

Published: Jan 28, 2025 by Isaac Johnson
Today I’ll explore the use of Ollama, the AI Model runner, as a virtual AI Coding Assistant akin to Copilot or Gemini Code Assist. This lets me run an LLM locally on the hardware I already own. Using Continue.dev, I can tie it in to VS Code and Code Server so my Chat and Inline prompts in my Code Editor use those local Ollama instances.
I will set this up within WSL on Windows as well as on a Linux host – all while showing some examples along the way. I’ll also touch on some external models as well such as Mistral AI.
This is a fantastic way to leverage AI to help code without having to sign up for a monthly service.
Let’s start by adding Continue to VS Code.
Continue for VS Code
Since Visual Studio Code is my preferred code editor, I figured I would find a good solution to tie VS Code to my local Ollama so I could roll my own LLM Code Assistant.
To start, we can go to Continue’s install page which tells us we should just be able to find it in the VS Code Marketplace
I can click install
then see it show up to my left (in this editor)
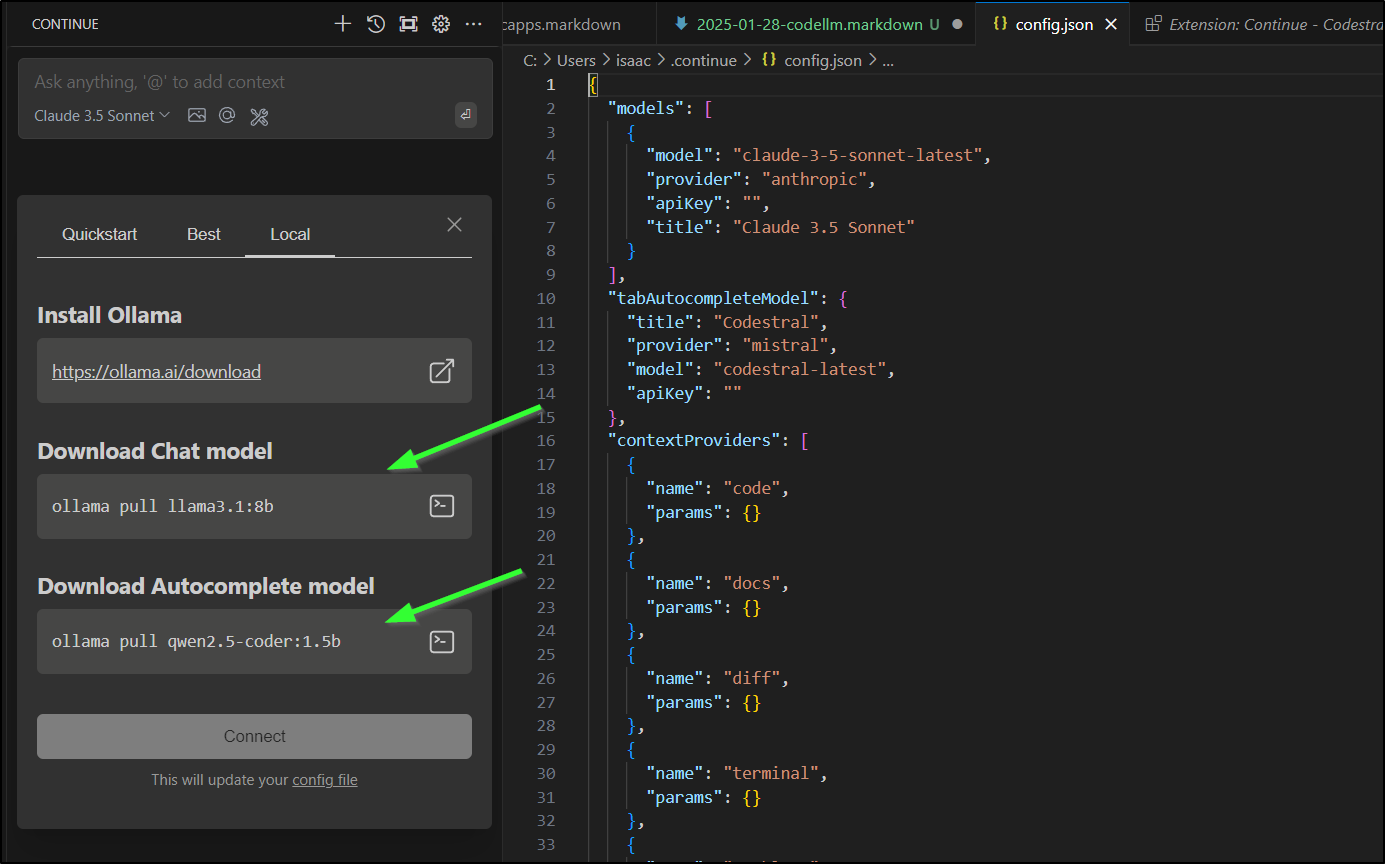
I’ll do as it suggests for “local” to pull in the models
To start, in one WSL window I kicked off Ollama
builder@DESKTOP-QADGF36:~/Workspaces/BoltFitnessApp$ ollama start
2025/01/23 17:20:18 routes.go:1259: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://127.0.0.1:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/home/builder/.ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false ROCR_VISIBLE_DEVICES: http_proxy: https_proxy: no_proxy:]"
time=2025-01-23T17:20:18.587-06:00 level=INFO source=images.go:757 msg="total blobs: 17"
time=2025-01-23T17:20:18.587-06:00 level=INFO source=images.go:764 msg="total unused blobs removed: 0"
[GIN-debug] [WARNING] Creating an Engine instance with the Logger and Recovery middleware already attached.
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
- using env: export GIN_MODE=release
- using code: gin.SetMode(gin.ReleaseMode)
[GIN-debug] POST /api/pull --> github.com/ollama/ollama/server.(*Server).PullHandler-fm (5 handlers)
[GIN-debug] POST /api/generate --> github.com/ollama/ollama/server.(*Server).GenerateHandler-fm (5 handlers)
[GIN-debug] POST /api/chat --> github.com/ollama/ollama/server.(*Server).ChatHandler-fm (5 handlers)
[GIN-debug] POST /api/embed --> github.com/ollama/ollama/server.(*Server).EmbedHandler-fm (5 handlers)
[GIN-debug] POST /api/embeddings --> github.com/ollama/ollama/server.(*Server).EmbeddingsHandler-fm (5 handlers)
[GIN-debug] POST /api/create --> github.com/ollama/ollama/server.(*Server).CreateHandler-fm (5 handlers)
[GIN-debug] POST /api/push --> github.com/ollama/ollama/server.(*Server).PushHandler-fm (5 handlers)
[GIN-debug] POST /api/copy --> github.com/ollama/ollama/server.(*Server).CopyHandler-fm (5 handlers)
[GIN-debug] DELETE /api/delete --> github.com/ollama/ollama/server.(*Server).DeleteHandler-fm (5 handlers)
[GIN-debug] POST /api/show --> github.com/ollama/ollama/server.(*Server).ShowHandler-fm (5 handlers)
[GIN-debug] POST /api/blobs/:digest --> github.com/ollama/ollama/server.(*Server).CreateBlobHandler-fm (5 handlers)
[GIN-debug] HEAD /api/blobs/:digest --> github.com/ollama/ollama/server.(*Server).HeadBlobHandler-fm (5 handlers)
[GIN-debug] GET /api/ps --> github.com/ollama/ollama/server.(*Server).PsHandler-fm (5 handlers)
[GIN-debug] POST /v1/chat/completions --> github.com/ollama/ollama/server.(*Server).ChatHandler-fm (6 handlers)
[GIN-debug] POST /v1/completions --> github.com/ollama/ollama/server.(*Server).GenerateHandler-fm (6 handlers)
[GIN-debug] POST /v1/embeddings --> github.com/ollama/ollama/server.(*Server).EmbedHandler-fm (6 handlers)
[GIN-debug] GET /v1/models --> github.com/ollama/ollama/server.(*Server).ListHandler-fm (6 handlers)
[GIN-debug] GET /v1/models/:model --> github.com/ollama/ollama/server.(*Server).ShowHandler-fm (6 handlers)
[GIN-debug] GET / --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func1 (5 handlers)
[GIN-debug] GET /api/tags --> github.com/ollama/ollama/server.(*Server).ListHandler-fm (5 handlers)
[GIN-debug] GET /api/version --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func2 (5 handlers)
[GIN-debug] HEAD / --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func1 (5 handlers)
[GIN-debug] HEAD /api/tags --> github.com/ollama/ollama/server.(*Server).ListHandler-fm (5 handlers)
[GIN-debug] HEAD /api/version --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func2 (5 handlers)
time=2025-01-23T17:20:18.588-06:00 level=INFO source=routes.go:1310 msg="Listening on 127.0.0.1:11434 (version 0.5.4)"
time=2025-01-23T17:20:18.590-06:00 level=INFO source=routes.go:1339 msg="Dynamic LLM libraries" runners="[cuda_v11_avx cuda_v12_avx rocm_avx cpu cpu_avx cpu_avx2]"
time=2025-01-23T17:20:18.591-06:00 level=INFO source=gpu.go:226 msg="looking for compatible GPUs"
time=2025-01-23T17:20:21.797-06:00 level=INFO source=types.go:131 msg="inference compute" id=GPU-44d5572d-f3f5-e282-2074-24b44c091e34 library=cuda variant=v12 compute=8.6 driver=12.6 name="NVIDIA GeForce RTX 3070" total="8.0 GiB" available="6.9 GiB"
[GIN] 2025/01/23 - 17:20:21 | 400 | 1.200378ms | 127.0.0.1 | POST "/api/show"
[GIN] 2025/01/23 - 17:20:21 | 200 | 3.134332ms | 127.0.0.1 | GET "/api/tags"
[GIN] 2025/01/23 - 17:20:22 | 400 | 80.543µs | 127.0.0.1 | POST "/api/show"
[GIN] 2025/01/23 - 17:20:22 | 200 | 512.717µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2025/01/23 - 17:20:25 | 200 | 453.234µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2025/01/23 - 17:20:25 | 400 | 77.838µs | 127.0.0.1 | POST "/api/show"
[GIN] 2025/01/23 - 17:20:28 | 400 | 100.742µs | 127.0.0.1 | POST "/api/show"
[GIN] 2025/01/23 - 17:20:28 | 200 | 650.59µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2025/01/23 - 17:20:31 | 400 | 117.254µs | 127.0.0.1 | POST "/api/show"
[GIN] 2025/01/23 - 17:20:31 | 200 | 556.891µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2025/01/23 - 17:20:34 | 400 | 121.171µs | 127.0.0.1 | POST "/api/show"
[GIN] 2025/01/23 - 17:20:34 | 200 | 611.736µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2025/01/23 - 17:20:37 | 400 | 89.421µs | 127.0.0.1 | POST "/api/show"
[GIN] 2025/01/23 - 17:20:37 | 200 | 593.782µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2025/01/23 - 17:20:40 | 400 | 95.221µs | 127.0.0.1 | POST "/api/show"
[GIN] 2025/01/23 - 17:20:40 | 200 | 457.171µs | 127.0.0.1 | GET "/api/tags"
... snip ....
In the other, I started up a pull. The 3.1:8b is a nice 8billion token model that should use 5Gb of memory. I do have 65Gb of memory on this host so the temptation is there to try and use llama3.1:70b.
builder@DESKTOP-QADGF36:~$ ollama pull llama3.1:8b
pulling manifest
pulling 667b0c1932bc... 100% ▕██████████████████████████████████████████████████████████████████████████████████████▏ 4.9 GB
pulling 948af2743fc7... 100% ▕██████████████████████████████████████████████████████████████████████████████████████▏ 1.5 KB
pulling 0ba8f0e314b4... 100% ▕██████████████████████████████████████████████████████████████████████████████████████▏ 12 KB
pulling 56bb8bd477a5... 100% ▕██████████████████████████████████████████████████████████████████████████████████████▏ 96 B
pulling 455f34728c9b... 100% ▕██████████████████████████████████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
I’ll then pull in the QWen model (used for Autocomplete)
builder@DESKTOP-QADGF36:~$ ollama pull qwen2.5-coder:1.5b
pulling manifest
pulling 29d8c98fa6b0... 100% ▕██████████████████████████████████████████████████████████████████████████████████████▏ 986 MB
pulling 66b9ea09bd5b... 100% ▕██████████████████████████████████████████████████████████████████████████████████████▏ 68 B
pulling e94a8ecb9327... 100% ▕██████████████████████████████████████████████████████████████████████████████████████▏ 1.6 KB
pulling 832dd9e00a68... 100% ▕██████████████████████████████████████████████████████████████████████████████████████▏ 11 KB
pulling 152cb442202b... 100% ▕██████████████████████████████████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
Here we can see us using it now to check out some code
Remote Ollama
Let’s say I wanted to use my dedicated LLM box instead of the local machine?
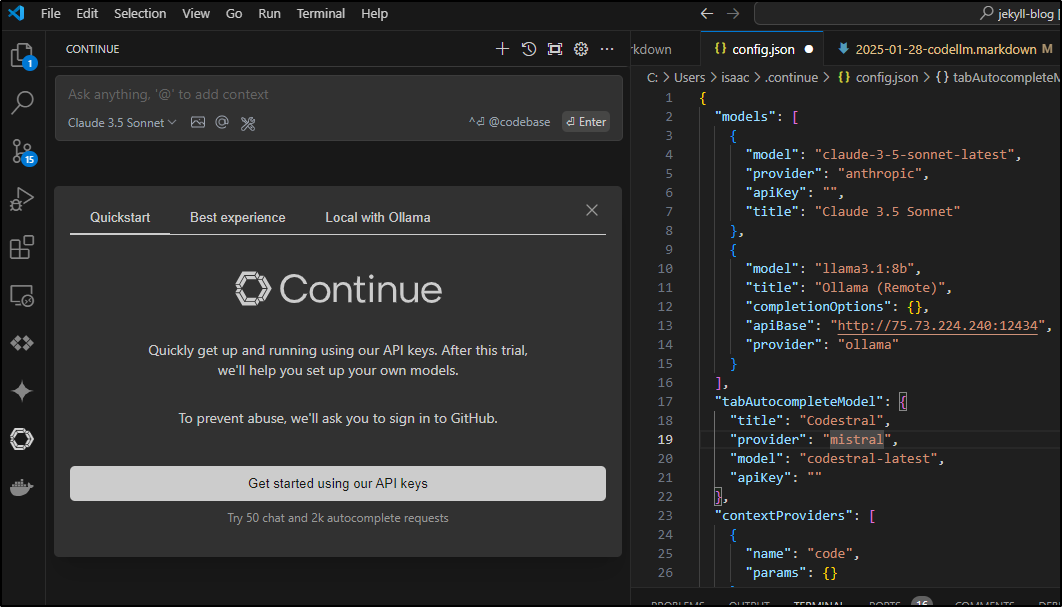
I could setup the entry in the config file like this:
"models": [
{
"title": "Llama 3.1 8B",
"provider": "ollama",
"model": "llama3.1:8b"
},
{
"model": "claude-3-5-sonnet-latest",
"provider": "anthropic",
"apiKey": "",
"title": "Claude 3.5 Sonnet"
},
{
"model": "llama3.1:8b",
"title": "Ollama (Remote)",
"completionOptions": {},
"apiBase": "http://192.168.1.143:11434",
"provider": "ollama"
},
{
"title": "Gemini 1.5 Pro",
"model": "gemini-1.5-pro-latest",
"contextLength": 2000000,
"apiKey": "asdfasdf",
"provider": "gemini"
}
],
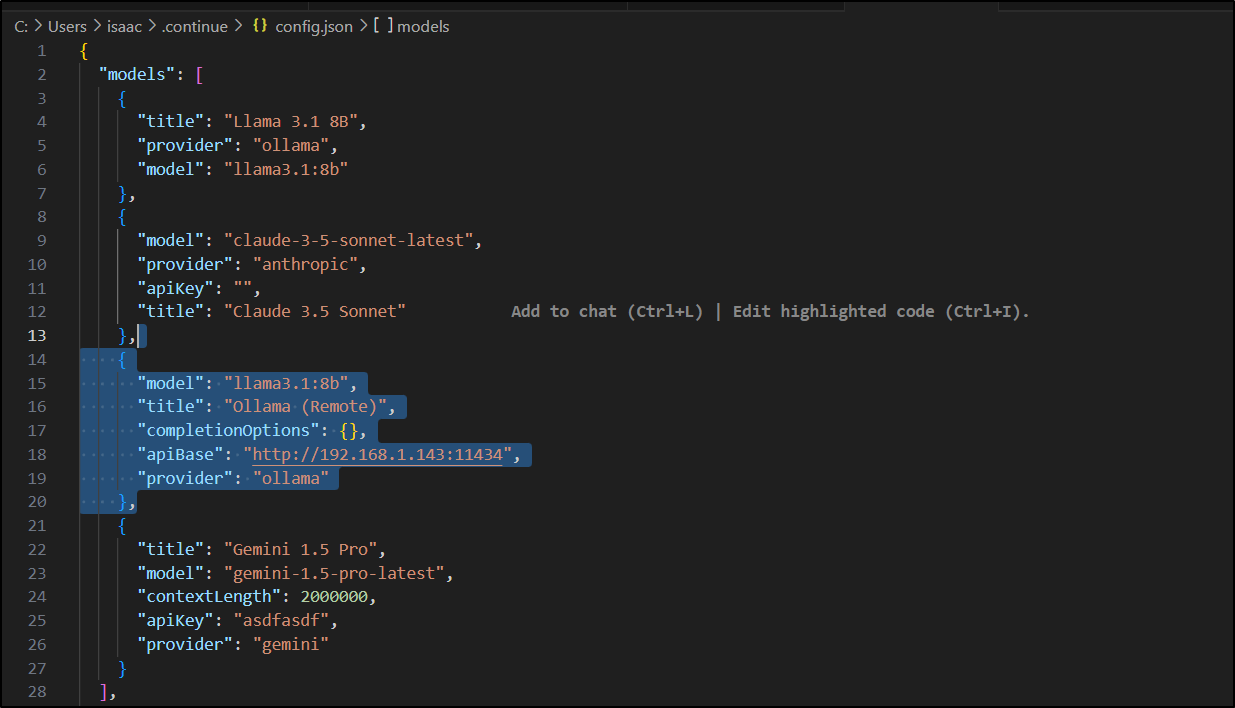
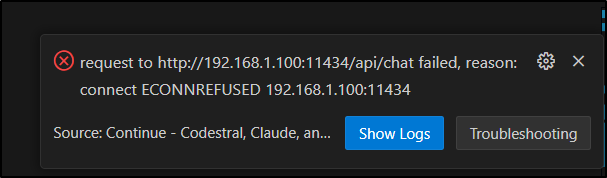
I should point out that by default Ollama is not serving up externally so you might get an error
To change that, we need to add an environment variable to serve on 0.0.0.0:
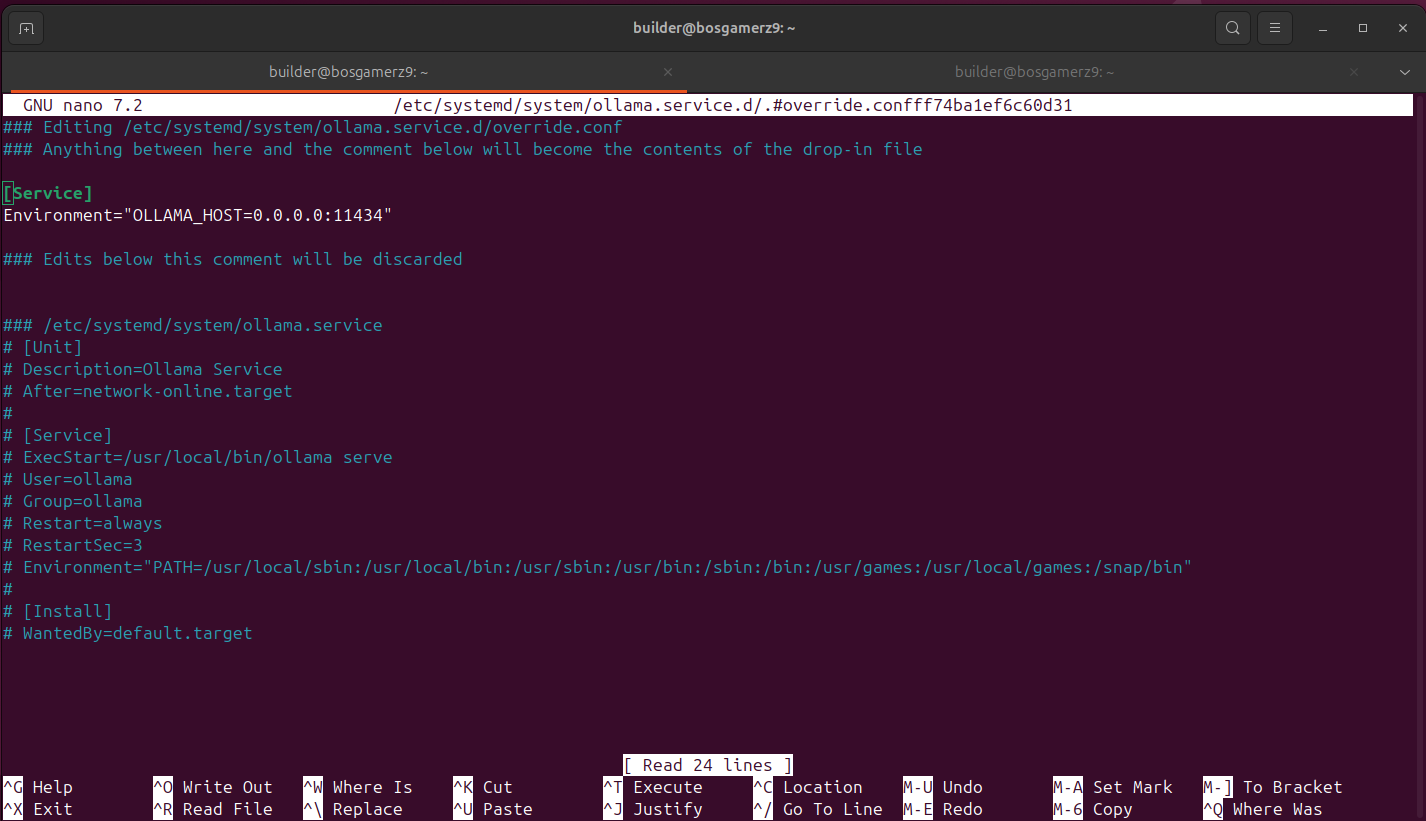
then restart the Ollama service
Now I can use the remote instance to ask questions in the chat.

It’s noticeably slower to use just the Ryzen 9 CPU with it’s built-in Radeon than my more sizable GPU in the gaming computer.
Let’s just see the performance difference:
In the above case, the “remote” is a Ryzen 9 6900HX 8C with 12Gb of RAM and a Radeon 680M. The “local” is a desktop Ryzen 7 3700X 8C with 64Gb of RAM and an NVidia GeForce RTX 3070.
Connect hosting
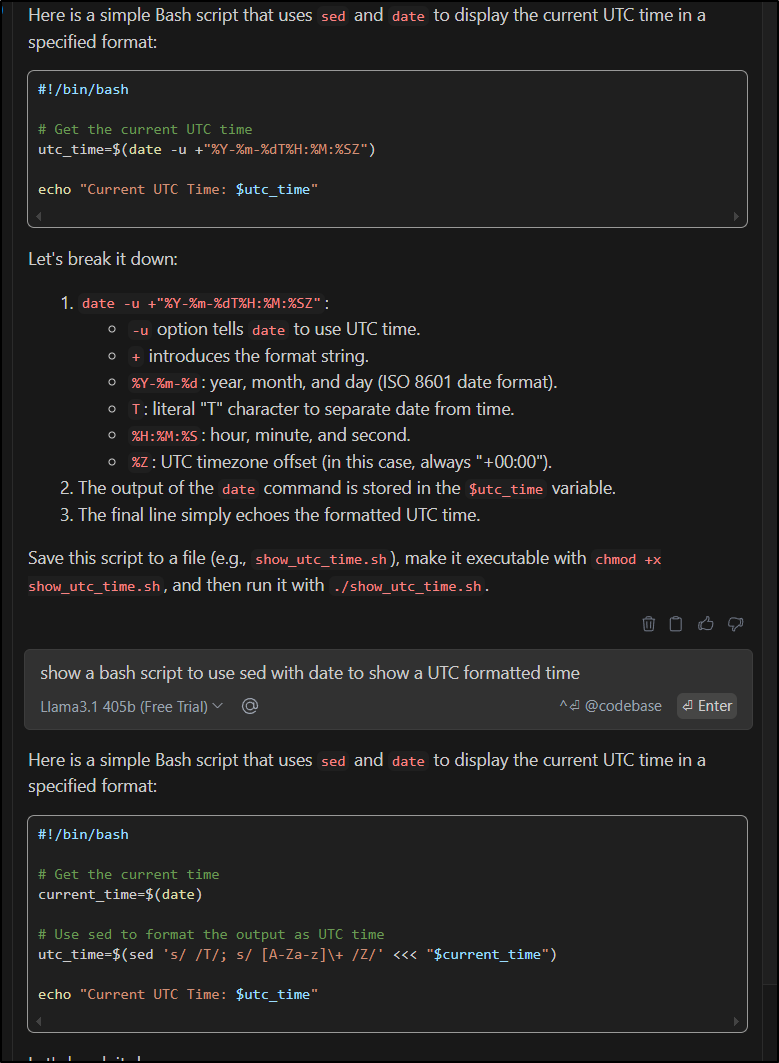
I should point out we can use a Free Trial of their hosted models. For instance, I can use their Llama3.1 405b model which is far larger than I can host:
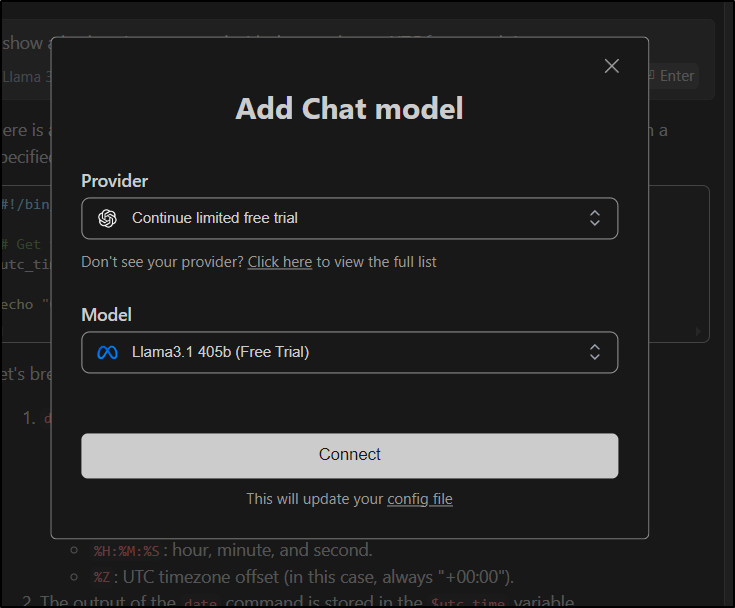
It gave a slightly different result than my local model (which I think was actually less accurate)
Continue + Remote + Code Server
What about Code Server? Could I connect Continue through to my local Ollama but expose it (in my case publicly with a password) via Code Server?
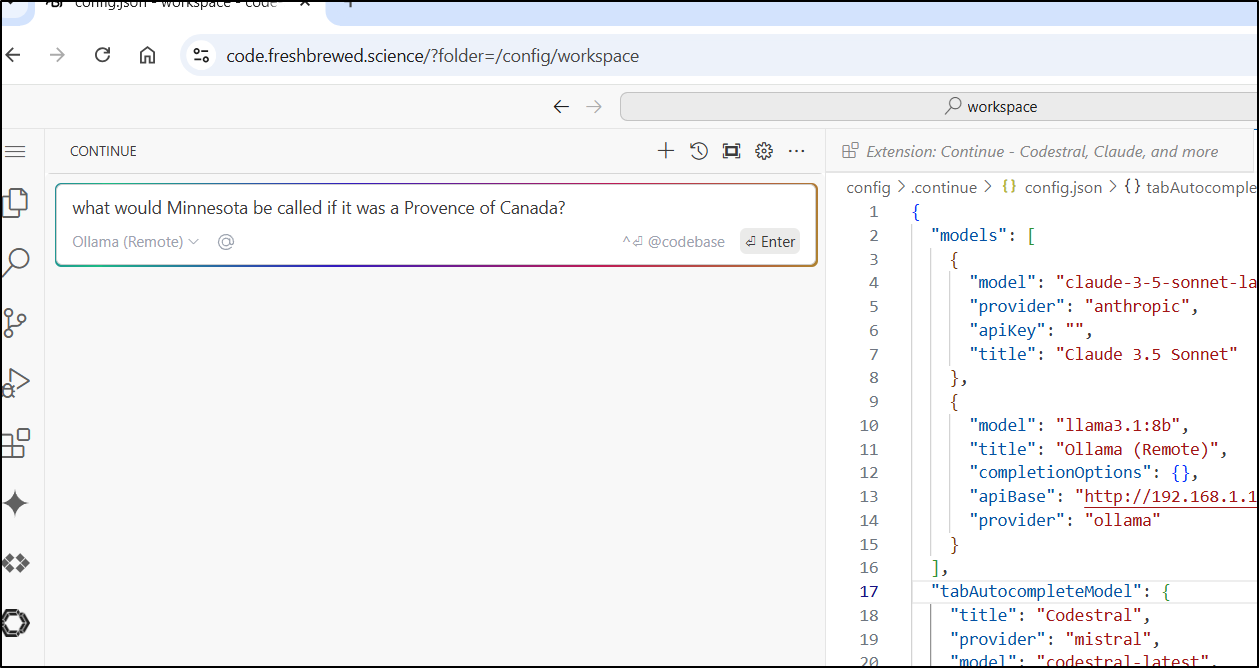
I initially tried an oddball question to see how it might handle it and it timed out
It seemed to handle an actual code question a bit better
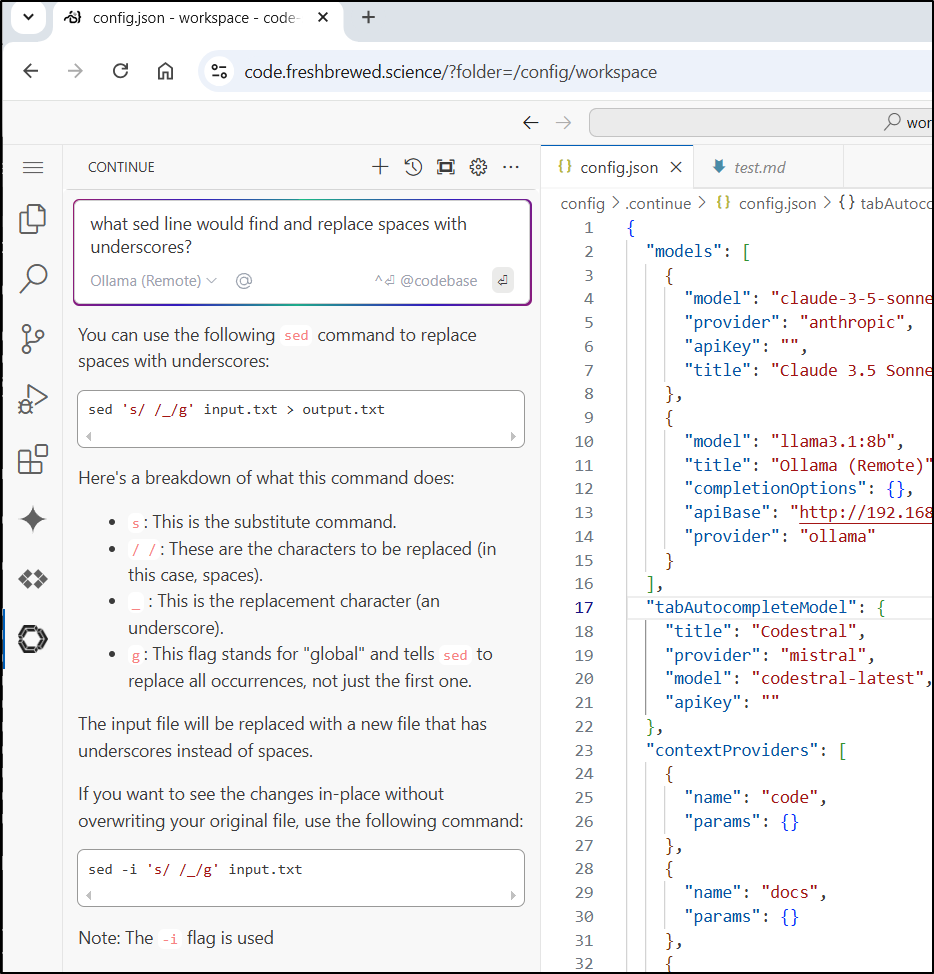
I can also hand off to the Chat my codebase which can be handy to provide some full context questions
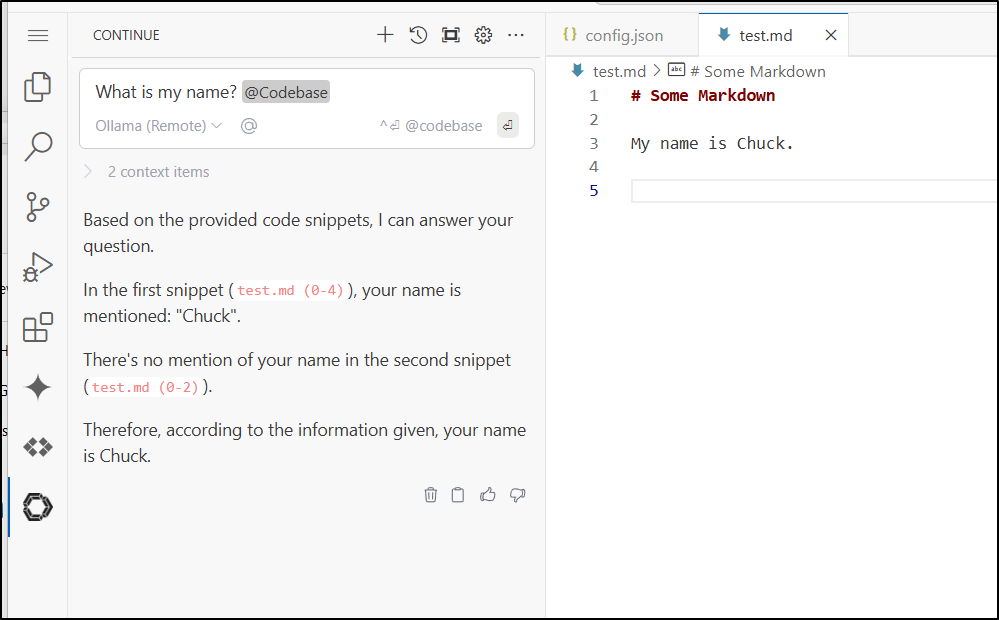
I still get rather blown away by how quick these models handle questions. This one isn’t that hard, really, but it would be a typical story problem through at a grade schooler
I can also do some interesting things. For instance, I could take this Substack article on how to use a free cloud server, copy and paste it to a markdown file then ask the model to summarize it.
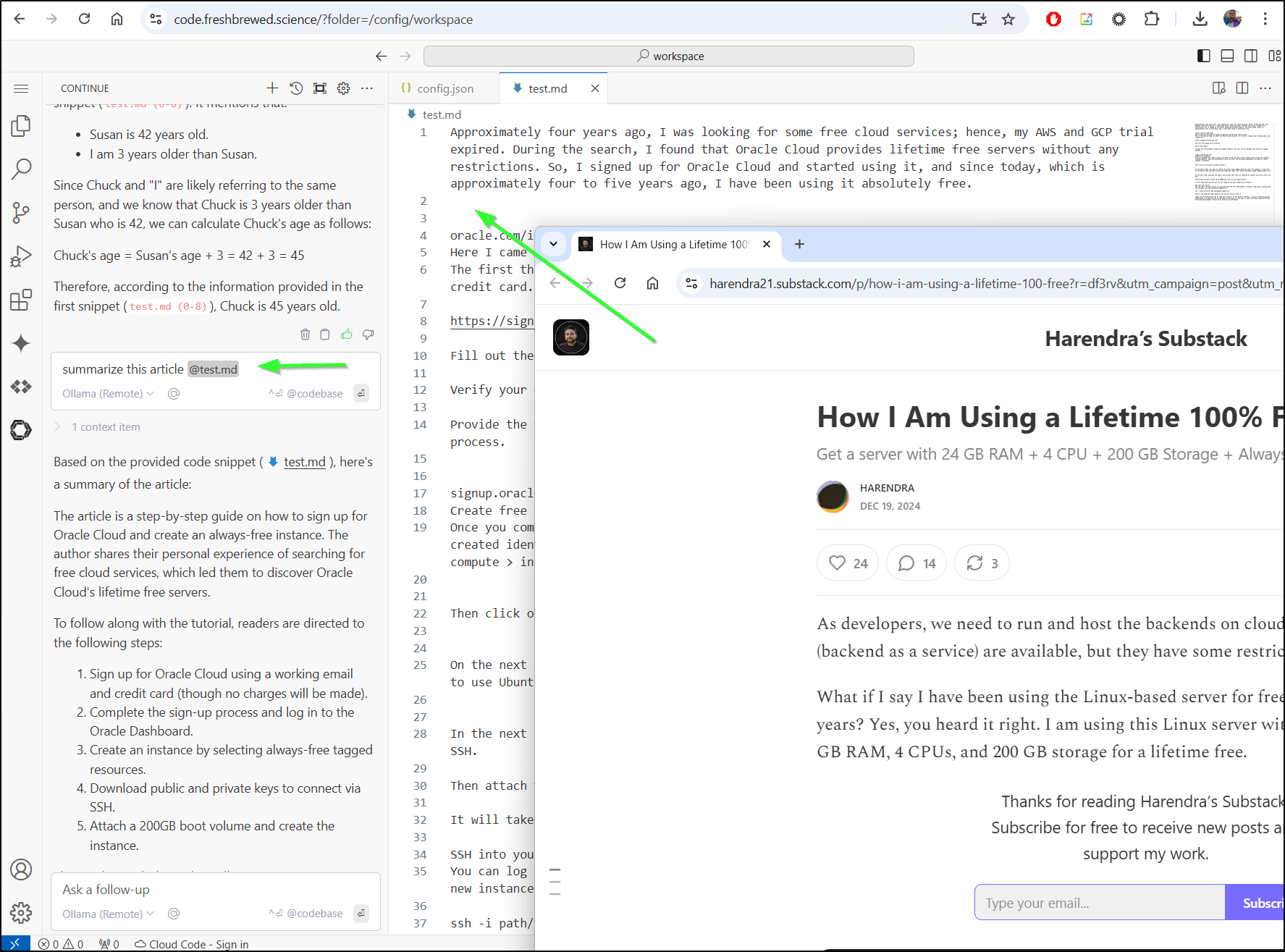
I mean, there is as much a chance of me using Oracle Cloud as buying a Tesla at this point, but still, an interesting point of view.
Externalizing
I cannot really restrict by API key, but I can expose on a different port just for me.
Let’s punch out 12434 as an external port we can forward
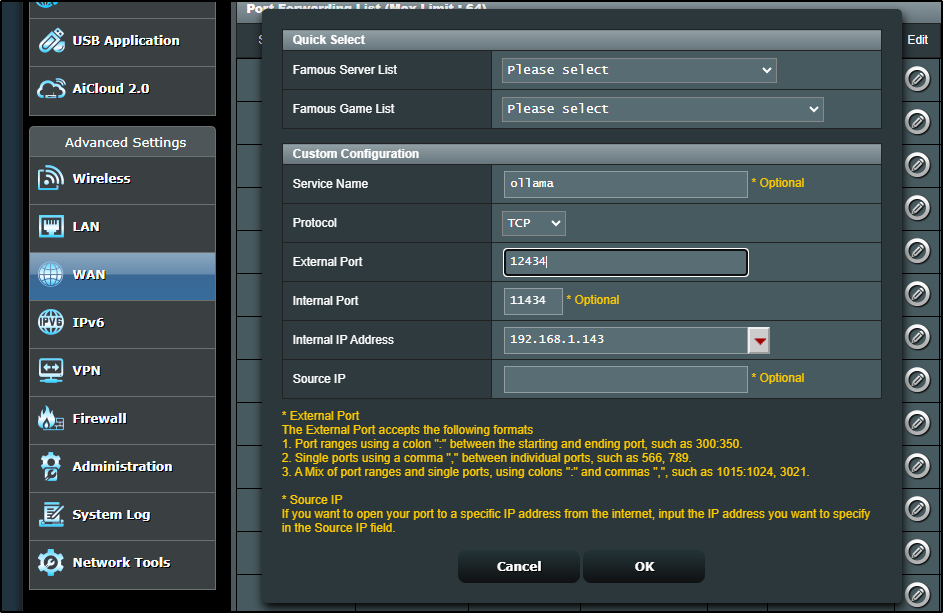
I’ll then add a block that uses my external IP
and I can see it works
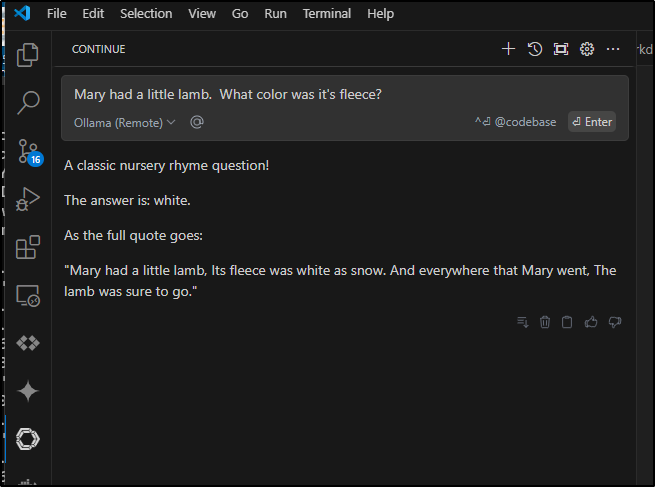
Here we can see it in use
Mistral
We can use other models as well. I showed a quick example above with the Lllama3.1 405b model. We can see that it works well and is fast.
Next, let’s use Mistral AI (at the free experiment tier)
I’ll need to signup which requires a phone MFA
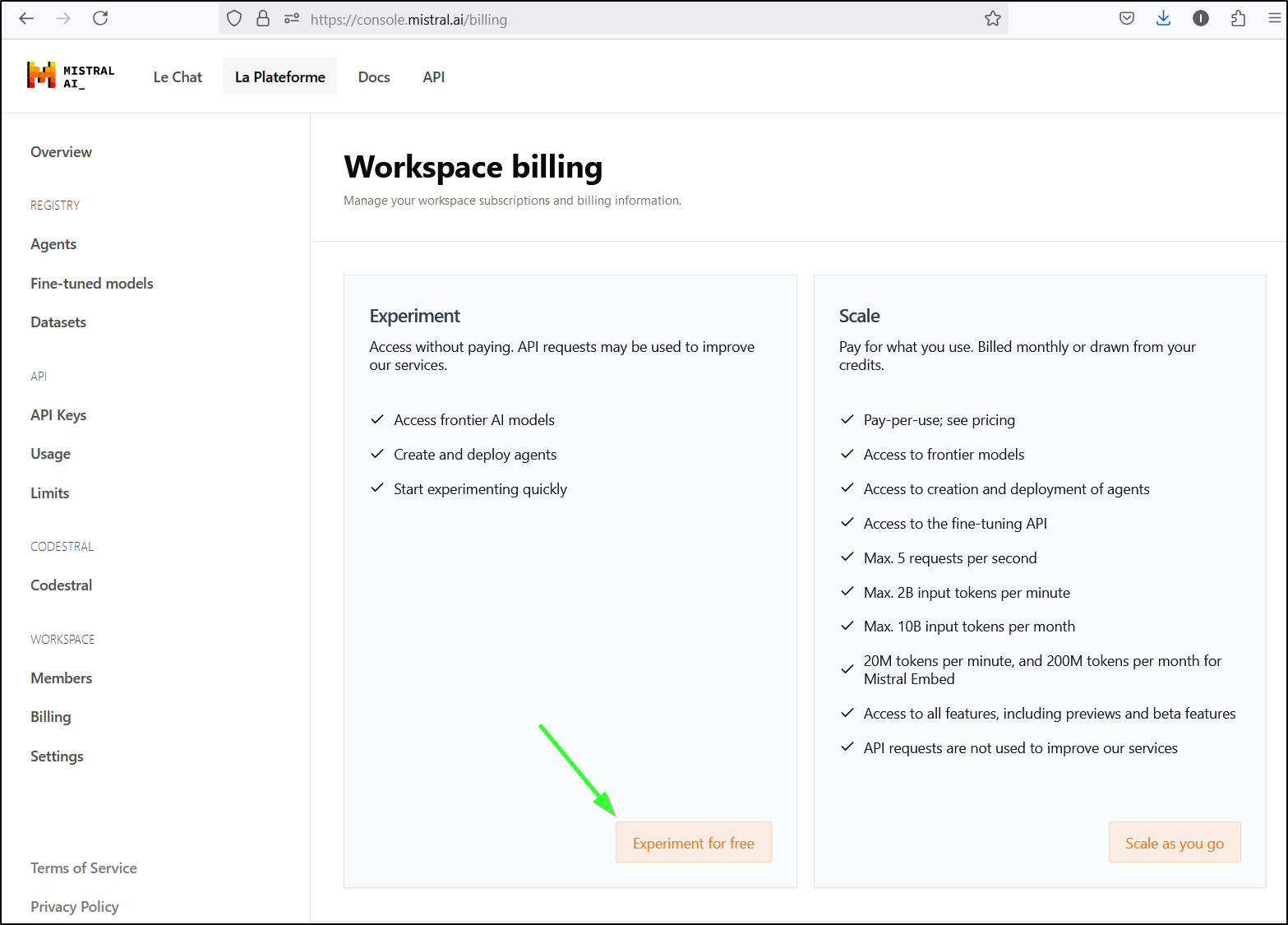
I can then pick the free Experiment Tier
And then create a new API Key
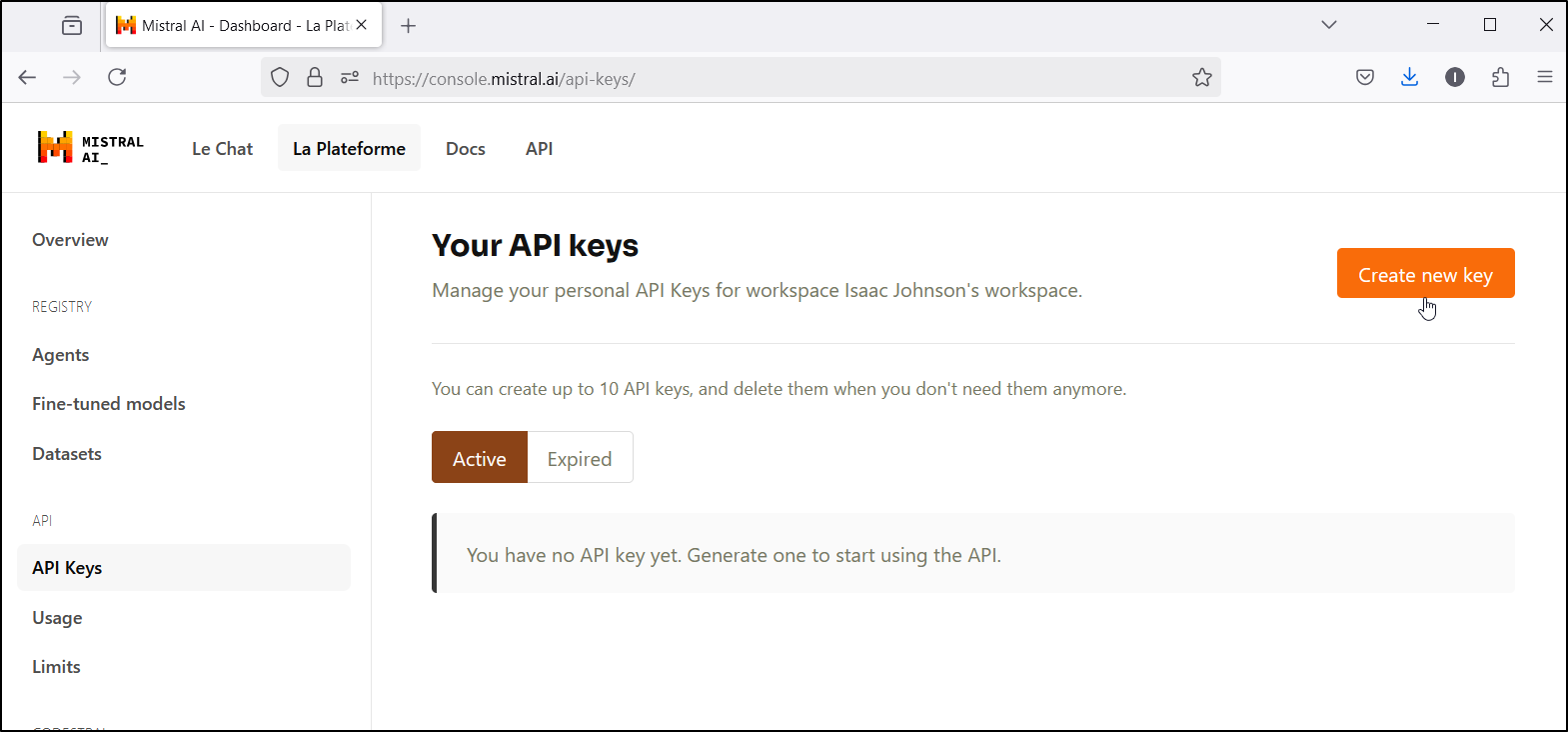
I can give it a name and an optional expiration date
It shows me the key which I can now use to add Mistral to Continue
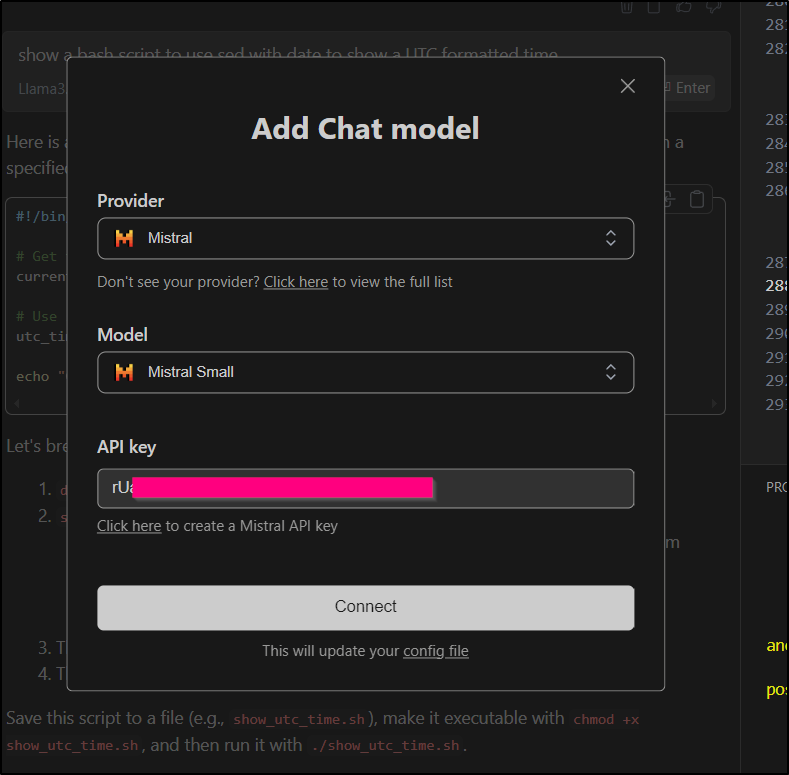
Then query Mistral for the same prompt
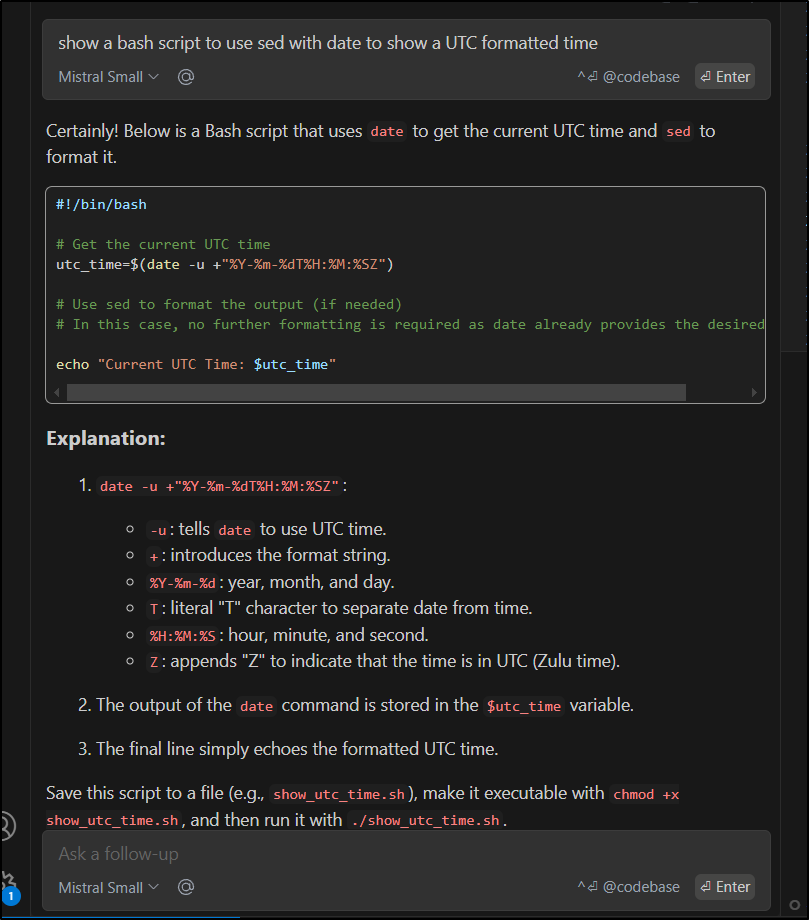
It was pretty fast and gave me the same response as my Ollama did
Summary
Today we explored the use of Ollama as an AI Coding Assistant by leveraging the Continue.dev extension with VS Code. We handled this a few different ways including running Ollama locally on my Windows box in WSL as well as on a dedicated Linux host in my network. I showed the configuration options for Continue and the different kinds of performance we can expect.
I also showed tying continue to Ollama by leveraging a CodeServer instance that runs in my Kubernetes. This would allow me to Code with AI using a tablet or Chromebook or any remote computer with web access. Speaking of which, I also showed how to expose the Ollama instance externally through my networks firewall so I can use my AI wherever I go.
Lastly, I showed how to leverage various models and providers in Continue and how to integrate them into my coding workflow. This would allow me to experiment with different approaches and techniques for solving problems using AI.
Overall, this was a great introduction to Ollama and its capabilities as an AI Coding Assistant. I hope you enjoyed it too!
