

Published: Jul 27, 2023 by Isaac Johnson
I’ve known of the Github CLI for some time but have yet to really try it out. Today we will setup and use the Github CLI and then leverage it to create an ansible automation to auto-merge and auto-sync PRs in a Repo.
Installation
There is a fat binary we can download. However, I prefer to use homebrew when ever able.
$ brew install gh
Running `brew update --auto-update`...
Installing from the API is now the default behaviour!
You can save space and time by running:
brew untap homebrew/core
==> Auto-updated Homebrew!
Updated 1 tap (homebrew/core).
==> New Formulae
pgrok pop quictls
You have 39 outdated formulae installed.
==> Fetching gh
==> Downloading https://ghcr.io/v2/homebrew/core/gh/manifests/2.32.0
################################################################################################################################################################# 100.0%
==> Downloading https://ghcr.io/v2/homebrew/core/gh/blobs/sha256:29e28fa5e58200be7ec206ded0b7a4f3b0296fb0a14da2c41c8b3e2216366617
################################################################################################################################################################# 100.0%
==> Pouring gh--2.32.0.x86_64_linux.bottle.tar.gz
==> Caveats
Bash completion has been installed to:
/home/linuxbrew/.linuxbrew/etc/bash_completion.d
==> Summary
🍺 /home/linuxbrew/.linuxbrew/Cellar/gh/2.32.0: 189 files, 39.8MB
==> Running `brew cleanup gh`...
Disable this behaviour by setting HOMEBREW_NO_INSTALL_CLEANUP.
Hide these hints with HOMEBREW_NO_ENV_HINTS (see `man brew`).
Windows users could use choco upgrade gh
PS C:\WINDOWS\system32> choco upgrade gh
Chocolatey v0.10.15
Upgrading the following packages:
gh
By upgrading you accept licenses for the packages.
gh is not installed. Installing...
gh v2.32.0 [Approved]
gh package files upgrade completed. Performing other installation steps.
The package gh wants to run 'chocolateyInstall.ps1'.
Note: If you don't run this script, the installation will fail.
Note: To confirm automatically next time, use '-y' or consider:
choco feature enable -n allowGlobalConfirmation
Do you want to run the script?([Y]es/[A]ll - yes to all/[N]o/[P]rint): A
Installing 64-bit gh...
gh has been installed.
gh may be able to be automatically uninstalled.
Environment Vars (like PATH) have changed. Close/reopen your shell to
see the changes (or in powershell/cmd.exe just type `refreshenv`).
The upgrade of gh was successful.
Software installed as 'MSI', install location is likely default.
Chocolatey upgraded 1/1 packages.
See the log for details (C:\ProgramData\chocolatey\logs\chocolatey.log).
If you neglect to use an Admin shell, expect errors
...
Access to the path 'C:\ProgramData\chocolatey\lib-bad' is denied.
Maximum tries of 3 reached. Throwing error.
Cannot create directory "C:\ProgramData\chocolatey\lib-bad". Error was:
System.UnauthorizedAccessException: Access to the path 'C:\ProgramData\chocolatey\lib-bad' is denied.
...
Usage
We first need to login.
By default, this is an interactive process
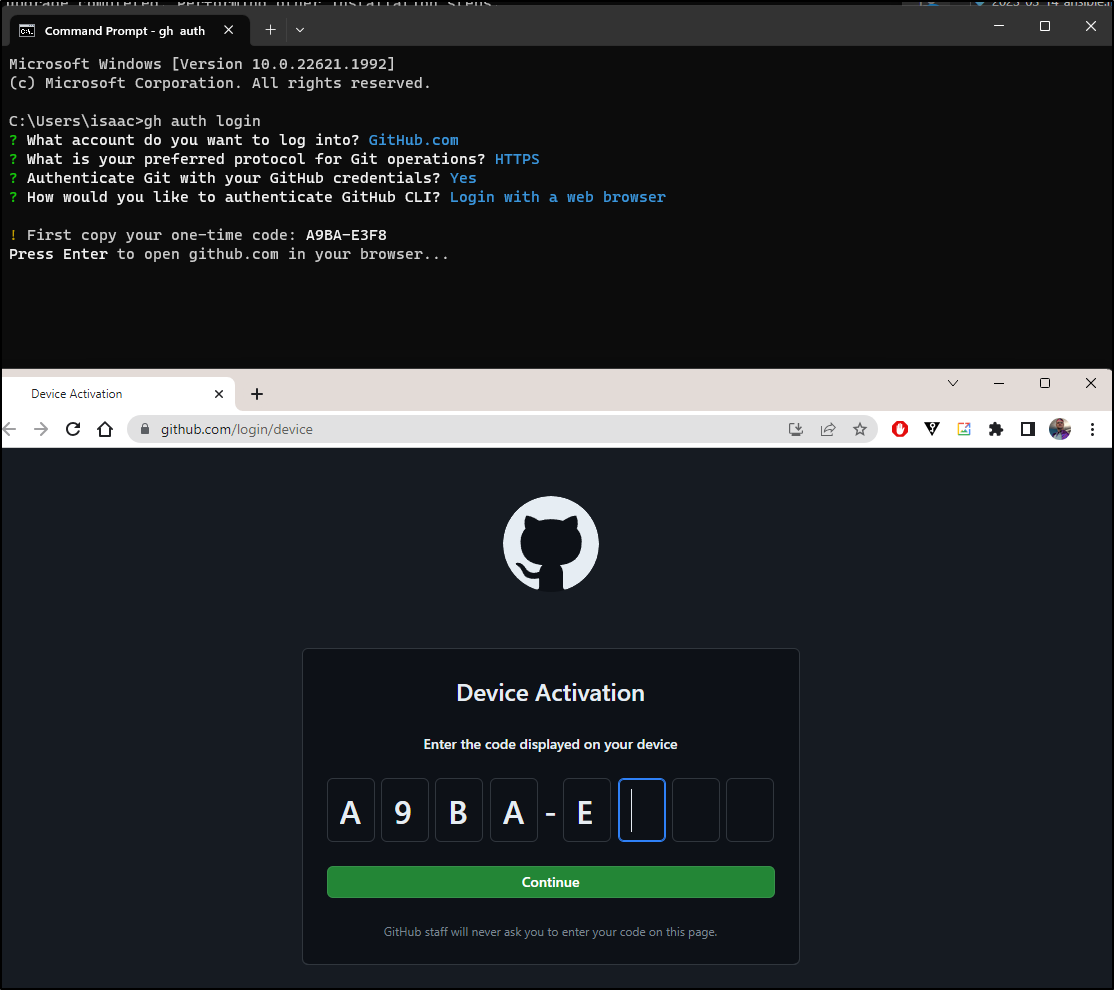
We then authorize the GH client
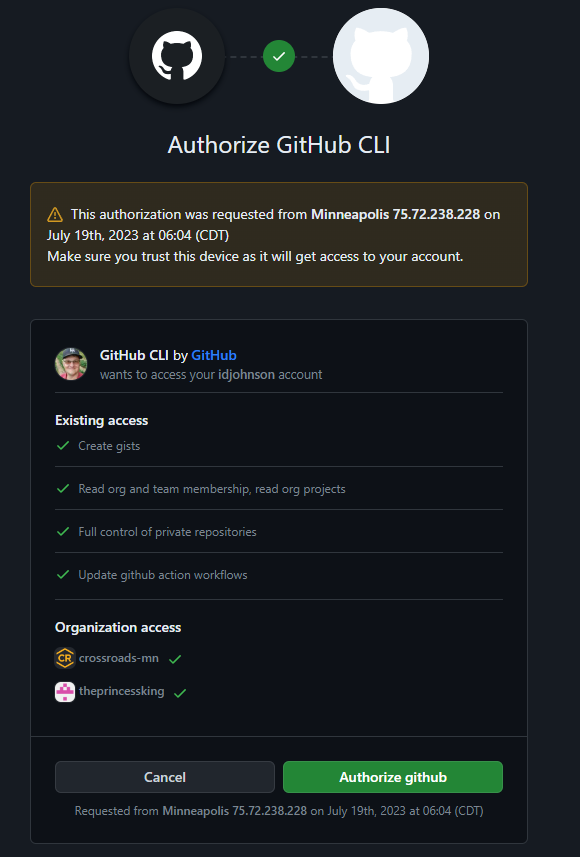
Which for me includes MFA
We are then logged in
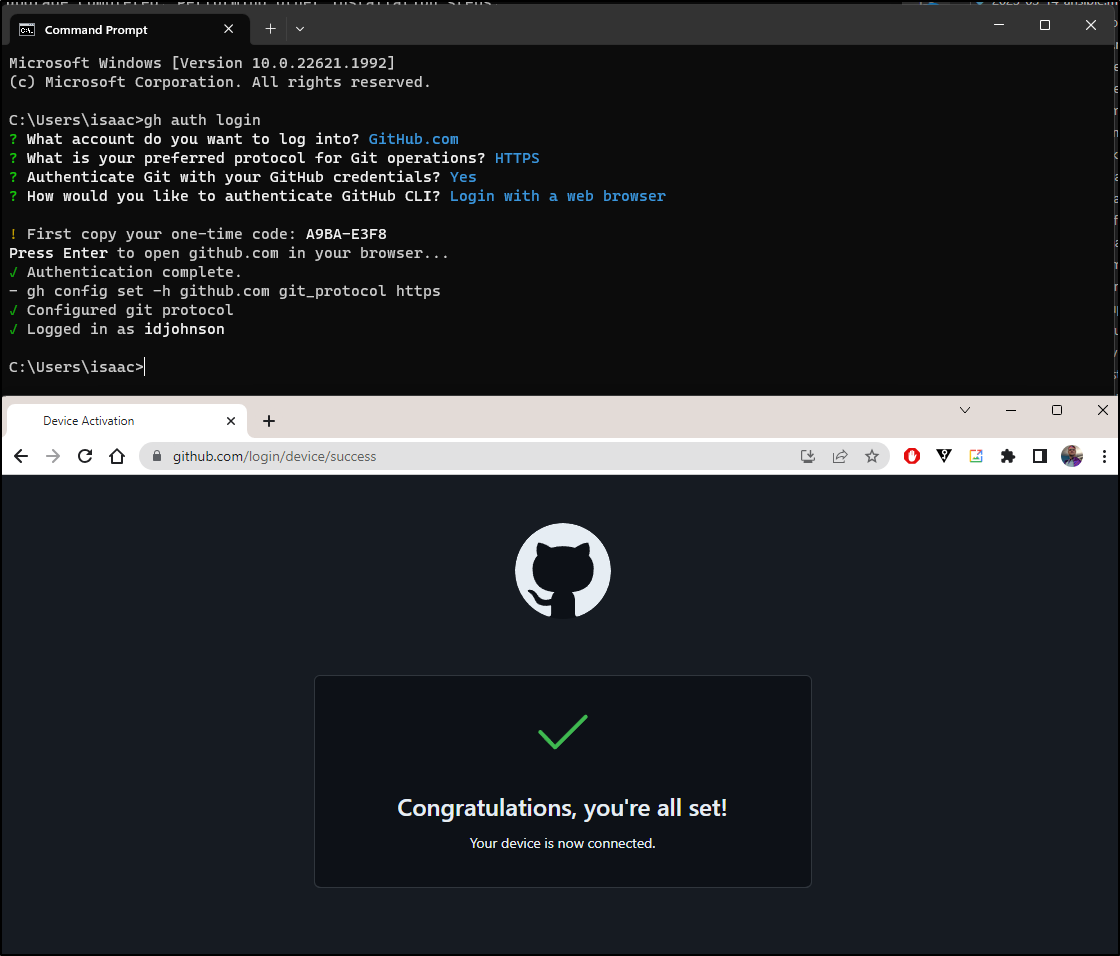
The other way to login is to use a token. The documentation really does not cover scopes so I’ll use the classic tokens
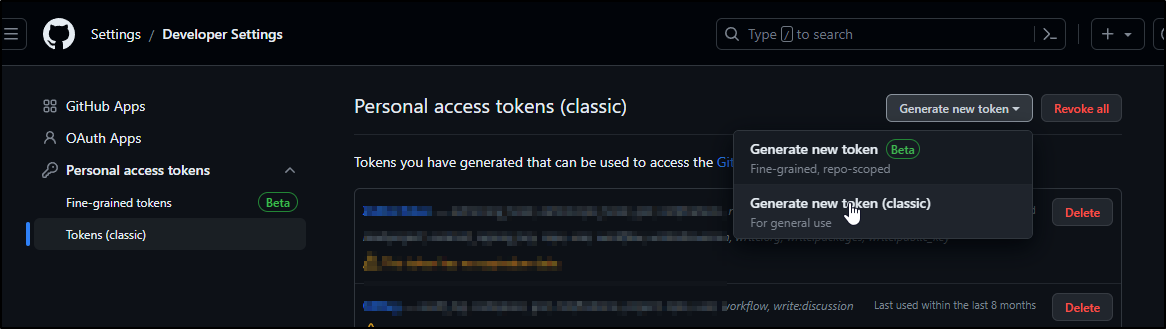
I can then just export the env var to use the client without an explicit login
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ export GITHUB_TOKEN=ghp_asdfasdfasfdasdfsadfasdf
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ gh pr list
Showing 1 of 1 open pull request in idjohnson/jekyll-blog
#216 2023-07-20 - Configure8 part 3 2023-07-configure8-part3 about 2 days ago
My PR flow does a test build of the blog post which accounts for one of the checks.
We can view the next blog post using the pr view option
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ gh pr view 216
2023-07-20 - Configure8 part 3 #216
Open • idjohnson wants to merge 4 commits into main from 2023-07-configure8-part3 • about 2 days ago
+453 -2 • ✓ Checks passing
No description provided
View this pull request on GitHub: https://github.com/idjohnson/jekyll-blog/pull/216
There are a lot of other details, however, we can fetch
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ gh pr view 216 --json
Specify one or more comma-separated fields for `--json`:
additions
assignees
author
autoMergeRequest
baseRefName
body
changedFiles
closed
closedAt
comments
commits
createdAt
deletions
files
headRefName
headRefOid
headRepository
headRepositoryOwner
id
isCrossRepository
isDraft
labels
latestReviews
maintainerCanModify
mergeCommit
mergeStateStatus
mergeable
mergedAt
mergedBy
milestone
number
potentialMergeCommit
projectCards
projectItems
reactionGroups
reviewDecision
reviewRequests
reviews
state
statusCheckRollup
title
updatedAt
url
For instance, perhaps I want to see the base ref and head ref
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ gh pr view 216 --json baseRefName
{
"baseRefName": "main"
}
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ gh pr view 216 --json headRefName
{
"headRefName": "2023-07-configure8-part3"
}
So let’s say I wanted to bring my PR up to date in a scripted way. I could easily see doing that with a
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ export TMPBASENAME=`gh pr view 216 --json baseRefName | jq -r .baseRefName`
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ export TMBHEADNAME=`gh pr view 216 --json headRefName | jq -r .headRefName`
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ git checkout $TMPBASENAME
Switched to branch 'main'
Your branch is up to date with 'origin/main'.
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ git pull
Already up to date.
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ git checkout $TMBHEADNAME
Switched to branch '2023-07-configure8-part3'
Your branch is up to date with 'origin/2023-07-configure8-part3'.
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ git merge $TMPBASENAME
Already up to date.
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ git push
Everything up-to-date
If I want the title and description I just need to query for title and body.
I wanted to use the query option, but the docs are a bit misleading
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ gh pr view 216 --query .body
unknown flag: --query
Usage: gh pr view [<number> | <url> | <branch>] [flags]
Flags:
-c, --comments View pull request comments
-q, --jq expression Filter JSON output using a jq expression
--json fields Output JSON with the specified fields
-t, --template string Format JSON output using a Go template; see "gh help formatting"
-w, --web Open a pull request in the browser
You need to specify json and query, and in the right order and both with the param to work
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ gh pr view 216 -q .body
cannot use `--jq` without specifying `--json`
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ gh pr view 216 -q '.body'
cannot use `--jq` without specifying `--json`
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ gh pr view 216 --json -q '.body'
accepts at most 1 arg(s), received 2
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ gh pr view 216 --jq '.body'
cannot use `--jq` without specifying `--json`
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ gh pr view 216 --json --jq '.body'
accepts at most 1 arg(s), received 2
# working
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ gh pr view 216 -q '.body' --json body
This is my Description
I could imagine setting a date string in the body.
I could then check for that with a bit of grep sed
$ gh pr view 216 -q '.body' --json body | grep 'post: ' | sed 's/^post: //' | tr -d '\n'
2023-07-20
Perhaps a bit of bash
$ cat t4.sh
#!/bin/bash
export PRNUM=216
if [[ "`gh pr view $PRNUM -q '.body' --json body | grep 'post: ' | sed 's/^post: //' | tr -d '\n'`" == "`date +%Y-%m-%d | tr -d '\n'`" ]]; then
echo "TODAY!"
else
echo "Not Today"
fi
If I run as it stands, it would say not today
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ ./t4.sh
Not Today
As I tested, I realized new lines would be a problem
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ gh pr view 216 --json body
{
"body": "asdfasdf\r\npost: 2023-07-19\r\nOther notes"
}
It made it a bit more complicated, but I could still do the check if I was set on the date format
#!/bin/bash
export PRNUM=216
export NOWD=`date +%Y-%m-%d | tr -d '\n'`
export DATES=`gh pr view 216 --json body | jq -r .body | grep 'post: ' | sed 's/.*post: \(....-..-..\).*/\1/g' | tr -d '\n'`
if [[ "$DATES" == "$NOWD" ]]; then
echo "TODAY!"
else
echo "Not Today"
fi
Ansible
My next step is to create an Ansible playbook.
I did add homebrew to the host so that isn’t covered. However, adding and updating gh via brew is.
$ cat checkForBlogPosts.yaml
- name: Check for Blog Posts
hosts: all
tasks:
- name: Check For Dir
stat:
path: /tmp/jekyll
register: register_ghco
- name: Checkout Blog Repo if DNE
command: git clone https://idjohnson:@github.com/idjohnson/jekyll-blog.git /tmp/jekyll
when: not register_ghco.stat.exists
- name: go to main and update
ansible.builtin.shell: |
cd /tmp/jekyll && git checkout main && git pull
- name: Transfer the script
copy: src=findAndMergeBlogPosts.sh dest=/tmp mode=0755
# use ACTION=dryrun or ACTION=DOIT
- name: Install GH CLI
ansible.builtin.shell: |
eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"
NONINTERACTIVE=1 brew install gh
args:
chdir: /tmp
- name: Check for PRs
ansible.builtin.shell: |
eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"
./findAndMergeBlogPosts.sh /tmp/jekyll
args:
chdir: /tmp
I then added the findAndMergeBlogPosts.sh script
$ cat findAndMergeBlogPosts.sh
#!/bin/bash
set -x
cd $1
export GITHUB_TOKEN="$2"
for PNUM in `gh pr list --json number -q '.[] | .number'`; do
echo "PNUM: $PNUM"
export NOWD=`date +%Y-%m-%d | tr -d '\n'`
export DATES=`gh pr view $PNUM --json body | jq -r .body | grep 'post: ' | sed 's/.*post: \(....-..-..\).*/\1/g' | tr -d '\n'`
if [[ "$DATES" == "$NOWD" ]]; then
echo "TODAY!"
else
echo "Not Today"
fi
done
exit
I added the Template to AWX
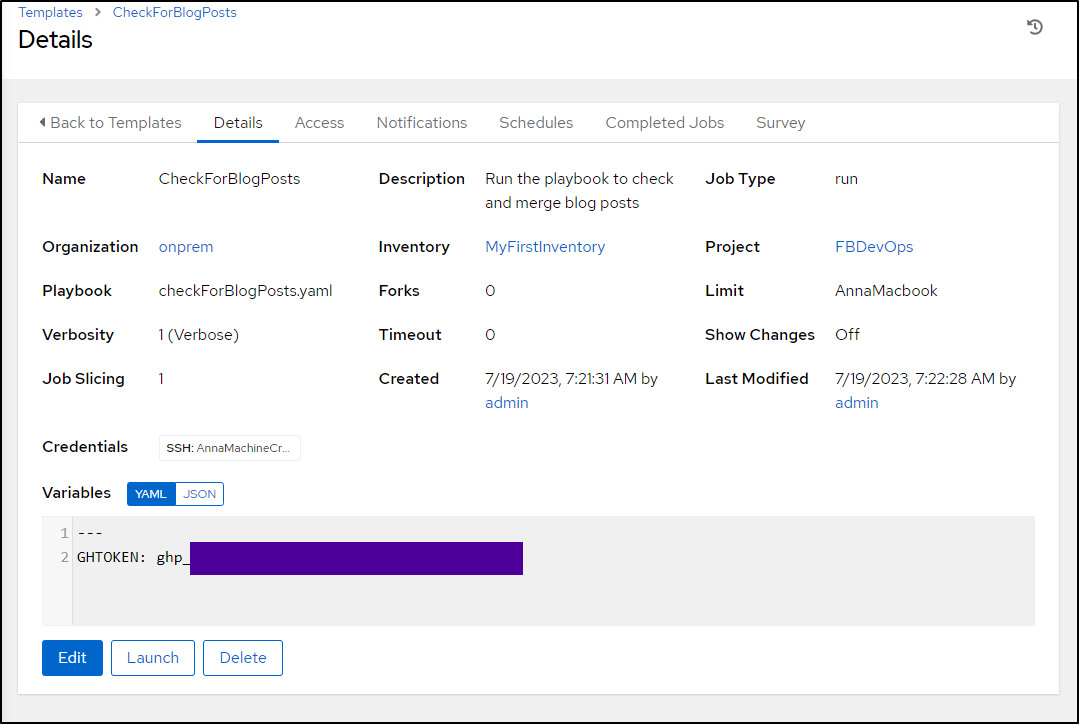
So today, as I write, it’s now the 20th so the date does not match what I still have in the PR.
Thus, it reports “Not Today”:
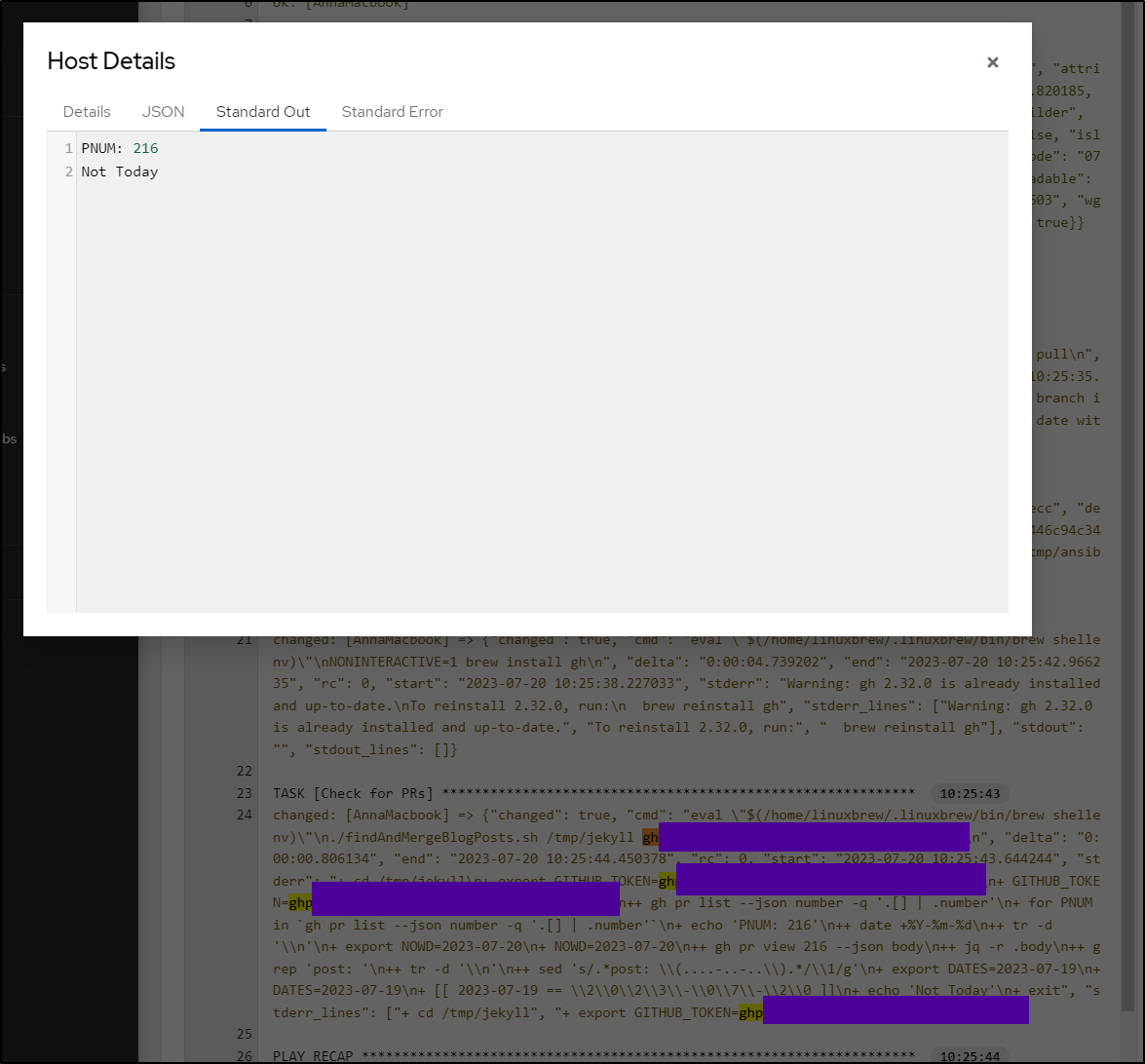
However, if I update the comment to today’s date, it finds it
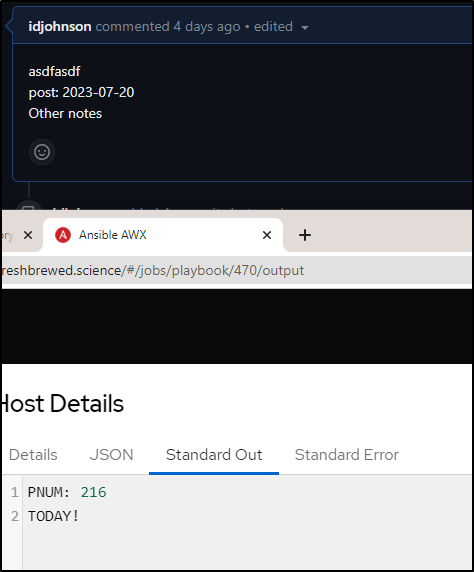
Make it so
Lastly, I updated the script to make it actually merge when a date was found to match
#!/bin/bash
cd $1
set +x
export GITHUB_TOKEN="$2"
set -x
for PNUM in `gh pr list --json number -q '.[] | .number'`; do
echo "PNUM: $PNUM"
export NOWD=`date +%Y-%m-%d | tr -d '\n'`
export DATES=`gh pr view $PNUM --json body | jq -r .body | grep 'post: ' | sed 's/.*post: \(....-..-..\).*/\1/g' | tr -d '\n'`
if [[ "$DATES" == "$NOWD" ]]; then
echo "TODAY! - merging now!"
gh pr merge $PNUM --squash
else
echo "Not Today"
fi
done
exit
To test, I’ll set a run once schedule, which if my TZ is right, should happen minutes from when I’m writing
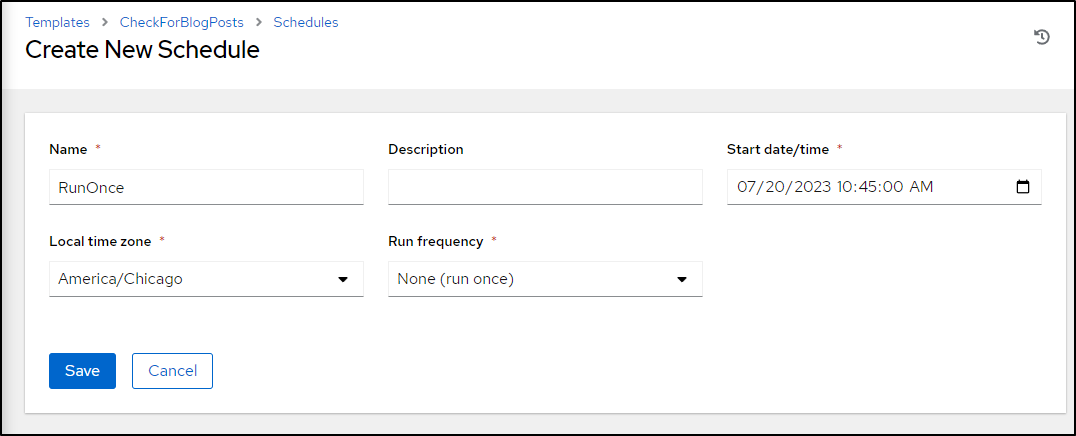
And, indeed, that got merged on the schedule we set:
AWX:

Github:
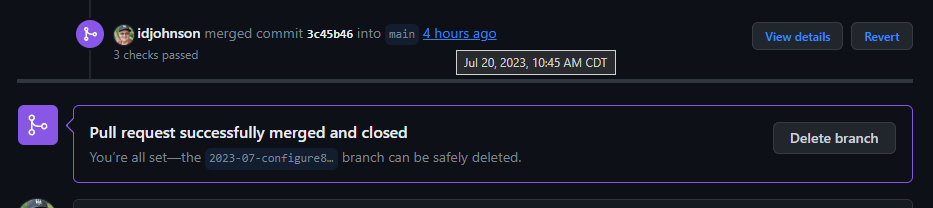
Merging up branches
I like this, but often I have multiple things in the fire at once.
I wanted to see if I could use the nightly schedule to keep candidate branches up to date (provided there were no manual merges of course)
I added a section to do a checkout, pull, checkout, merge and push using the source and destination branches for every active PR
#!/bin/bash
cd $1
set +x
export GITHUB_TOKEN="$2"
set -x
git config --global user.email isaac.johnson@gmail.com
git config --global user.name "Isaac Johnson"
for PNUM in `gh pr list --json number -q '.[] | .number'`; do
echo "PNUM: $PNUM"
# sync
export DESTBR=`gh pr view $PNUM --json baseRefName | jq -r .baseRefName`
export FROMBR=`gh pr view $PNUM --json headRefName | jq -r .headRefName`
# checkout the dest (usually main)
git checkout $DESTBR
git pull
# checkout the source branch
git checkout $FROMBR
git merge --no-edit $DESTBR
git push
# merge if time...
export NOWD=`date +%Y-%m-%d | tr -d '\n'`
export DATES=`gh pr view $PNUM --json body | jq -r .body | grep 'post: ' | sed 's/.*post: \(....-..-..\).*/\1/g' | tr -d '\n'`
if [[ "$DATES" == "$NOWD" ]]; then
echo "TODAY! - merging now!"
gh pr merge $PNUM --squash
else
echo "Not Today"
fi
done
exit
I then ran it and it indeed brought (this) branch up to date with the PR that had recently merged to main.
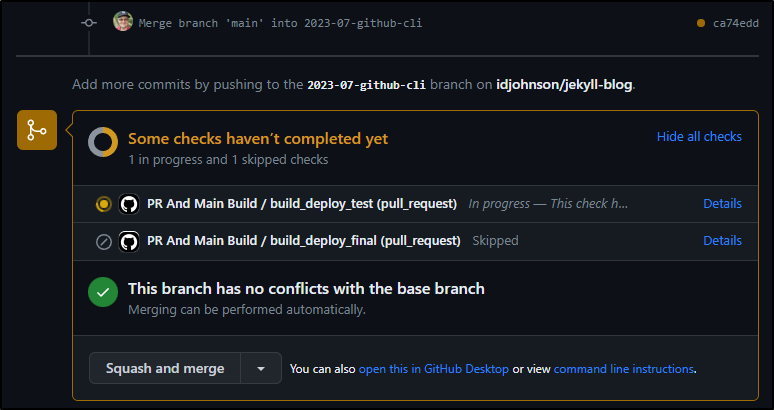
This is great - it updated the PR, which triggered a sanity build all off hours.
If I get an error, I would expect alerting to trigger and notify me through Datadog and PagerDuty.
Setting a Schedule
Now that I’m confident this will keep my branches up to date and post when the time is right, I’ll create a nightly schedule to check and merge (and post) branches.
I’ll change the schedule to match when I get up each day, that way if there is an issue, I can address it first thing after breakfast.
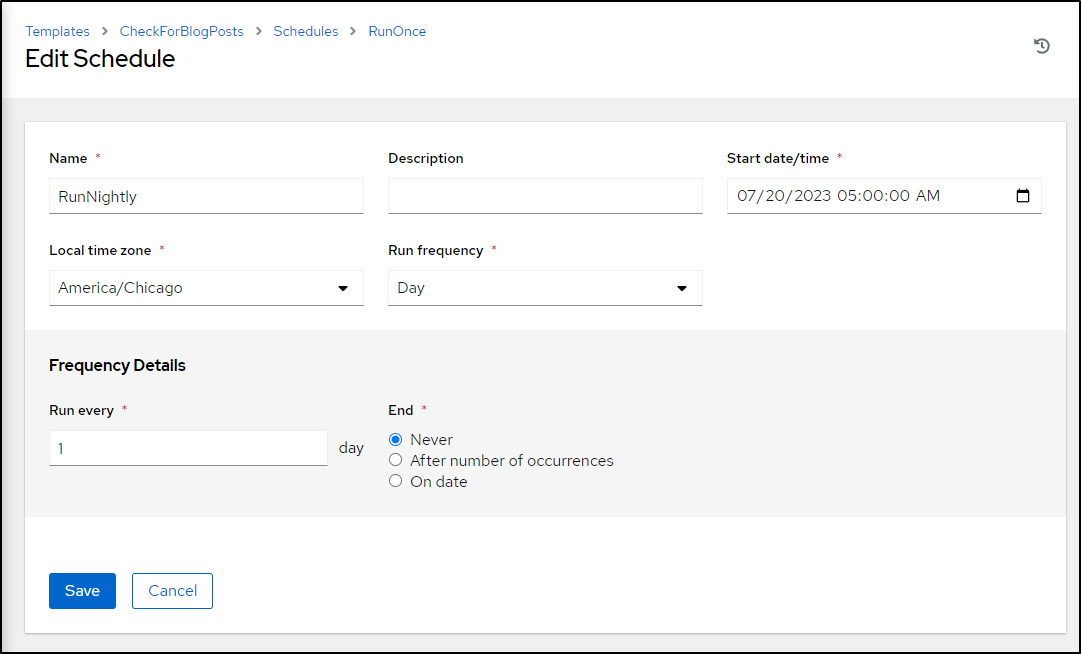
I can now see the next few runs as scheduled
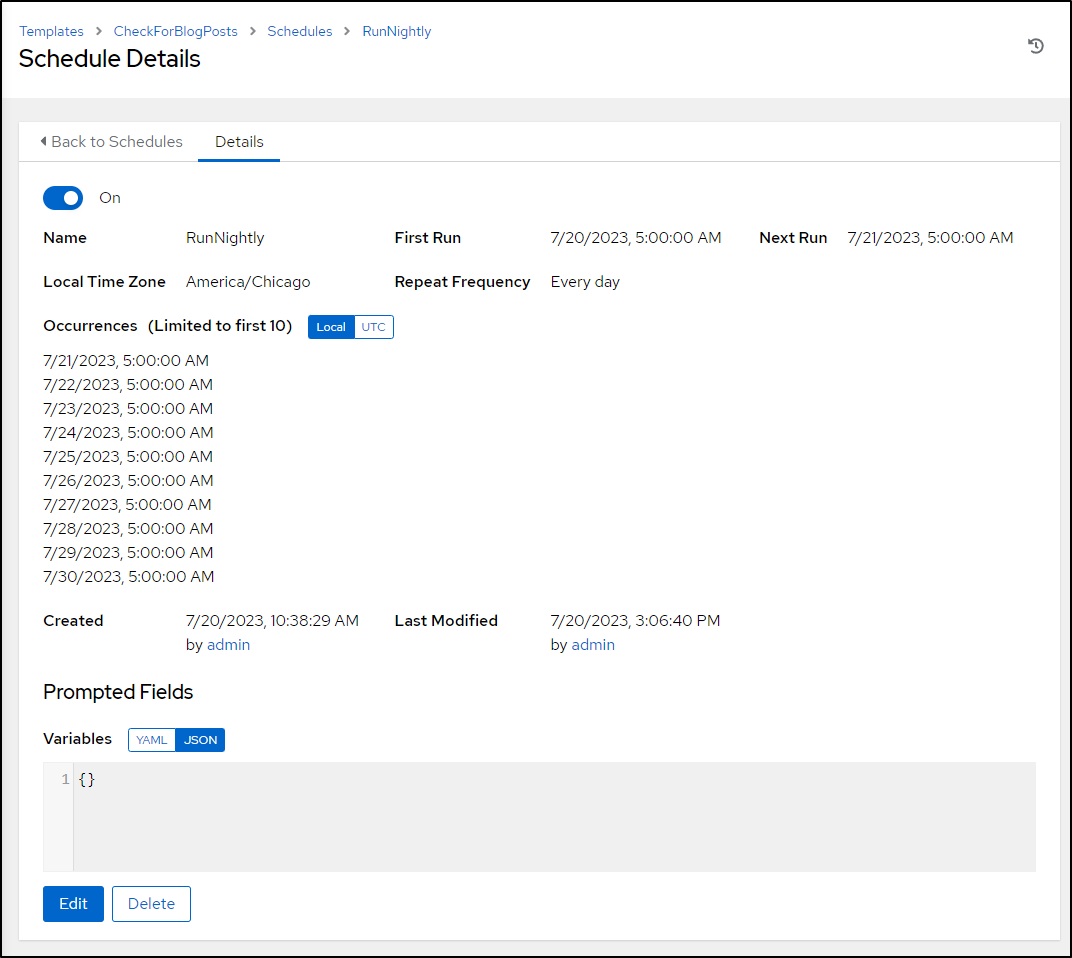
A quick fix
I did realize a logic error after the next night run
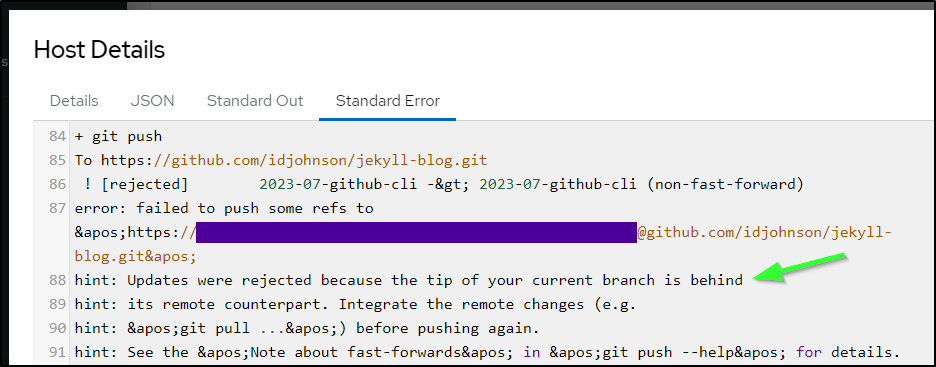
Since I do not do a fresh pull (to save time and bandwidth), I could get a local branch out of date. This branch (which is this post, mind you) was the candidate one. Thus, an existing branch was there in the /tmp/jekyll checkout and moreover, behind.
A git pull at line 24 should fix it
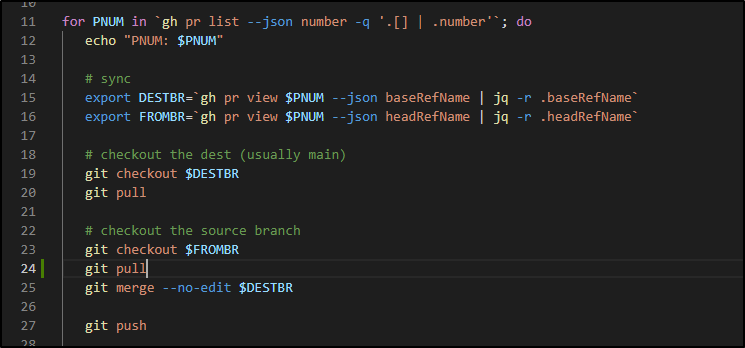
Github Action quick hit
I’m not going to create a new post for this, but a little extra for those that read this far.
I continue to try and optimize my post-rendered sync to S3. There are a lot of files created and re-syncing all of 2023’s images and screen capture mp4s takes a lot of time and bandwidth.
I usually have a step in my Github Actions workflow like this:
- name: copy files to s3 fb-test
run: |
# at this point, we can stop even checking 2019-2021 files.. soon 2022 too
aws s3 sync ./_site s3://freshbrewed-test --exclude 'content/images/2019/*' --exclude 'content/images/2020/*' --exclude 'content/images/2021/*' --exclude 'content/images/2022/*' --acl public-read
env: # Or as an environment variable
AWS_ACCESS_KEY_ID: $
AWS_SECRET_ACCESS_KEY: $
AWS_DEFAULT_REGION: $
At the very least, that trims out prior years.
On a good day, that is just shy of 3 minutes of copying files

But what if I could narrow that gap farther?
At first I worked on just hand jambing out a command line like
aws s3 sync ./_site s3://freshbrewed-test --exclude 'content/images/2019/*' --exclude 'content/images/2020/*' --exclude 'content/images/2021/*' --exclude 'content/images/2022/*' --exclude 'content/images/2023/01/*' --exclude 'content/images/2023/02/*' --exclude 'content/images/2023/03/*' --exclude 'content/images/2023/04/*' --exclude 'content/images/2023/05/*' --exclude 'content/images/2023/06/*' --acl public-read
But then that would be one more thing to update each month.
I crafted a YAML that would exclude all the months prior to this one on the current year
- name: create sync command
run: |
#!/bin/bash
# Get the current month (numerical representation)
current_month=$(date +%m)
current_year=$(date +%y)
printf "aws s3 sync ./_site s3://freshbrewed-test --exclude 'content/images/2019/*' --exclude 'content/images/2020/*' --exclude 'content/images/2021/*' --exclude 'content/images/2022/*'" > /tmp/synccmd.sh
# Loop through the months and print them up to the current month
for (( month_num=1; month_num<current_month; month_num++ )); do
printf " --exclude 'content/images/20%02d/%02d/*'" "$current_year" "$month_num" >> /tmp/synccmd.sh
done
printf " --acl public-read\n" >> /tmp/synccmd.sh
chmod 755 /tmp/synccmd.sh
- name: copy files to s3 fb-test
run: |
/tmp/synccmd.sh
env: # Or as an environment variable
AWS_ACCESS_KEY_ID: $
AWS_SECRET_ACCESS_KEY: $
AWS_DEFAULT_REGION: $
This is close, it does the job, but on the month boundary (these posts take a while to write at times), I might miss some carry-over. So best to exclude only up to two months ago.
- name: create sync command
run: |
#!/bin/bash
# Get the current month (numerical representation)
current_month=$(date +%m)
current_year=$(date +%y)
last_month=$(( $current_month - 1 ))
printf "aws s3 sync ./_site s3://freshbrewed-test --exclude 'content/images/2019/*' --exclude 'content/images/2020/*' --exclude 'content/images/2021/*' --exclude 'content/images/2022/*'" > /tmp/synccmd.sh
# Loop through the months and print them up to the current month
for (( month_num=1; month_num<last_month; month_num++ )); do
printf " --exclude 'content/images/20%02d/%02d/*'" "$current_year" "$month_num" >> /tmp/synccmd.sh
done
printf " --acl public-read\n" >> /tmp/synccmd.sh
chmod 755 /tmp/synccmd.sh
- name: copy files to s3 fb-test
run: |
/tmp/synccmd.sh
env: # Or as an environment variable
AWS_ACCESS_KEY_ID: $
AWS_SECRET_ACCESS_KEY: $
AWS_DEFAULT_REGION: $
This has shaved about a minute off my transfers and is just a handy snippet of bash to put together a proper aws s3 sync command.
Also, I hard coded current month to 1 and 2 just to ensure January and February wouldn’t create some kind of garbled mess. Indeed, for Jan and Feb, it does not add any excludes for that year. I expect that come January I’ll need to just stub out 2023, but we’ll cross that bridge later.
… However, I don’t like tech debt.. let’s solve that now
#!/bin/bash
# Get the current year and month
current_month=$(date +%m)
current_year=$(date +%Y)
last_month=$(( $current_month - 1 ))
last_year=$(( $current_year - 1 ))
if (( $current_month == 1 )); then
current_year=$last_year
current_month=12
last_month=$(( $current_month - 1 ))
fi
printf "aws s3 sync ./_site s3://freshbrewed-test" > t6.sh
for (( year=2019; year<$current_year; year++ )); do
printf " --exclude 'content/images/%04d/*'" "$year" >> t6.sh
done
# Loop through the months and print them up to the current month
for (( month_num=1; month_num<last_month; month_num++ )); do
printf " --exclude 'content/images/%04d/%02d/*'" "$current_year" "$month_num" >> t6.sh
done
printf " --acl public-read\n" >> t6.sh
There is some goofiness there in January. Had I left it without that little January Hack, all of January I would copy the whole of 2023 and that seemed a bit much. I tested this by hard coding dates from Dec thru Feb and believe it will do the job.
This means the final YAML looks as such
- name: create sync command
run: |
#!/bin/bash
# Get the current month (numerical representation)
current_month=$(date +%m)
current_year=$(date +%Y)
last_month=$(( $current_month - 1 ))
last_year=$(( $current_year - 1 ))
if (( $current_month == 1 )); then
current_year=$last_year
current_month=12
last_month=$(( $current_month - 1 ))
fi
printf "aws s3 sync ./_site s3://freshbrewed.science" > /tmp/synccmd.sh
for (( year=2019; year<$current_year; year++ )); do
printf " --exclude 'content/images/%04d/*'" "$year" >> /tmp/synccmd.sh
done
# Loop through the months and print them up to the current month
for (( month_num=1; month_num<last_month; month_num++ )); do
printf " --exclude 'content/images/%04d/%02d/*'" "$current_year" "$month_num" >> /tmp/synccmd.sh
done
printf " --acl public-read\n" >> /tmp/synccmd.sh
chmod 755 /tmp/synccmd.sh
- name: copy files to final s3 fb
run: |
/tmp/synccmd.sh
env: # Or as an environment variable
AWS_ACCESS_KEY_ID: $
AWS_SECRET_ACCESS_KEY: $
AWS_DEFAULT_REGION: $
Quick Fix
I expect this to post this morning (proving the flow), only to see an error in AWX
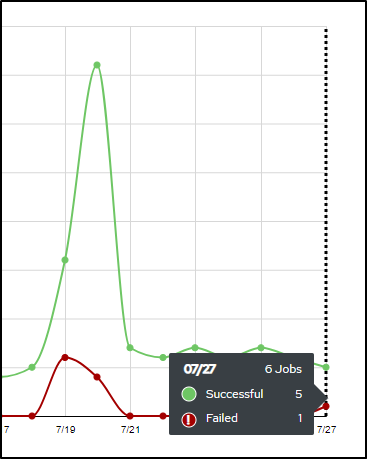
I see it failed on a modified file (I ran this just fine for Tuesday’s post)
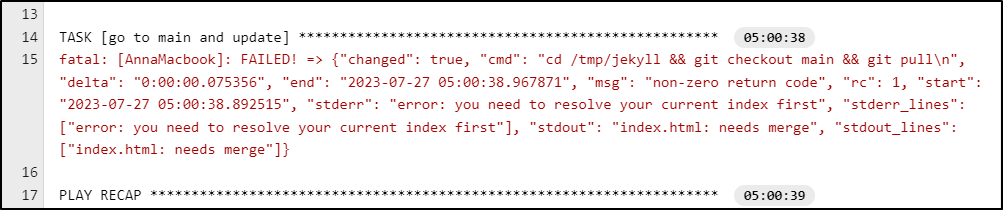
{
"msg": "non-zero return code",
"cmd": "cd /tmp/jekyll && git checkout main && git pull\n",
"stdout": "index.html: needs merge",
"stderr": "error: you need to resolve your current index first",
"rc": 1,
"start": "2023-07-27 05:00:38.892515",
"end": "2023-07-27 05:00:38.967871",
"delta": "0:00:00.075356",
"changed": true,
"invocation": {
"module_args": {
"_raw_params": "cd /tmp/jekyll && git checkout main && git pull\n",
"_uses_shell": true,
"warn": true,
"stdin_add_newline": true,
"strip_empty_ends": true,
"argv": null,
"chdir": null,
"executable": null,
"creates": null,
"removes": null,
"stdin": null
}
},
"stdout_lines": [
"index.html: needs merge"
],
"stderr_lines": [
"error: you need to resolve your current index first"
],
"_ansible_no_log": false
}
I was able to replicate locally. To make it short, I needed to add
$ git reset --hard
I added that to the playbook
builder@DESKTOP-QADGF36:~/Workspaces/ansible-playbooks$ git diff
diff --git a/checkForBlogPosts.yaml b/checkForBlogPosts.yaml
index 9b88abd..4437840 100644
--- a/checkForBlogPosts.yaml
+++ b/checkForBlogPosts.yaml
@@ -13,7 +13,7 @@
- name: go to main and update
ansible.builtin.shell: |
- cd /tmp/jekyll && git checkout main && git pull
+ cd /tmp/jekyll && git reset --hard && git checkout main && git pull
- name: Transfer the script
copy: src=findAndMergeBlogPosts.sh dest=/tmp mode=0755
and frankly, if you are reading this, it worked.
Summary
Today we walked through setting up the Github CLI and then using it to fetch PR details. I felt it would be a great opportunity to use in automations so I first setup an Ansible Playbook to check for PRs. I then expanded it to parse the description and merge on a matching date. Lastly, I added a schedule to find and merge branches on PRs to keep candidate PRs up to date.
You may think that this is a whole lot of work to build a GIT driven blog when I could just use a CMS that has “post on a date” as a feature. You are correct. But this, at least for me, is a lot more fun. And more importantly, I think using that playbook (playbook here and script here) might be a great jumping off point for someone looking to keep Github based branches up to date on a regular schedule automatically.
