup_2025-02-15_03h33m.tgz sirnasilot_backup_2025-03-03_03h33m.tgz
sirnasilot_backup_2025-01-31_03h33m.tgz sirnasilot_backup_2025-02-16_03h33m.tgz sirnasilot_backup_2025-03-04_03h33m.tgz
sirnasilot_backup_2025-02-01_03h33m.tgz sirnasilot_backup_2025-02-17_03h33m.tgz sirnasilot_backup_2025-03-05_03h33m.tgz
sirnasilot_backup_2025-02-02_03h33m.tgz sirnasilot_backup_2025-02-18_03h33m.tgz sirnasilot_backup_2025-03-06_03h33m.tgz
sirnasilot_backup_2025-02-03_03h33m.tgz sirnasilot_backup_2025-02-19_03h33m.tgz
Running the find command in the crontab worked
builder@builder-T100:~/sirnasilot-backups$ find /home/builder/sirnasilot-backups -type f -printf '%T@ %p\n' | sort -n | head -n -10 | cut -d' ' -f2- | xargs rm -f
builder@builder-T100:~/sirnasilot-backups$ ls
sirnasilot_backup_2025-02-25_03h33m.tgz sirnasilot_backup_2025-03-01_03h33m.tgz sirnasilot_backup_2025-03-05_03h33m.tgz
sirnasilot_backup_2025-02-26_03h33m.tgz sirnasilot_backup_2025-03-02_03h33m.tgz sirnasilot_backup_2025-03-06_03h33m.tgz
sirnasilot_backup_2025-02-27_03h33m.tgz sirnasilot_backup_2025-03-03_03h33m.tgz
sirnasilot_backup_2025-02-28_03h33m.tgz sirnasilot_backup_2025-03-04_03h33m.tgz
But clearly my crontab is NOT working
builder@builder-T100:~/sirnasilot-backups$ sudo crontab -l | tail -n1
10 1 * * * find /home/builder/sirnasilot-backups -type f -printf '%T@ %p\n' | sort -n | head -n -10 | cut -d' ' -f2- | xargs rm -f
Let’s solve this with Ansible instead.
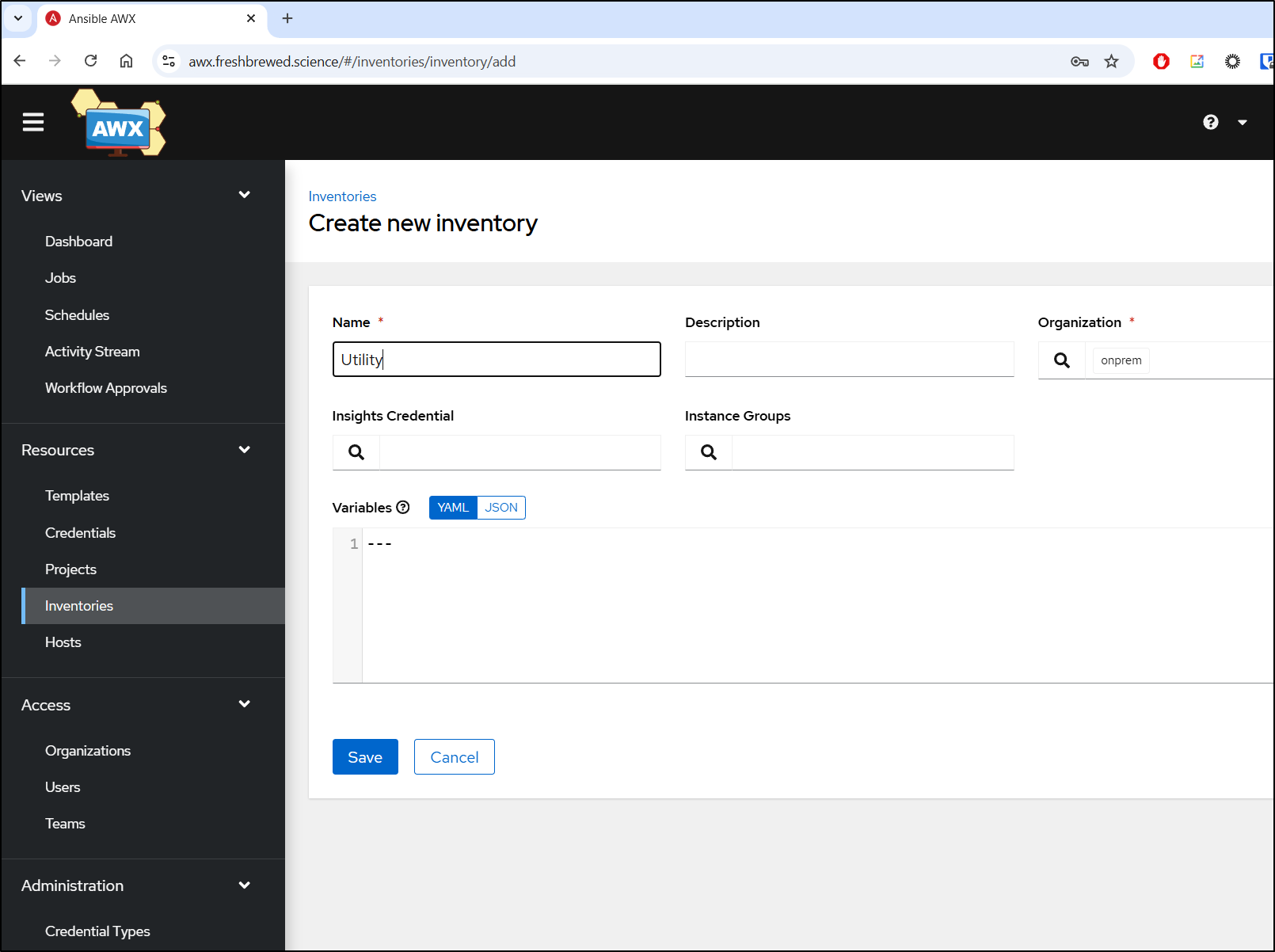
I’ll hop over to my AWX host where I need to start by creating a new inventory
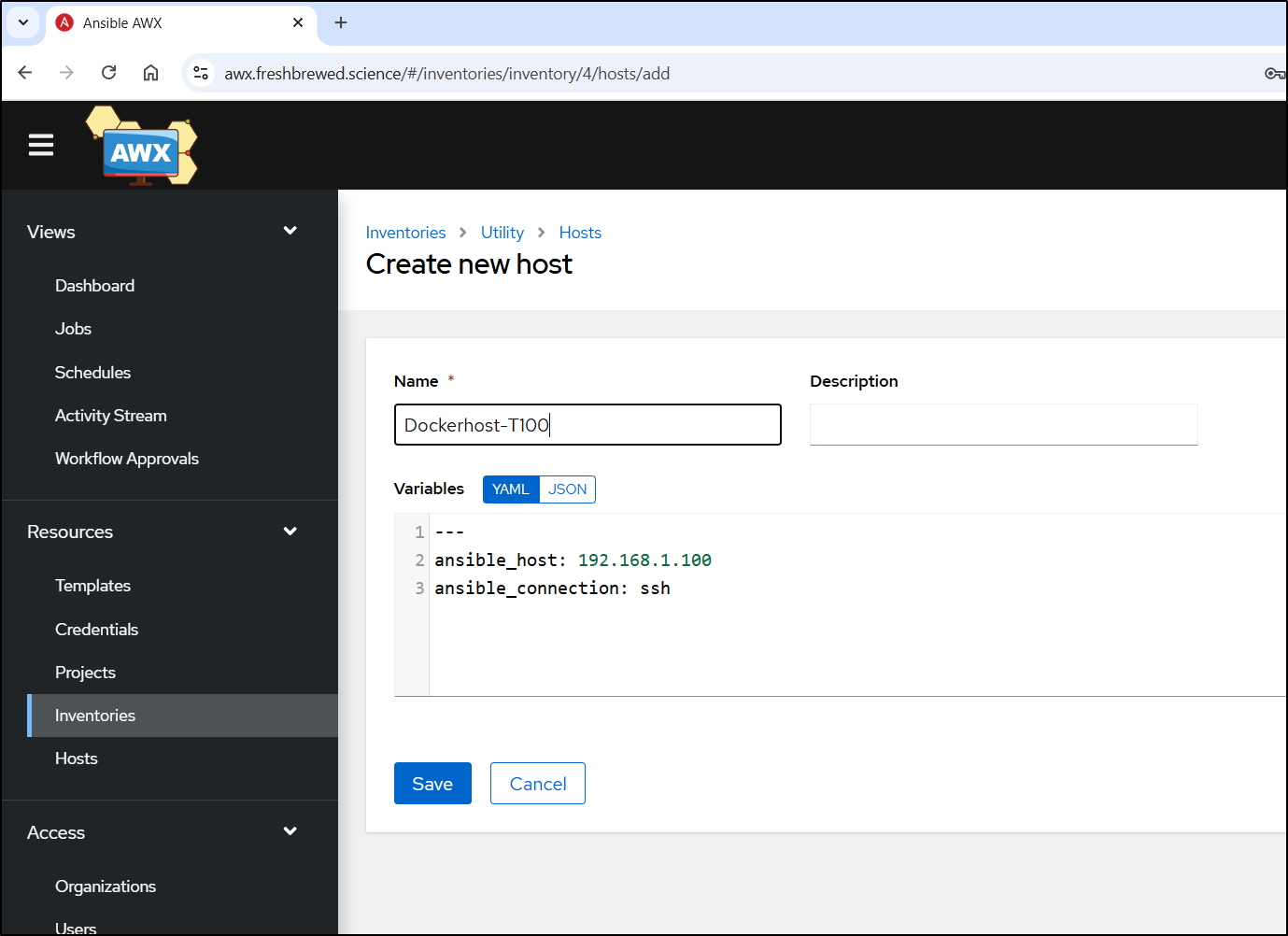
From there, I add host and fill in the details of this linux machine
Next, I want to double check my credentials and connectivity are good. I’ll go to Inventory, select the host and choose “Run Command”
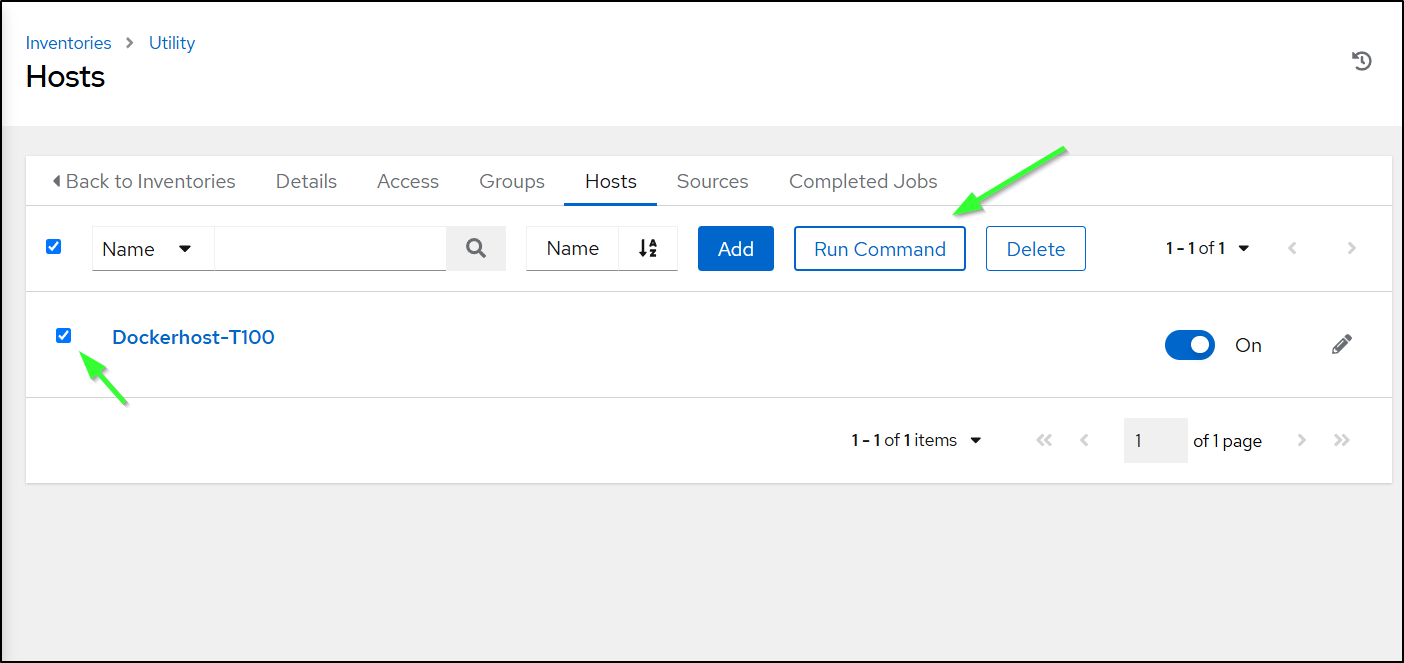
I’ll do a simple “pwd” command and then pick my credential on the next screen
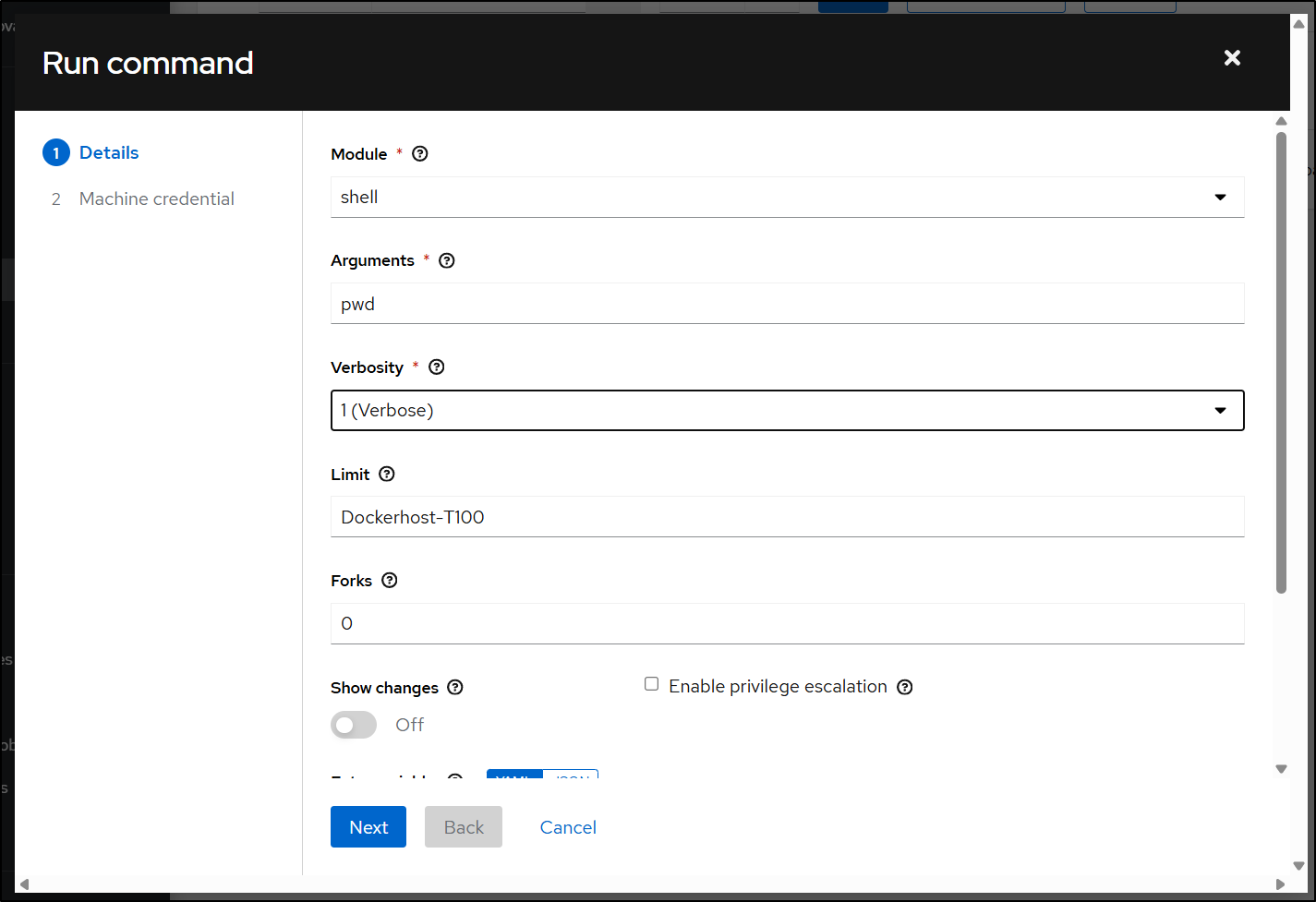
That worked great
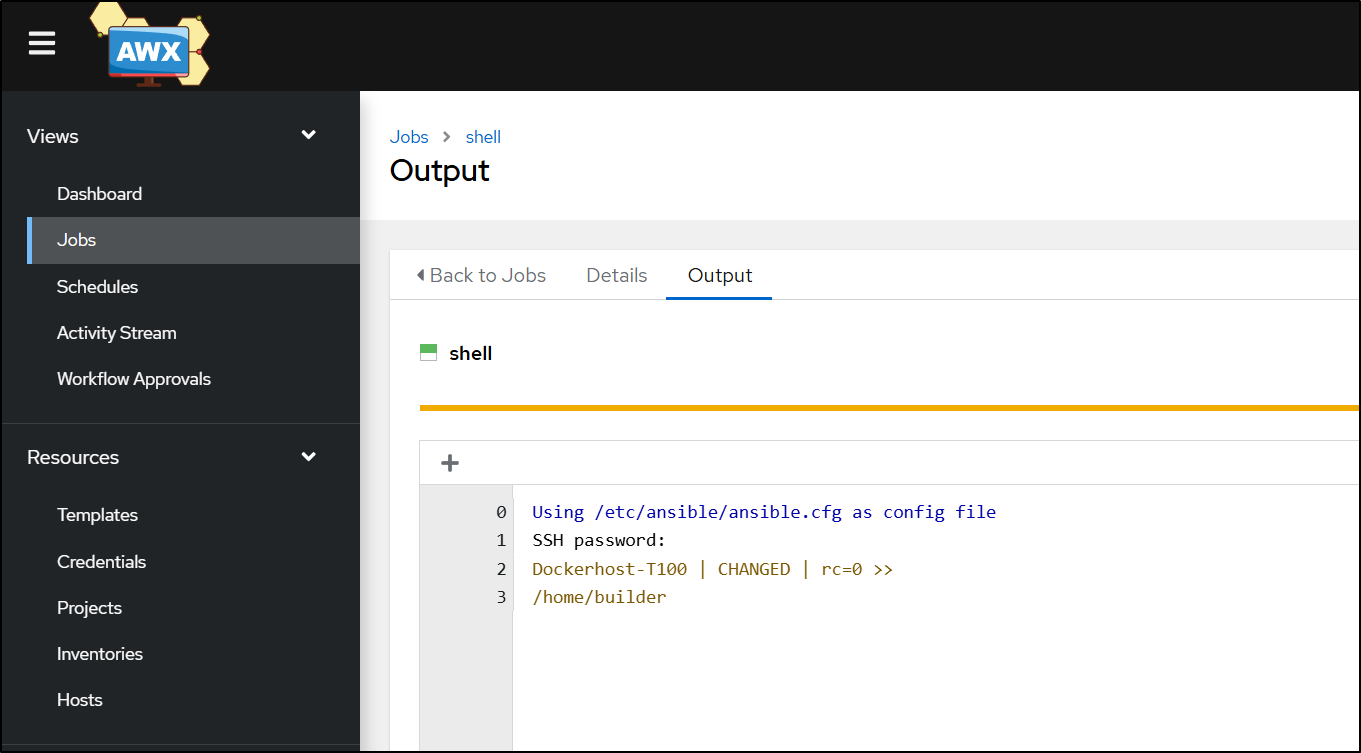
I’ll do the same with “Privileged Escalation” to ensure passwordless root
and that worked without issue
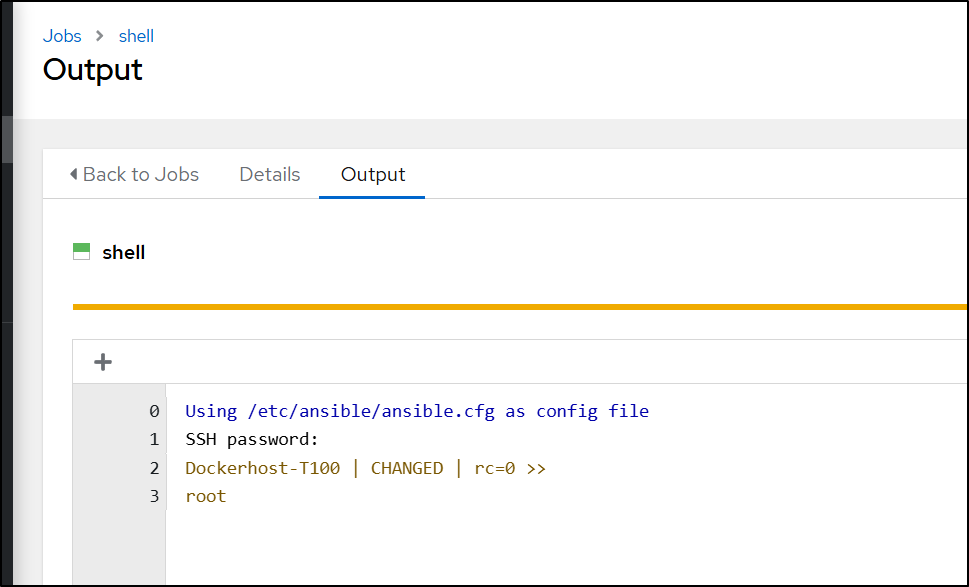
I’ll create two files, one will be the cleanupfolder.sh (yes, leaving in the “echo rm” is intentional for the moment)
#!/bin/bash
# Check if required arguments are provided
if [ $# -ne 2 ]; then
echo "Usage: $0 <backup_directory> <number_of_files_to_keep>"
echo "Example: $0 /path/to/backups 10"
exit 1
fi
BACKUP_DIR="$1"
FILES_TO_KEEP="$2"
# Check if backup directory exists
if [ ! -d "$BACKUP_DIR" ]; then
echo "Error: Directory $BACKUP_DIR does not exist"
exit 1
fi
# Check if FILES_TO_KEEP is a positive number
if ! [[ "$FILES_TO_KEEP" =~ ^[0-9]+$ ]] || [ "$FILES_TO_KEEP" -lt 1 ]; then
echo "Error: Number of files to keep must be a positive integer"
exit 1
fi
find "$BACKUP_DIR" -type f -printf '%T@ %p\n' | sort -n | head -n -"$FILES_TO_KEEP" | cut -d' ' -f2- | xargs echo rm -f
And the ansible playbook to run it
- name: Cleanup Backups
hosts: all
tasks:
- name: Transfer the script
copy: src=cleanupfolder.sh dest=/tmp mode=0755
# use ACTION=dryrun or ACTION=DOIT
- name: Run the script
ansible.builtin.shell: |
./cleanupfolder.sh
args:
chdir: /tmp
I’ll then push them up to the ansible repo
builder@DESKTOP-QADGF36:~/Workspaces/ansible-playbooks$ git add cleanupfolder.sh
builder@DESKTOP-QADGF36:~/Workspaces/ansible-playbooks$ git add cleanupfolder.yaml
builder@DESKTOP-QADGF36:~/Workspaces/ansible-playbooks$ git commit -m "Cleanup Playbook"
[main c19eb30] Cleanup Playbook
2 files changed, 38 insertions(+)
create mode 100755 cleanupfolder.sh
create mode 100644 cleanupfolder.yaml
builder@DESKTOP-QADGF36:~/Workspaces/ansible-playbooks$ git push
Enumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Delta compression using up to 16 threads
Compressing objects: 100% (4/4), done.
Writing objects: 100% (4/4), 913 bytes | 913.00 KiB/s, done.
Total 4 (delta 1), reused 0 (delta 0)
remote: Resolving deltas: 100% (1/1), completed with 1 local object.
To https://github.com/idjohnson/ansible-playbooks.git
d258d6e..c19eb30 main -> main
In AWX, I’ll sync to get my latest playbooks
I can now set up the template.
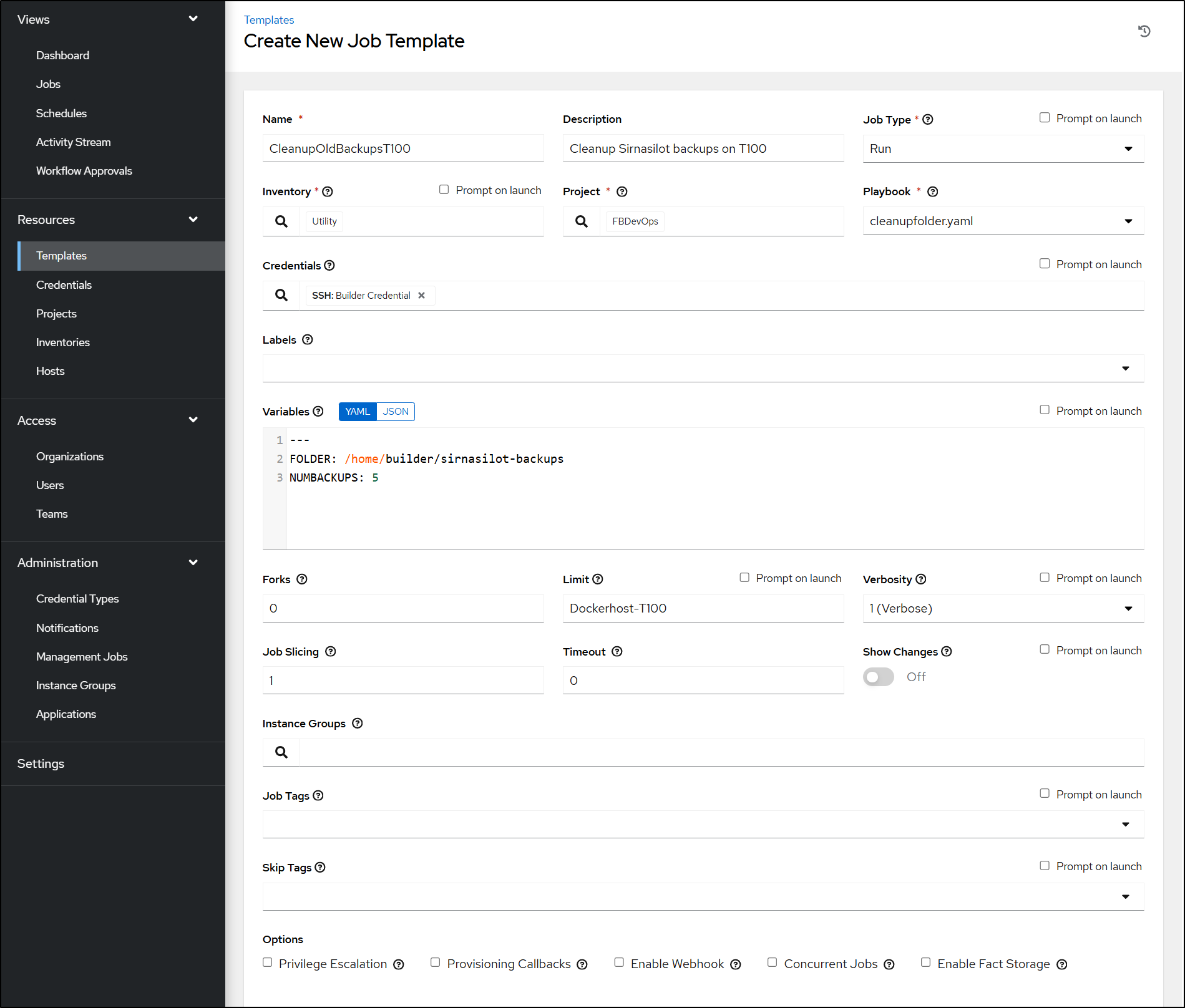
You’ll notice above that we set variables for the folder and number of backups (So i could reuse this template for other cleanup work). I set “5” so I could see some results (as I just did 10 when I cleaned things up earlier)
---
FOLDER: /home/builder/sirnasilot-backups
NUMBACKUPS: 5
You’ll also notice I picked the “Utility” inventory, but limit to the name of the host in my hosts so this should jsut run on the one server.
Now, I can save and launch
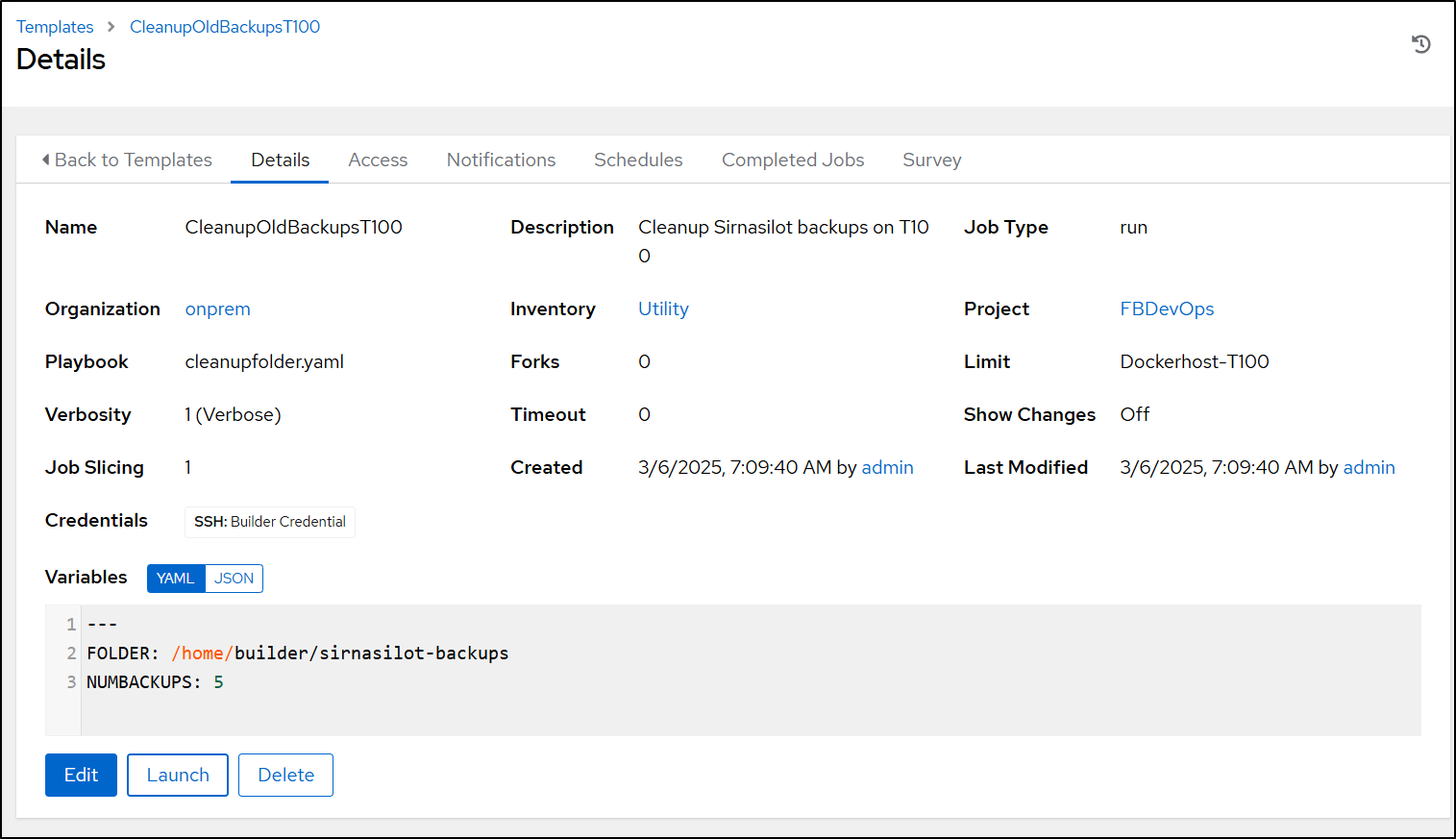
And that worked, though it’s just echoing for now
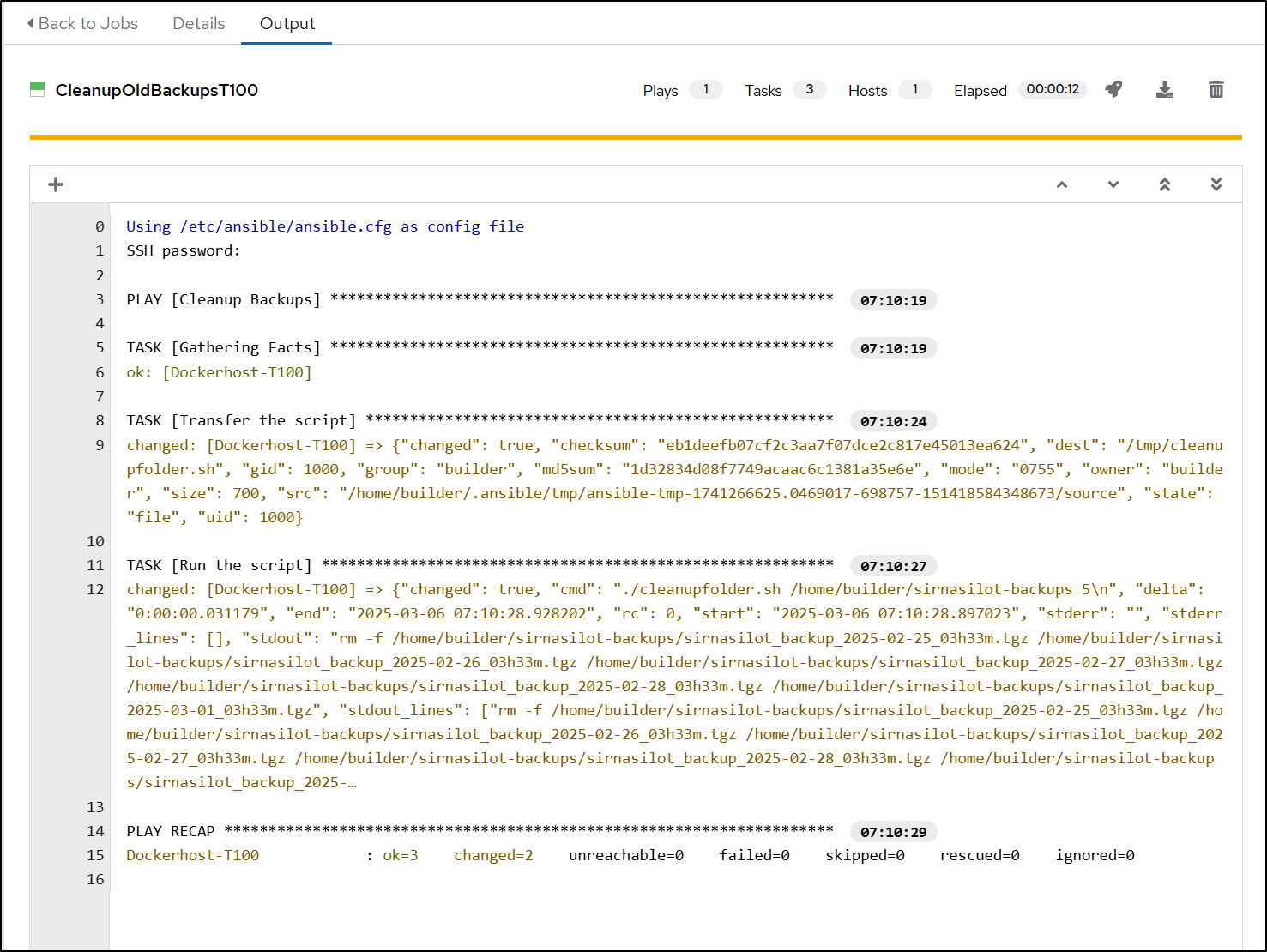
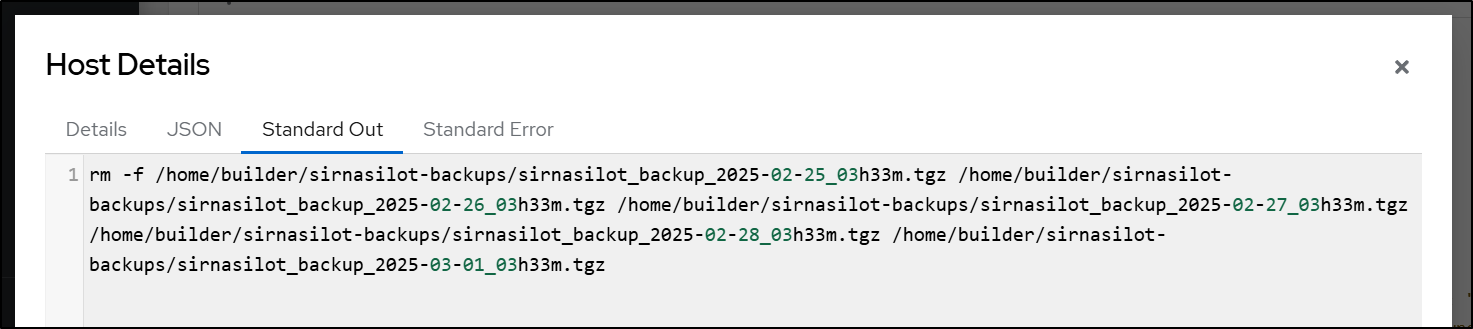
I decided having a dryrun might be wise, so I added that to the shell script
#!/bin/bash
# Check if required arguments are provided
if [ $# -ne 3 ]; then
echo "Usage: $0 <backup_directory> <number_of_files_to_keep> <action: DRYRUN or DOIT>"
echo "Example: $0 /path/to/backups 10 DRYRUN"
exit 1
fi
BACKUP_DIR="$1"
FILES_TO_KEEP="$2"
ACTION="$3"
# Check if backup directory exists
if [ ! -d "$BACKUP_DIR" ]; then
echo "Error: Directory $BACKUP_DIR does not exist"
exit 1
fi
# Check if FILES_TO_KEEP is a positive number
if ! [[ "$FILES_TO_KEEP" =~ ^[0-9]+$ ]] || [ "$FILES_TO_KEEP" -lt 1 ]; then
echo "Error: Number of files to keep must be a positive integer"
exit 1
fi
if [ "$ACTION" != "DRYRUN" ] && [ "$ACTION" != "DOIT" ]; then
echo "Error: Action must be either DRYRUN or DOIT"
exit 1
fi
if [ "$ACTION" == "DRYRUN" ]; then
echo "Dry run mode"
find "$BACKUP_DIR" -type f -printf '%T@ %p\n' | sort -n | head -n -"$FILES_TO_KEEP" | cut -d' ' -f2- | xargs echo rm -f
fi
if [ "$ACTION" == "DOIT" ]; then
echo "Do it mode"
find "$BACKUP_DIR" -type f -printf '%T@ %p\n' | sort -n | head -n -"$FILES_TO_KEEP" | cut -d' ' -f2- | xargs rm -f
fi
and to the Playbook that calls it
- name: Cleanup Backups
hosts: all
tasks:
- name: Transfer the script
copy: src=cleanupfolder.sh dest=/tmp mode=0755
# use ACTION=dryrun or ACTION=DOIT
- name: Run the script
ansible.builtin.shell: |
./cleanupfolder.sh
args:
chdir: /tmp
After syncing the project in AWX, I can edit the template and add that “Action” parameter
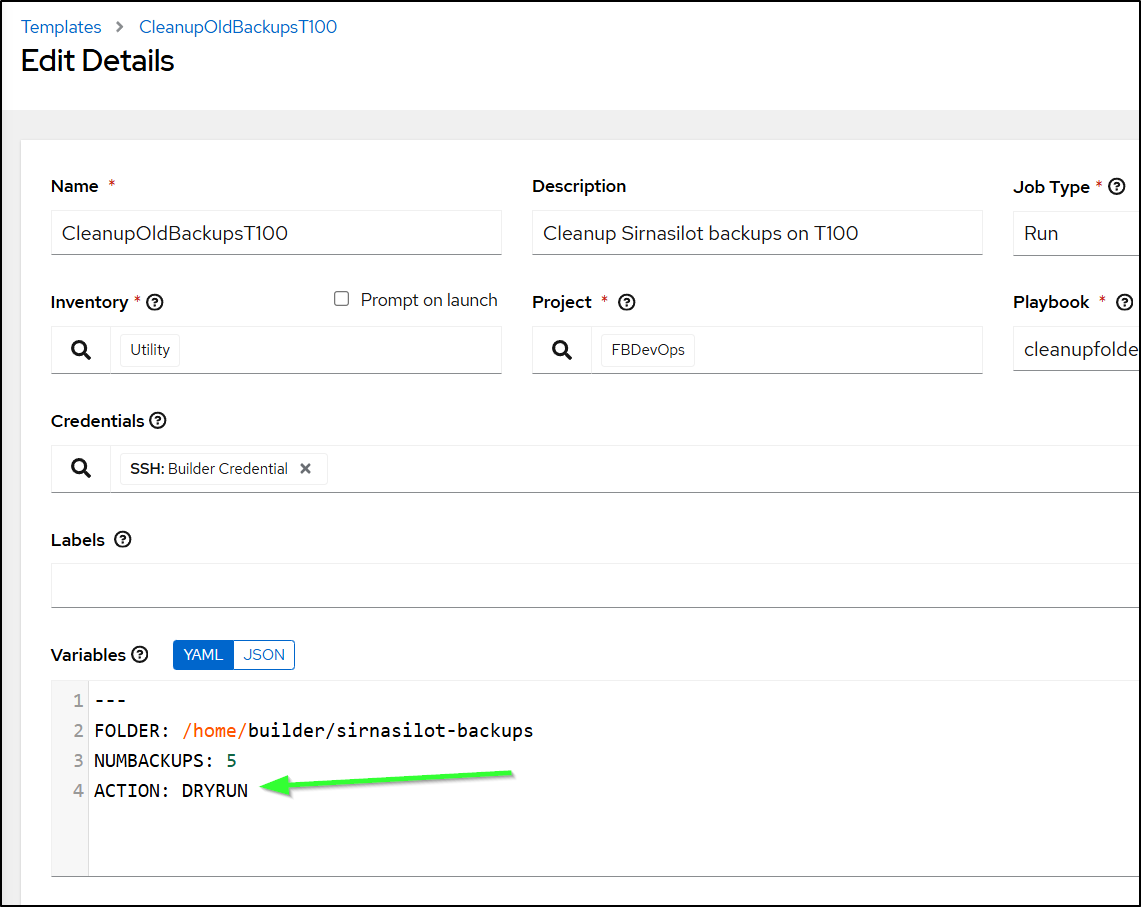
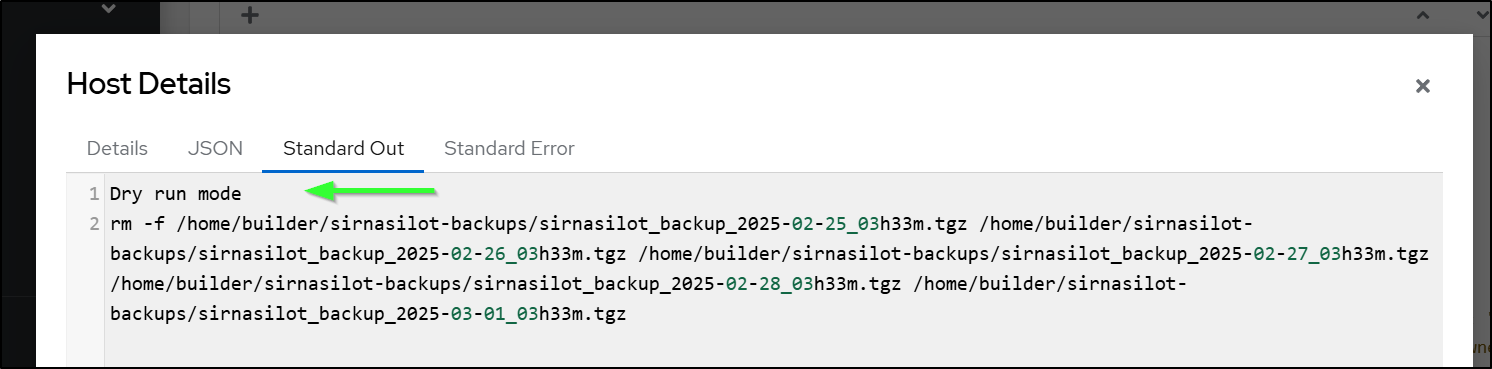
A save and launch shows it’s picking up the changes
Lastly, I’ll set it to 10 (shouldn’t be anything to clean today) and set the action to “DOIT”
---
FOLDER: /home/builder/sirnasilot-backups
NUMBACKUPS: 10
ACTION: DOIT
and run
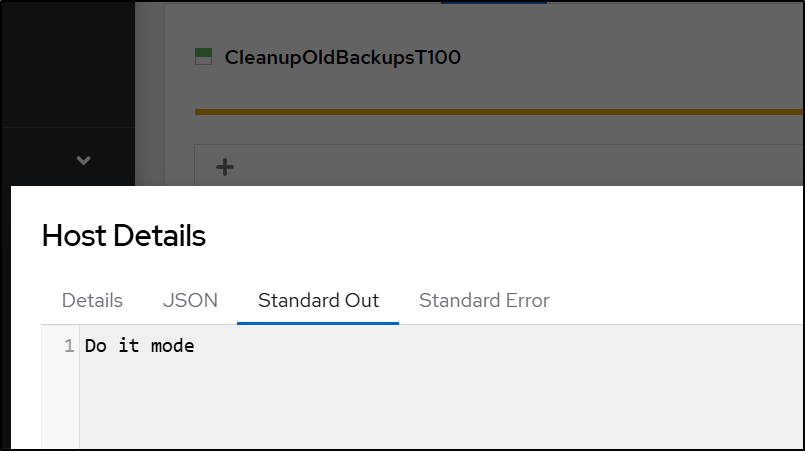
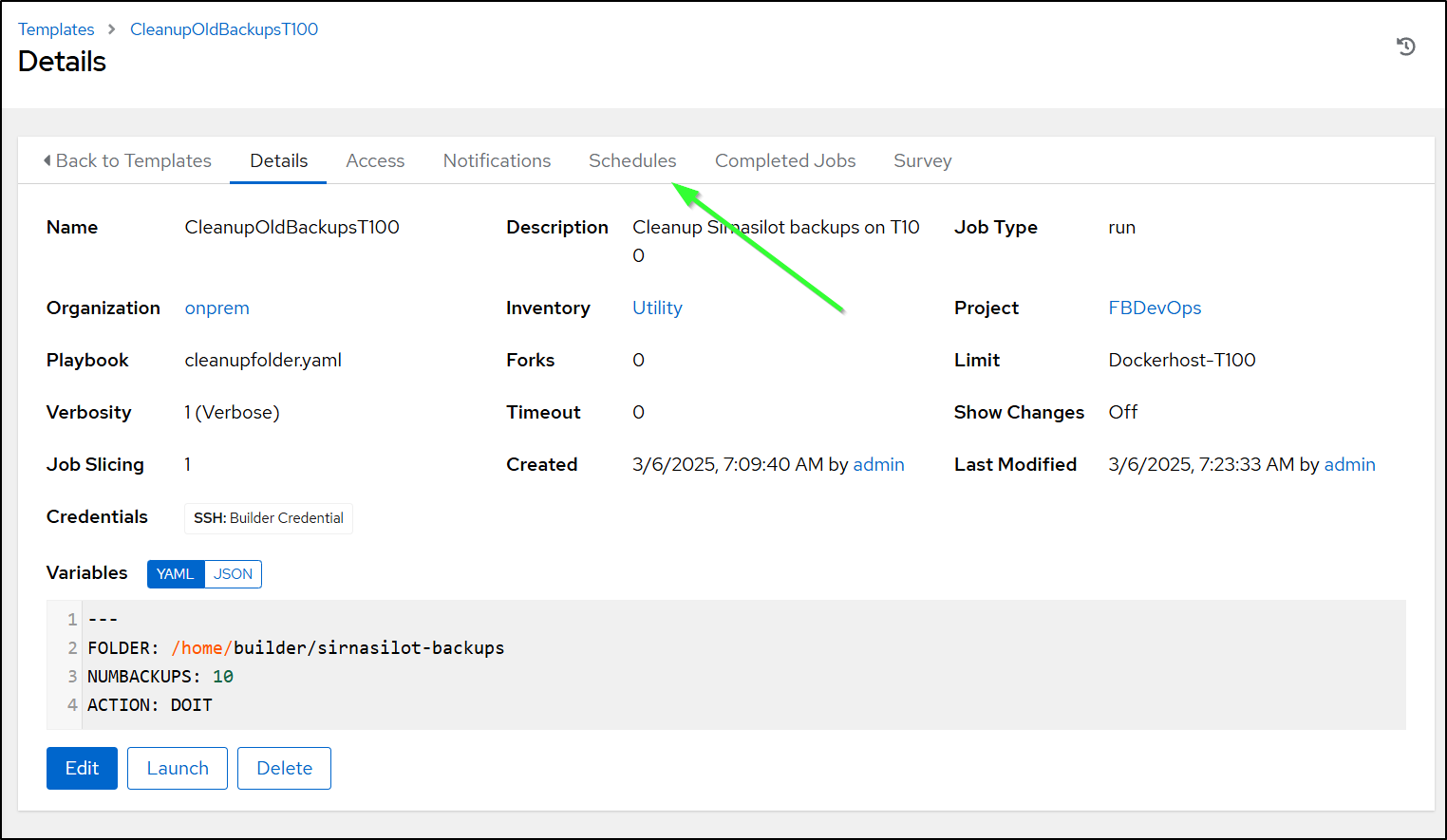
This looks great. One last change to make this a scheduled task is to go to Schedules
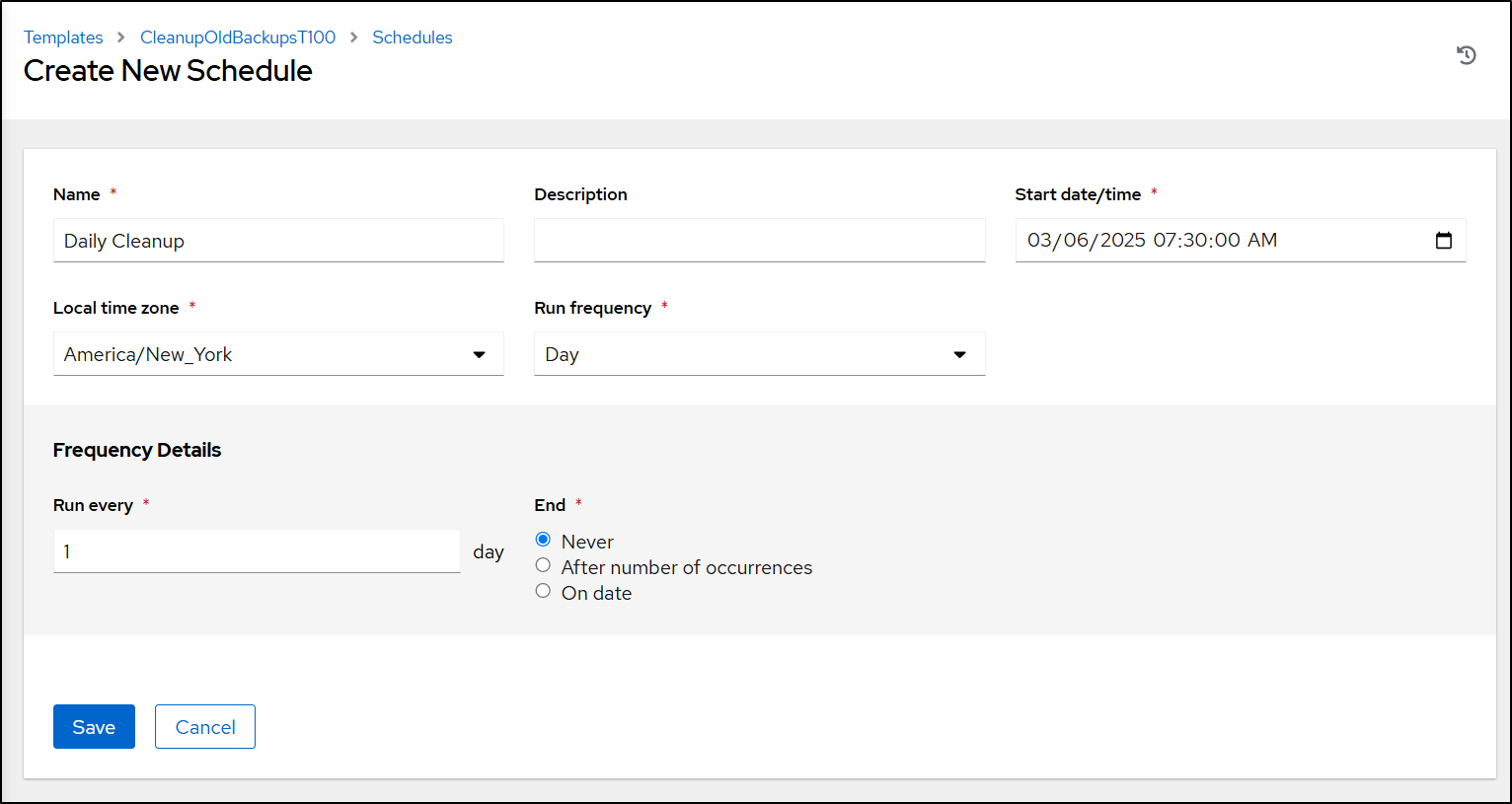
And set it to run daily
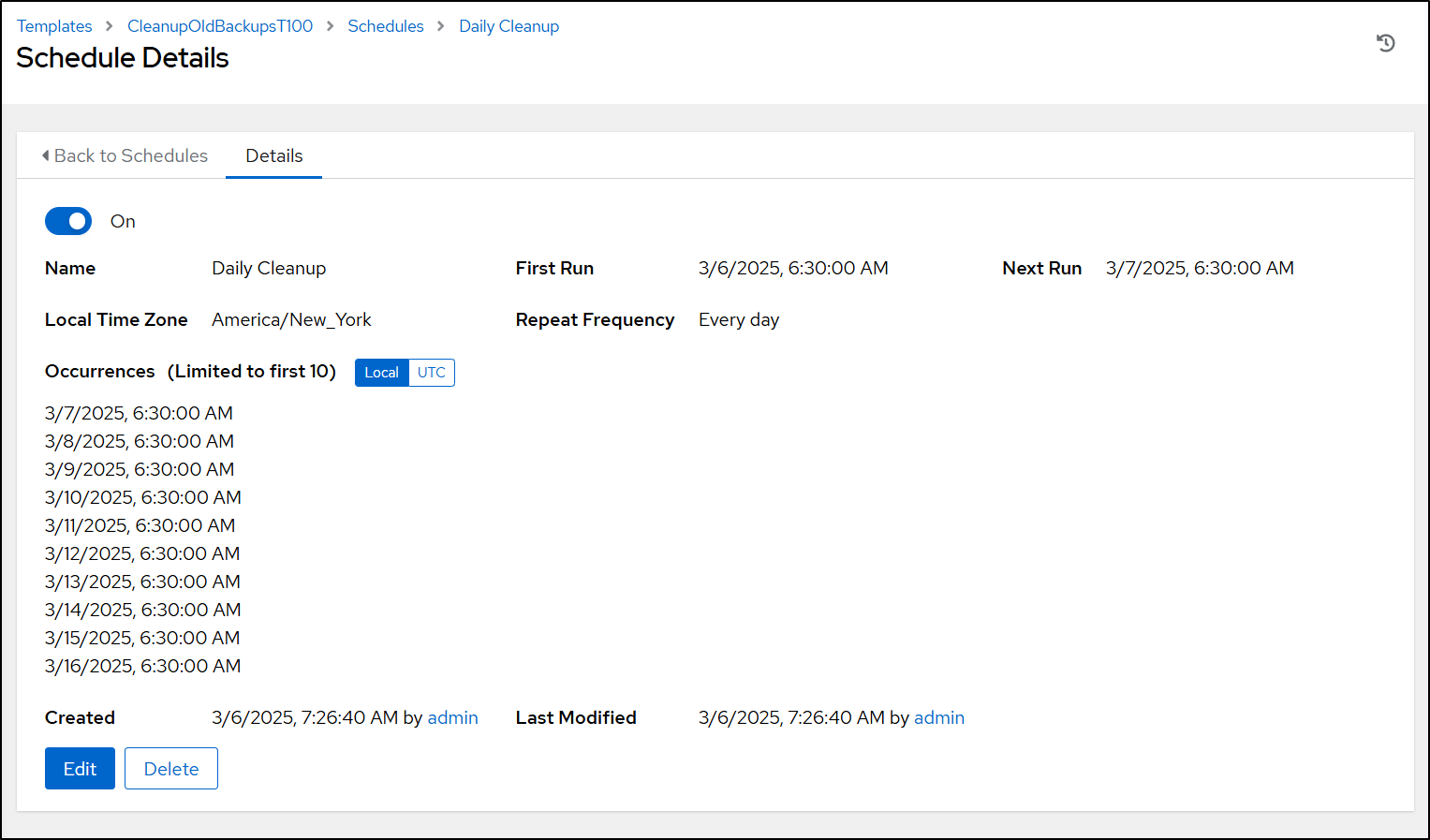
On saving, we can see the schedules in CST
Lastly, let’s remove the crontab that isn’t working
builder@builder-T100:~$ sudo crontab -l | tail -n3
30 1 * * 3 tar -zcvf /mnt/myfbsfuseblob/vaultbackups.$(date '+\%Y-\%m-\%d_\%Hh\%Mm').tgz /home/builder/vaultwarden/data
30 1 * * 3 tar -zcvf /mnt/myfbsfuseblob/filegator.$(date '+\%Y-\%m-\%d_\%Hh\%Mm').tgz /home/builder/filegator/repository2
10 1 * * * find /home/builder/sirnasilot-backups -type f -printf '%T@ %p\n' | sort -n | head -n -10 | cut -d' ' -f2- | xargs rm -f
builder@builder-T100:~$ sudo crontab -e
crontab: installing new crontab
builder@builder-T100:~$ sudo crontab -l | tail -n3
# m h dom mon dow command
30 1 * * 3 tar -zcvf /mnt/myfbsfuseblob/vaultbackups.$(date '+\%Y-\%m-\%d_\%Hh\%Mm').tgz /home/builder/vaultwarden/data
30 1 * * 3 tar -zcvf /mnt/myfbsfuseblob/filegator.$(date '+\%Y-\%m-\%d_\%Hh\%Mm').tgz /home/builder/filegator/repository2
Summary
This was a bit of a catch-all of issues I’ve had to sort out lately. We covered fixing an expired auth cred in Gitlab and then reducing schedules. We spoke on backing up private Git repos from things like Forgejo to Gitea. We then also showed how to backup Repos from Github.
I covered an issue after a hotfix rebooted my NAS and took down Minio. Lastly, I covered what happens at the year mark with K3s. For some reason this happens every year and I always forget about it and have to look it back up. Maybe this time next year I’ll remember to rotate them in advance.
The last step, which I added just before posting, was to move a cron based cleanup task which just was not working in Linux over to an ansible playbook. My playbooks are public so you can view the script and playbook I used. Hopefully this takes care of the disk bloat on my dockerhost due to backups from here on out.
