

Published: Dec 15, 2021 by Isaac Johnson
Now that we have a live production workflow in Github Actions, we should explore Github Issues for Issue and Feature tracking. Can we use Github as a sufficient replacement for Azure DevOps?
Moreover, if we have our flows in Github Actions, how can we monitor and track our CI pipelines? We’ll also integrate Datadog for both event and CI tracking, walk through alert escalations with Pagerduty and discuss methods of change notification.
Lastly, we will dig into CODEOWNERS files and the basics of Github PR automated reviewers.
Project setup
First, let’s create a simple project in our repo named MyProjectBoard
This creates a straightforward Kanban board with reviews. On the right we have open Github Issues (tickets) and then the state columns into which we can drag them.
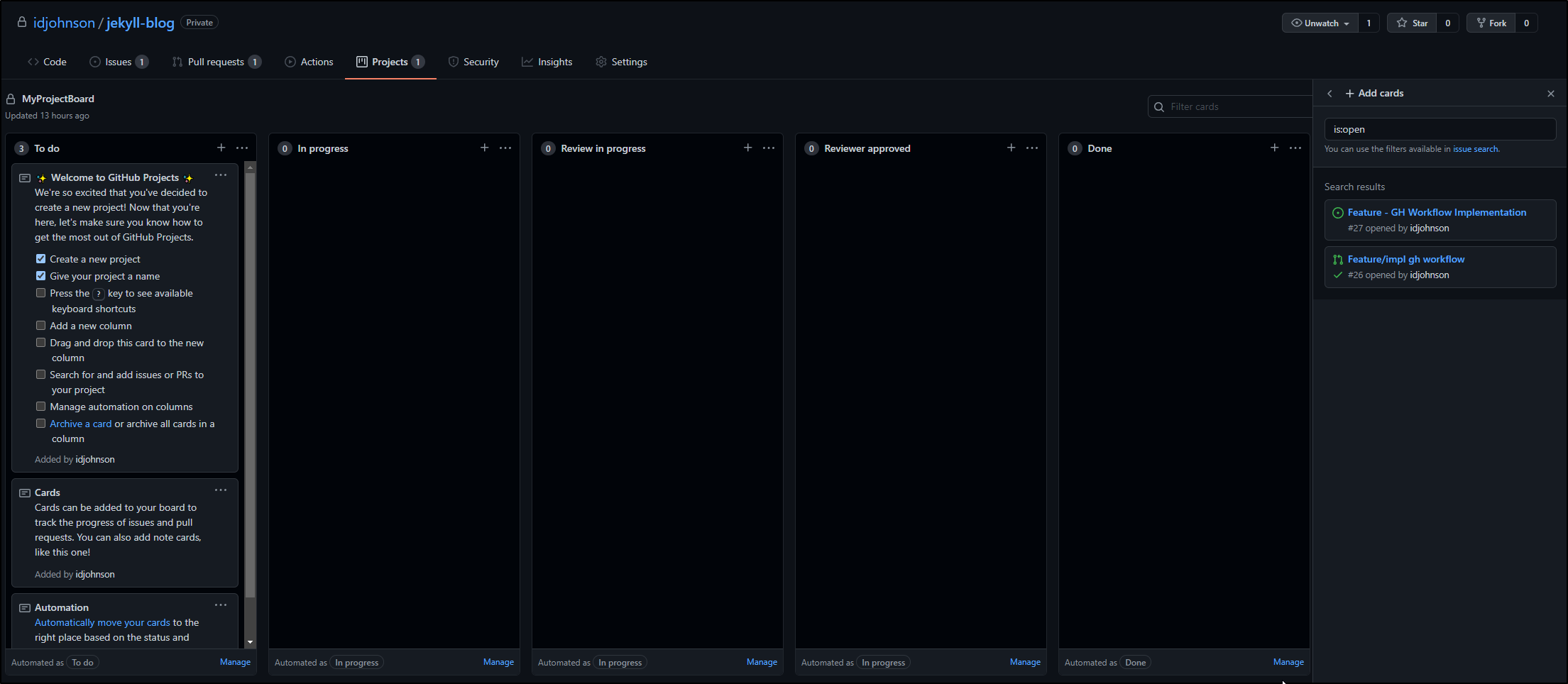
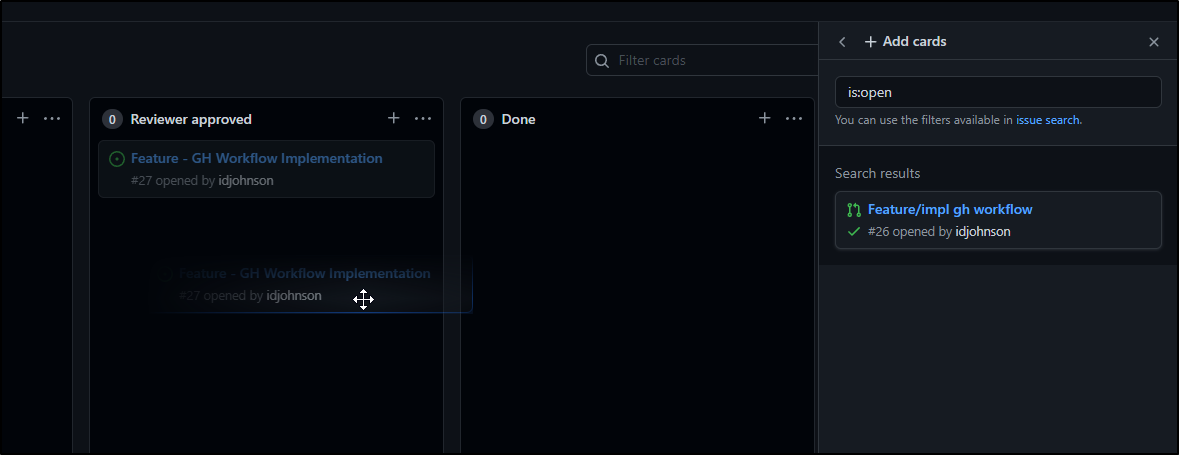
We can drag and drop issues to assign them to a state column.
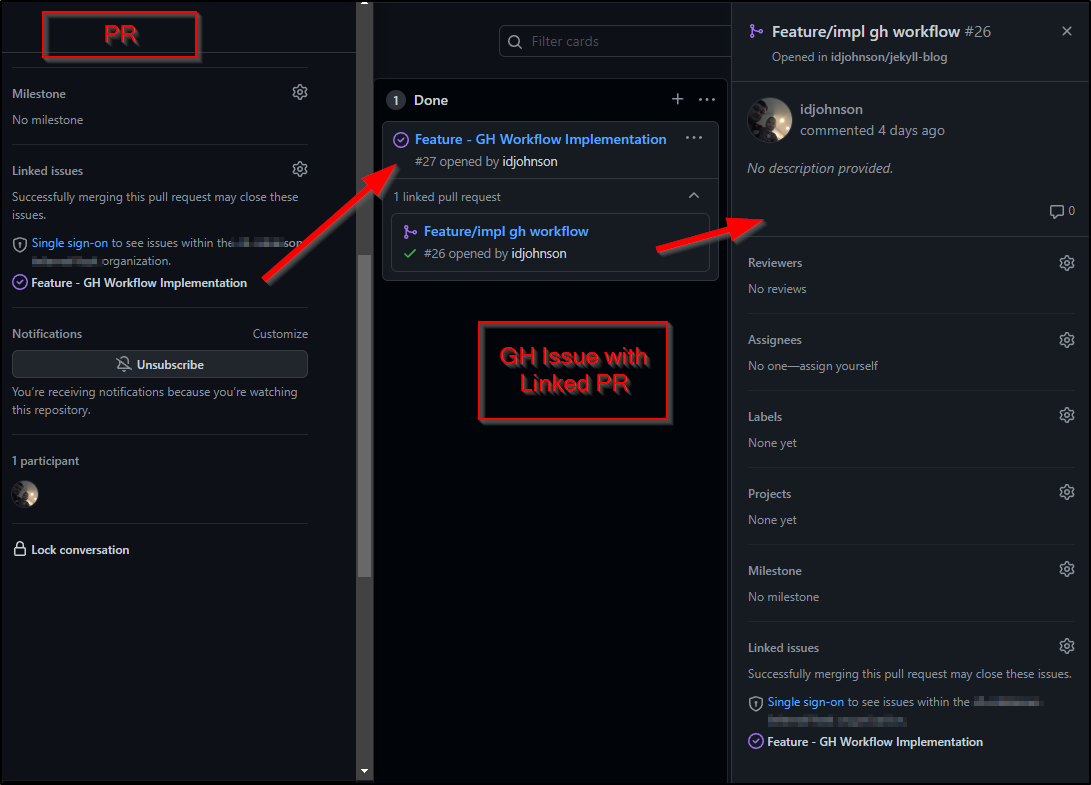
Similar to AzDO we can see the bi-directional linking of Issues and PRs:
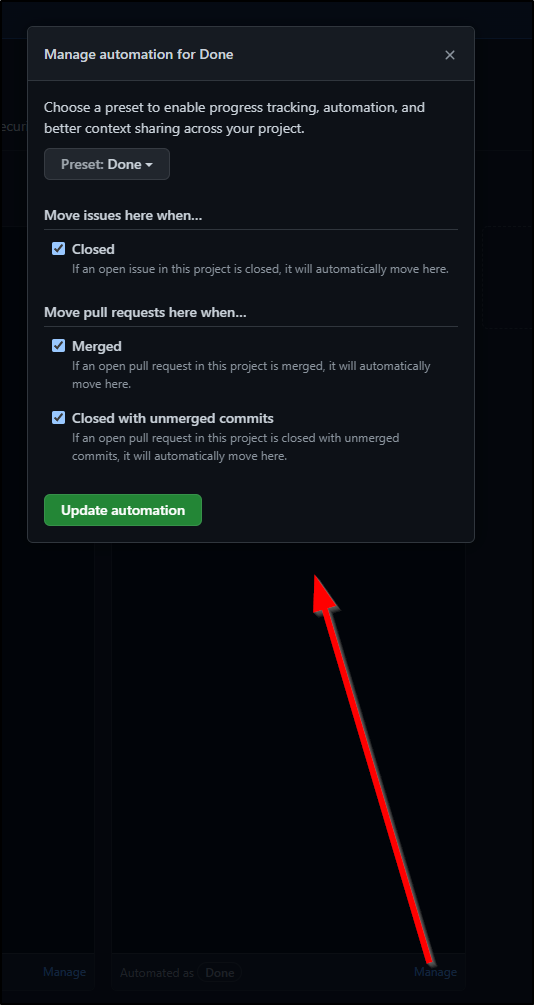
Another area we may wish to tweak is the Board Automations. Here we see what rules are in play to automatically move Issues to Done, such as being included in a PR that merges.
Labels and Milestones
The other places that we might want to adjust are Labels and Milestones.
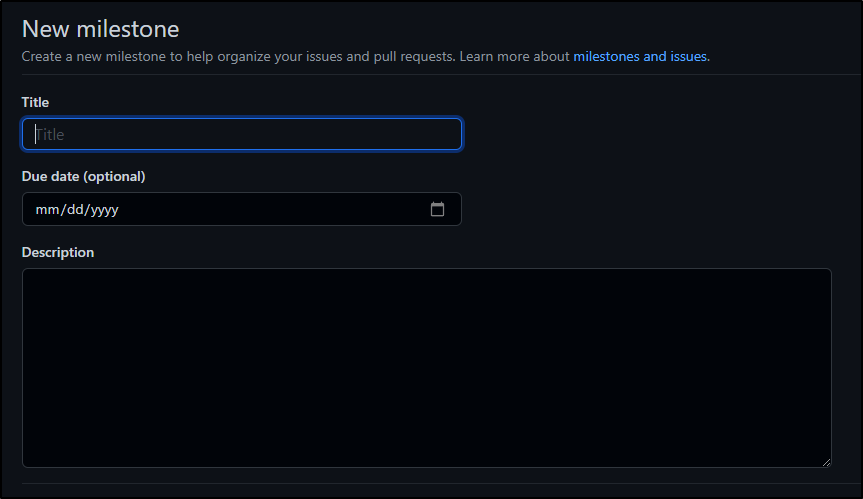
Milestones are a fancy way of saying a “Release”. It bundles PRs and Issues into an object with a release date:
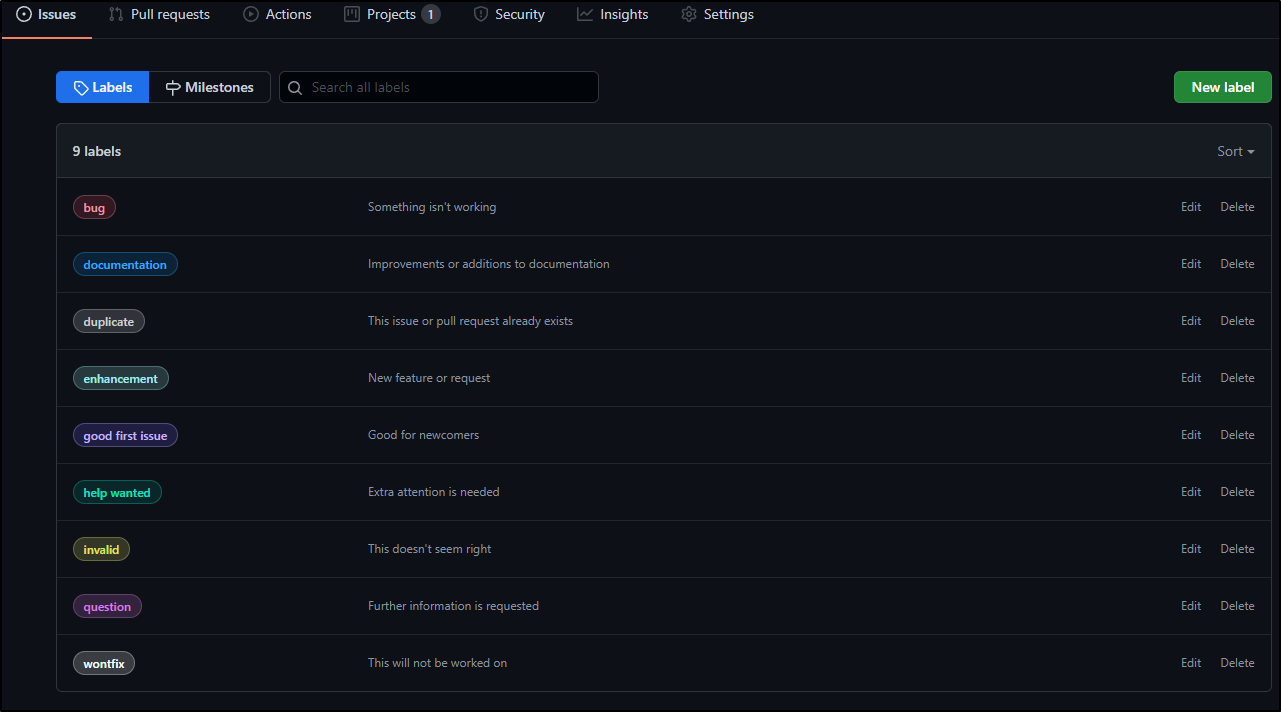
Labels (or issue tags) are a way of categorizing issues. In AzDO I would likely use an Issue type for similar things.
A quick example
A colleague of mine, Chad Prey, recently suggested I check out a project he worked on called “vCluster” that can create smaller virtual clusters in Minikube. Sort of inception-like, it seems like a cluster in a cluster (akin to k3d).
I want to start to capture these external blog suggestions into Github issues (as you recall back in June we implemented the feedback form above that creates an AzDO Work Item for such things)
Let’s first create an Issue Label for “External Suggestion”

First, I’ll do a quick note in the To-Do column to capture the suggestion
Next, we can use the drop-down to convert it to an issue.
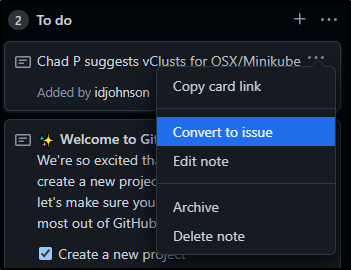
I have a thing about using YAML in issues, so for now, just go with it
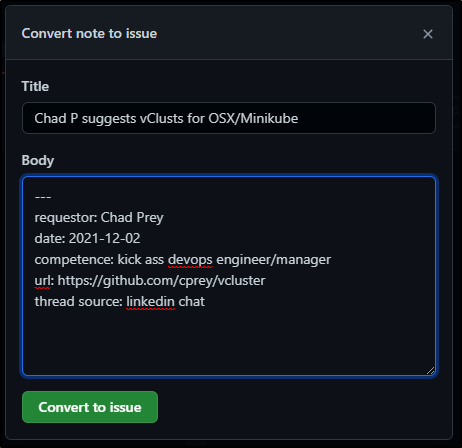
Now I can set the label on the issue from within the board:
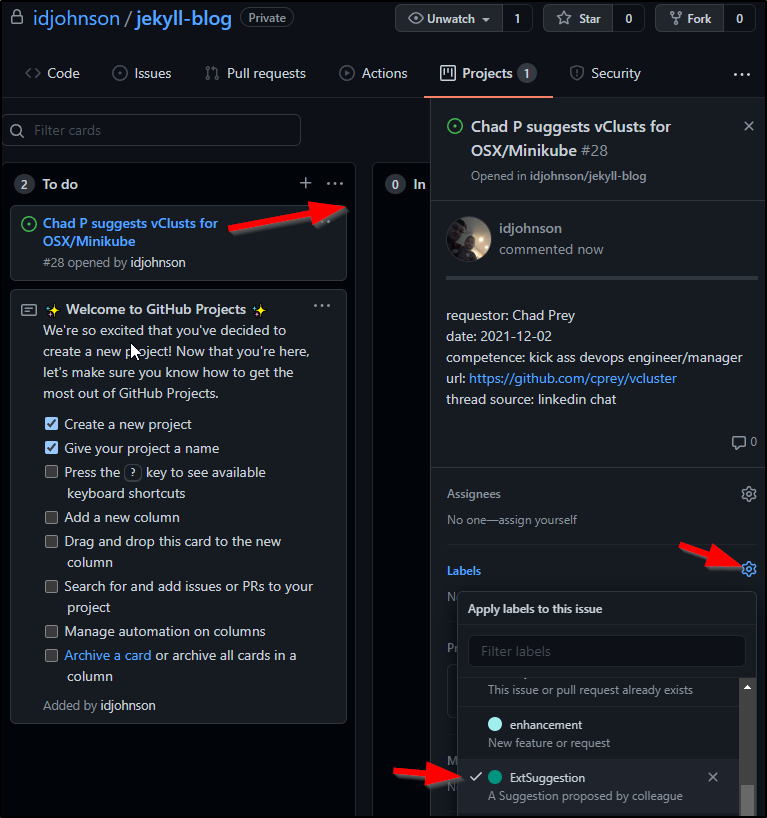
I added a not for a WIP and a ticket for this blog post so my Board now looks as such:
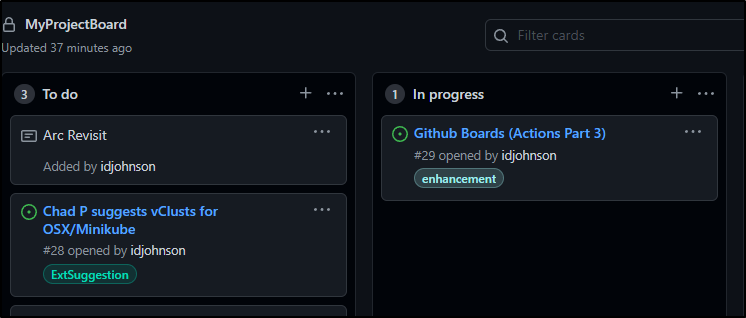
And I can see the same active tickets under Issues
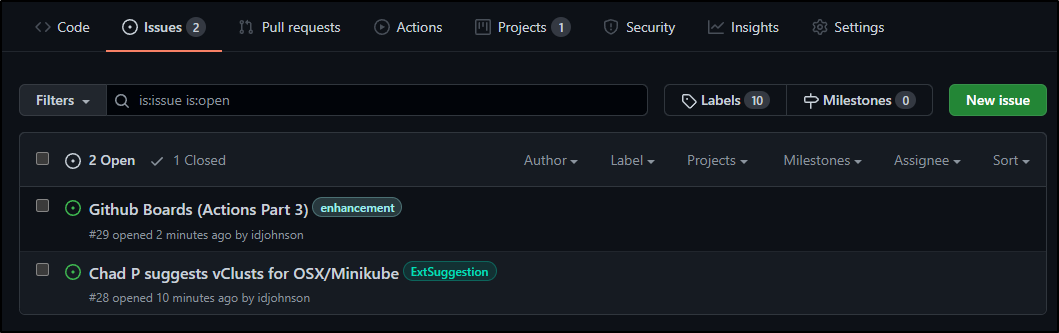
Via REST API
We can also get our GH Issues via the GH Rest API (and since this repo is private, that requires auth with our PAT or OAuth token):
$ curl -u idjohnson:$GHTOKEN -H "Accept: application/vnd.github.v3+json" https://api.github.com/repos/idjohnson/jekyll-blog/issues 2>/dev/null| jq '.[] | .title'
"Github Boards (Actions Part 3)"
"Chad P suggests vClusts for OSX/Minikube"
Since my body has YAML, i can pull the fields from that as well:
$ curl -u idjohnson:$GHTOKEN -H "Accept: application/vnd.github.v3+json" https://api.github.com/repos/idjohnson/jekyll-blog/issues 2>/dev/null| jq -r '.[] | .body' | grep 'requestor: '
requestor: self
requestor: Chad Prey
The REST API uses parameters to control field queries. So if I wanted to pull the last 10 closed issues:
$ curl -u idjohnson:$GHTOKEN -H "Accept: application/vnd.github.v3+json" https://api.github.com/repos/idjohnson/jekyll-blog/issues?state=closed 2>/dev/null| jq -r '.[] | .title' | head -n10
Feature - GH Workflow Implementation
Feature/impl gh workflow
Feature/gh actions
Feature/2021 11 24 newrelic2
Feature/2021 11 17 newrelic
Feature/2021 11 10 kk8s upgrade
update with notifications
Feature/zipkin
Feature/lightstep
Feature/crossplane demo
Or perhaps I’m interested to know what was closed just this month:
$ curl -u idjohnson:$GHTOKEN -H "Accept: application/vnd.github.v3+json" https://api.github.com/repos/idjohnson/jekyll-blog/issues?state=closed\&since=2021-12-01T00:00:0
0CST 2>/dev/null | jq '.[] | .title
'
"Feature - GH Workflow Implementation "
"Feature/impl gh workflow"
"Feature/gh actions"
Android App
Lately, I’ve also taken to use the Github App on my phone to quick add new ideas
Clicking the “+” button on the upper right, then selecting my GH Repo lets me add an issue
And I can just quick jot my thoughts and save
Datadog integration
We enjoy the native service hooks in Azure DevOps with Datadog today. How can we track change in a similar way with Github?
Ideally, we would use a Kubernetes Secret with our API key like
$ cat ddjekyllsecret.yaml
---
apiVersion: v1
kind: Secret
metadata:
name: ddjekyll
type: Opaque
data:
DDAPIKEY: asdfasdfasdfasdfasdfsadf=
$ kubectl apply -f ddjekyllsecret.yaml
secret/ddjekyll created
$ diff -c my-jekyllrunner-deployment.yaml my-jekyllrunner-deployment.yaml.bak
*** my-jekyllrunner-deployment.yaml 2021-12-08 18:04:12.289615800 -0600
--- my-jekyllrunner-deployment.yaml.bak 2021-12-08 18:02:21.979615800 -0600
***************
*** 31,41 ****
secretKeyRef:
key: PASSWORD
name: awsjekyll
- - name: DATADOG_API_KEY
- valueFrom:
- secretKeyRef:
- key: DDAPIKEY
- name: ddjekyll
image: harbor.freshbrewed.science/freshbrewedprivate/myghrunner:1.1.3
imagePullPolicy: IfNotPresent
imagePullSecrets:
--- 31,36 ----
$ kubectl apply -f my-jekyllrunner-deployment.yaml
runnerdeployment.actions.summerwind.dev/my-jekyllrunner-deployment configured
However, I tested a few patterns to try and leverage the ENV var in the api-key field, but in the end i had to use a Github project secret
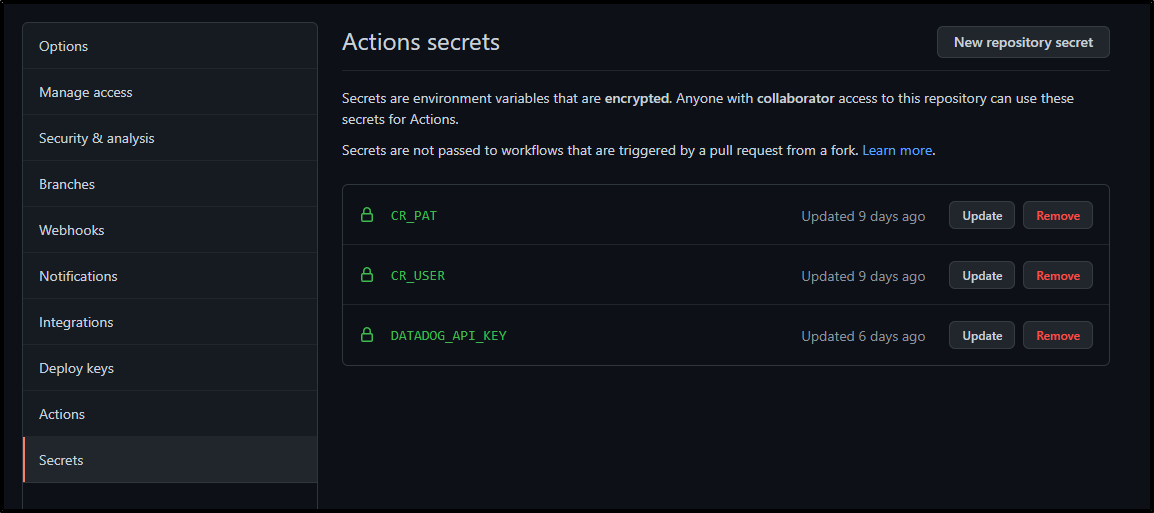
And using it in the Github Actions Workflow:
Note: some DD steps are for Metrics and some for Events
$ cat .github/workflows/pr-final.yml
name: PR And Main Build
on:
push:
branches:
- main
pull_request:
jobs:
build_deploy_test:
runs-on: self-hosted
if: github.ref != 'refs/heads/main'
steps:
- name: Check out repository code
uses: actions/checkout@v2
- name: bundle install
run: |
gem install jekyll bundler
bundle install --retry=3 --jobs=4
- name: build jekyll
run: |
bundle exec jekyll build
- name: list files
run: |
aws s3 cp --recursive ./_site s3://freshbrewed-test --acl public-read
- name: Build count
uses: masci/datadog@v1
with:
api-key: $
metrics: |
- type: "count"
name: "test.runs.count"
value: 1.0
host: $
tags:
- "project:$"
- "branch:$"
build_deploy_final:
runs-on: self-hosted
if: github.ref == 'refs/heads/main'
steps:
- name: Check out repository code
uses: actions/checkout@v2
- name: bundle install
run: |
gem install jekyll bundler
bundle install --retry=3 --jobs=4
- name: build jekyll
run: |
bundle exec jekyll build
- name: copy files to final
run: |
aws s3 cp --recursive --dryrun ./_site s3://freshbrewed.science --acl public-read
- name: cloudfront invalidation
run: |
aws cloudfront create-invalidation --distribution-id E3U2HCN2ZRTBZN --paths "/index.html"
- name: Build count
uses: masci/datadog@v1
with:
api-key: $
metrics: |
- type: "count"
name: "test.runs.count"
value: 1.0
host: $
tags:
- "project:$"
- "branch:$"
dd_tracking:
runs-on: self-hosted
steps:
- name: Datadog-Fail
if: failure()
uses: masci/datadog@v1
with:
api-key: $
events: |
- title: "Passed building jekyll"
text: "Branch $ failed to build"
alert_type: "error"
host: $
tags:
- "project:$"
- name: Datadog-Pass
uses: masci/datadog@v1
with:
api-key: $
events: |
- title: "Passed building jekyll"
text: "Branch $ passed build"
alert_type: "info"
host: $
tags:
- "project:$"
After running it a few times, we see results
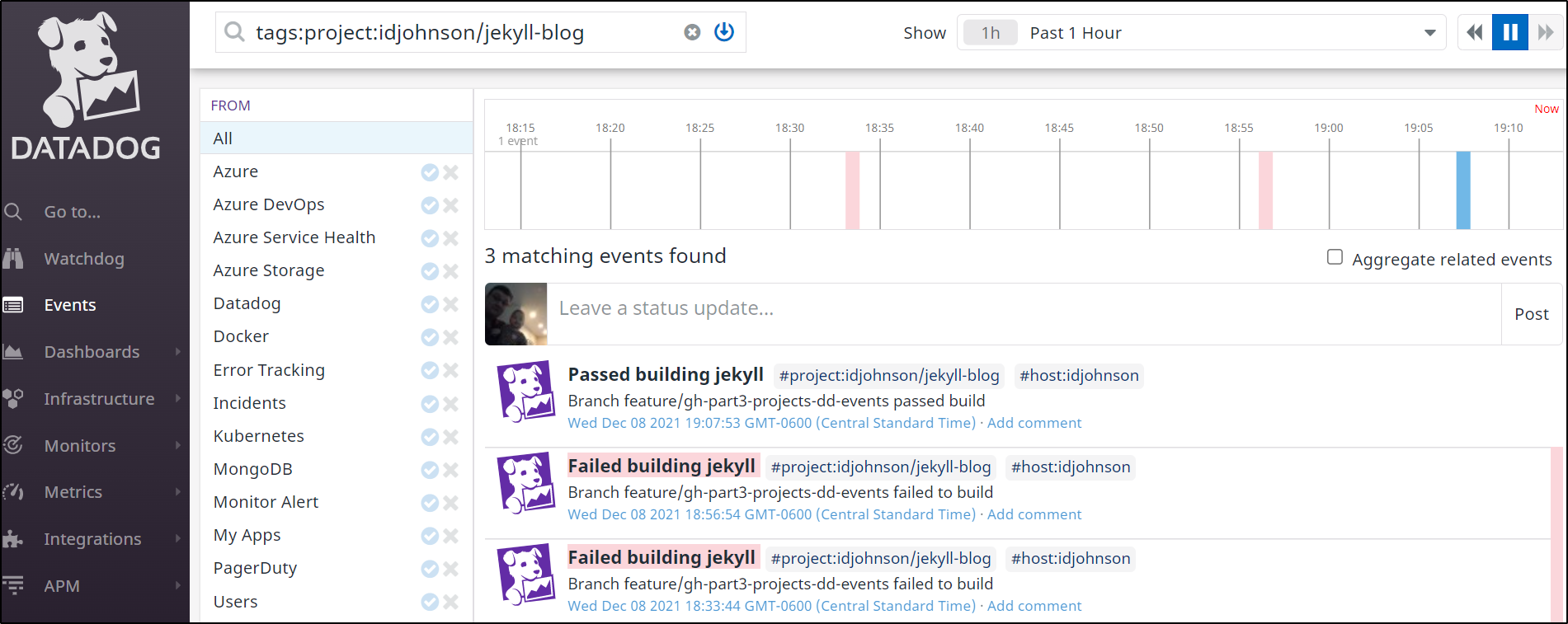
Using GH Datadog Integration
Datadog now as a new “CI” area for Continuous Integration tracking across DevOps toolsets.
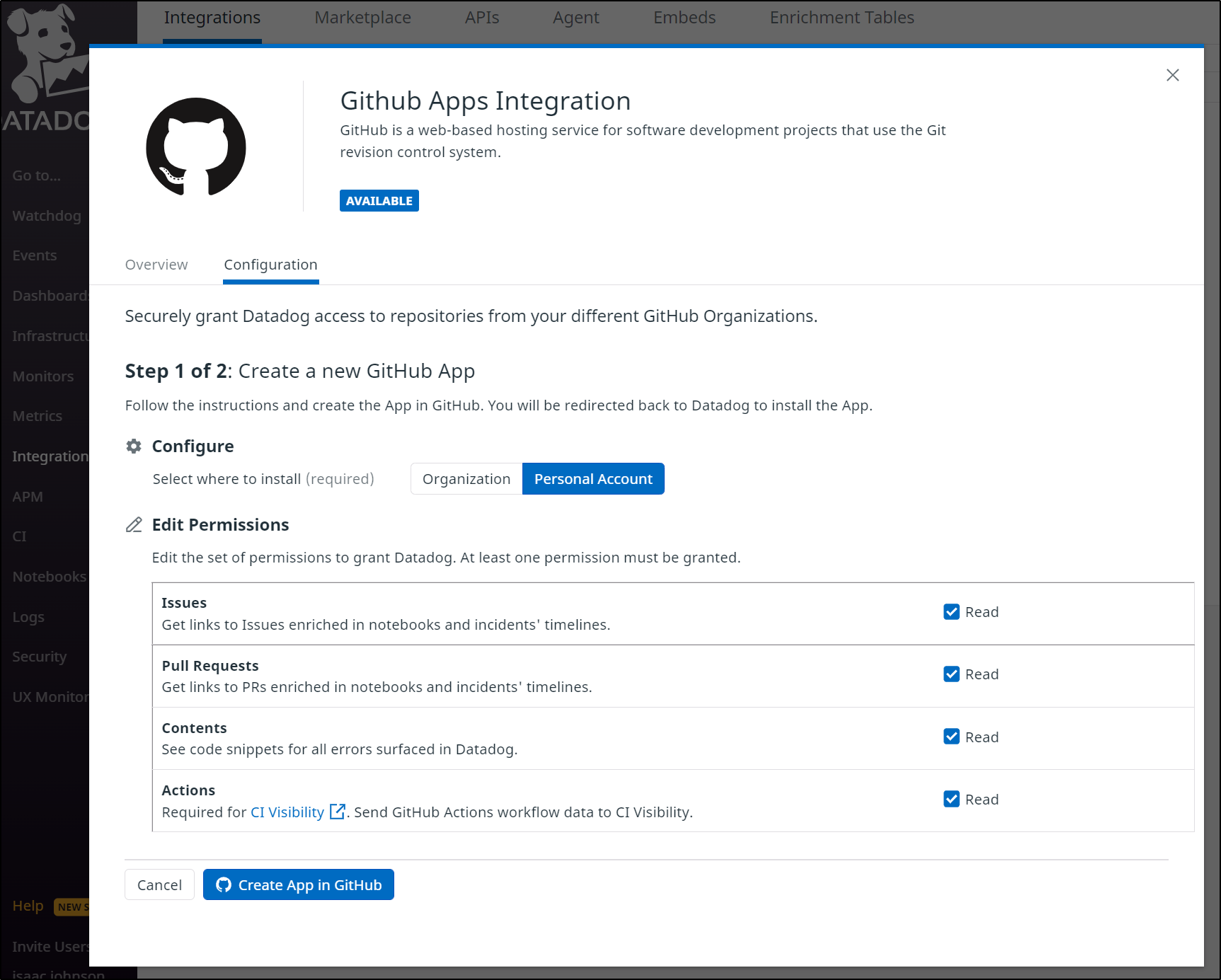
We have to install a new “App”
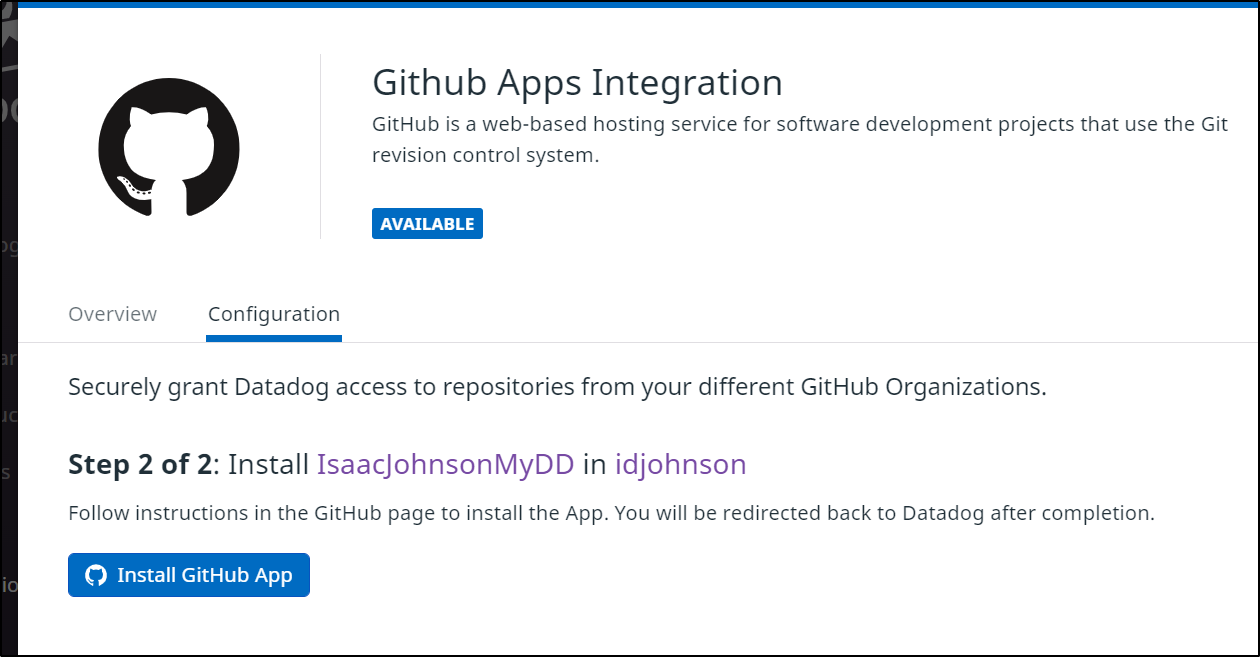
And link to our Repo or Repos.
In my case, as a consequence of my Github identity being in Corporate systems, I had to narrowly focus my CI integration:
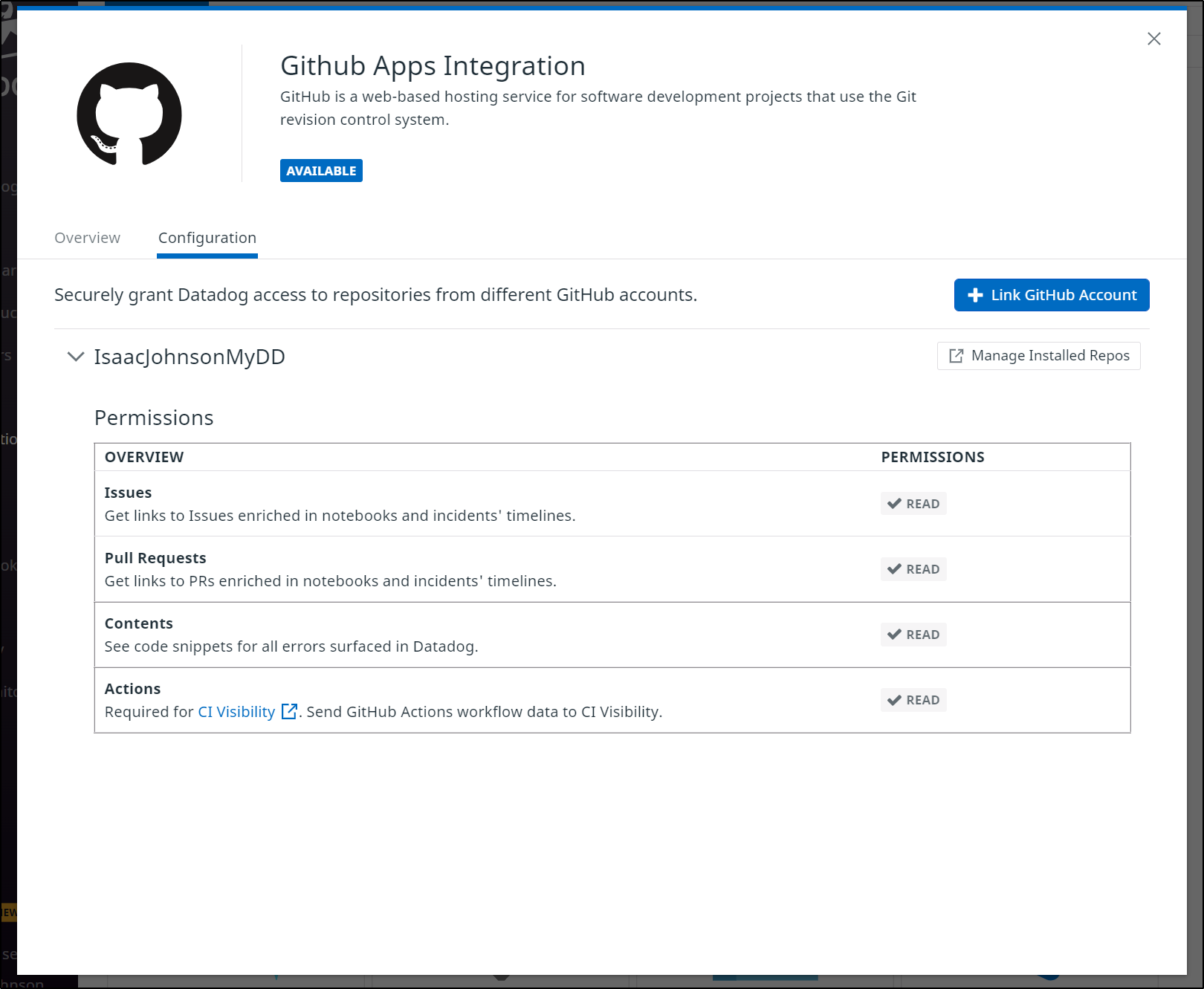
We can now see our results in the CI section
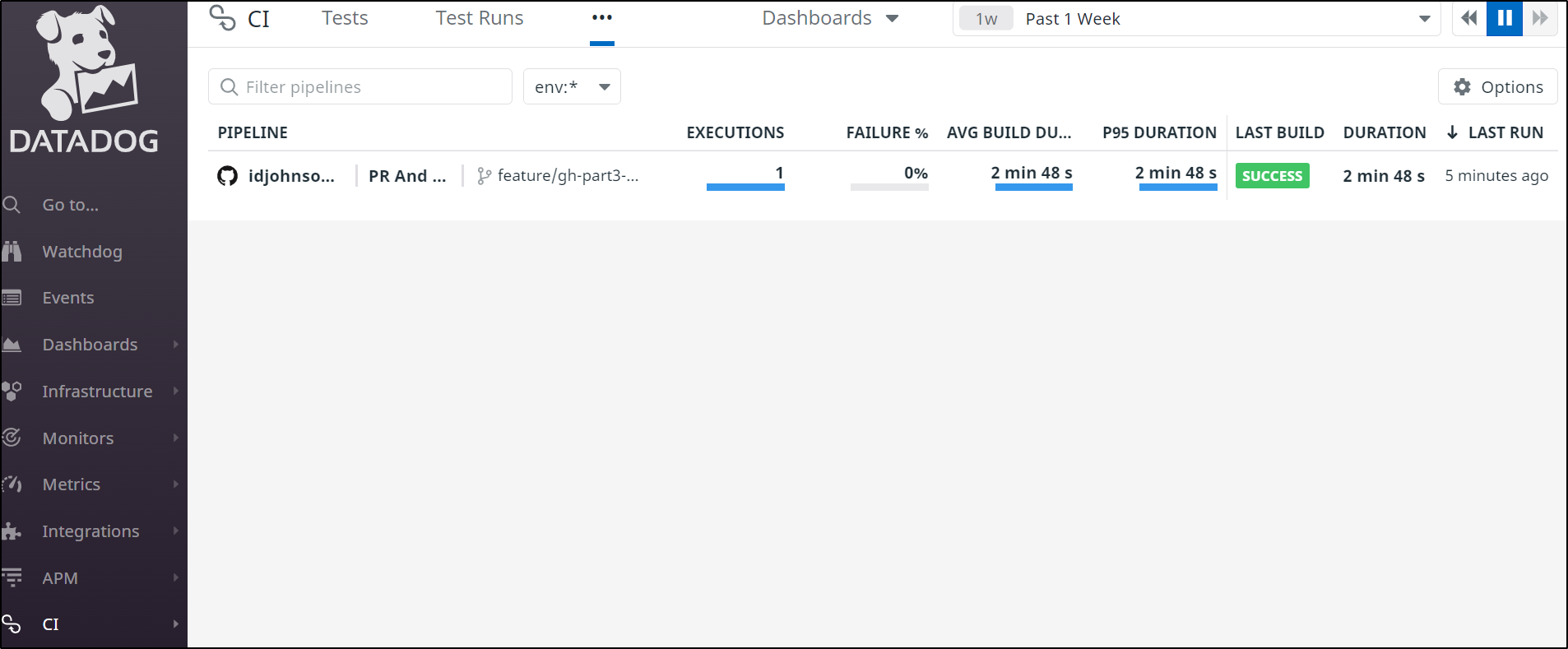
Digging into a Pipeline (Workflow), we can see details such as the stages (Jobs) that are performed and their duration
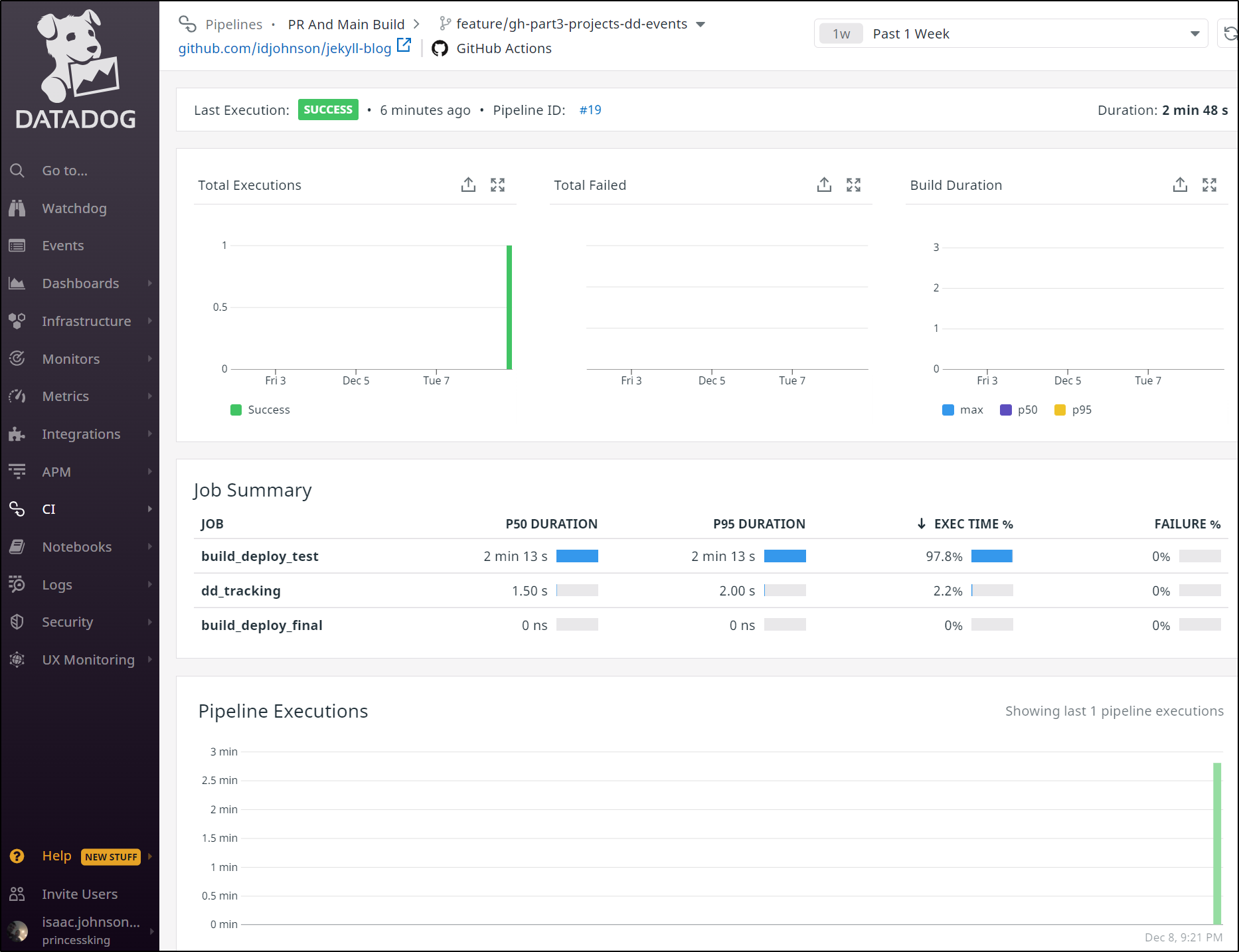
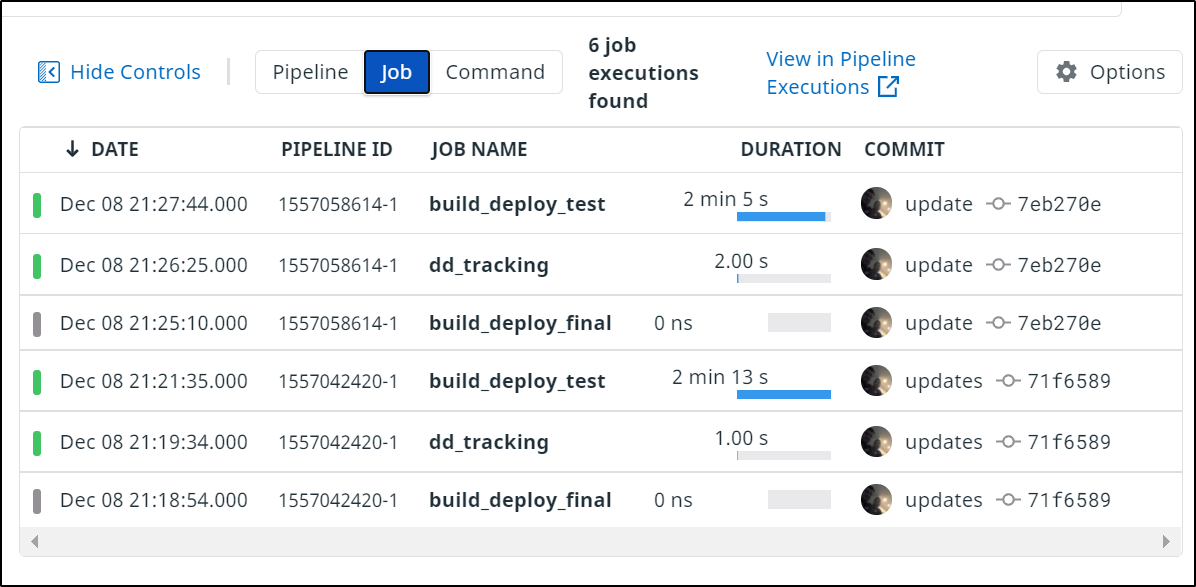
Or look a history of all our stages (jobs) chronologically:
Datadog Events for CI vs CI tracking
CI Tracking offers some great reporting and Dashboards. It’s easy to dig into Pipeline performance and issues.
But there is a consequence (other than cost).
There is no way, at present, to create a Monitor on CI Events. For me, the largest value of Datadog is Monitoring and Alerting.
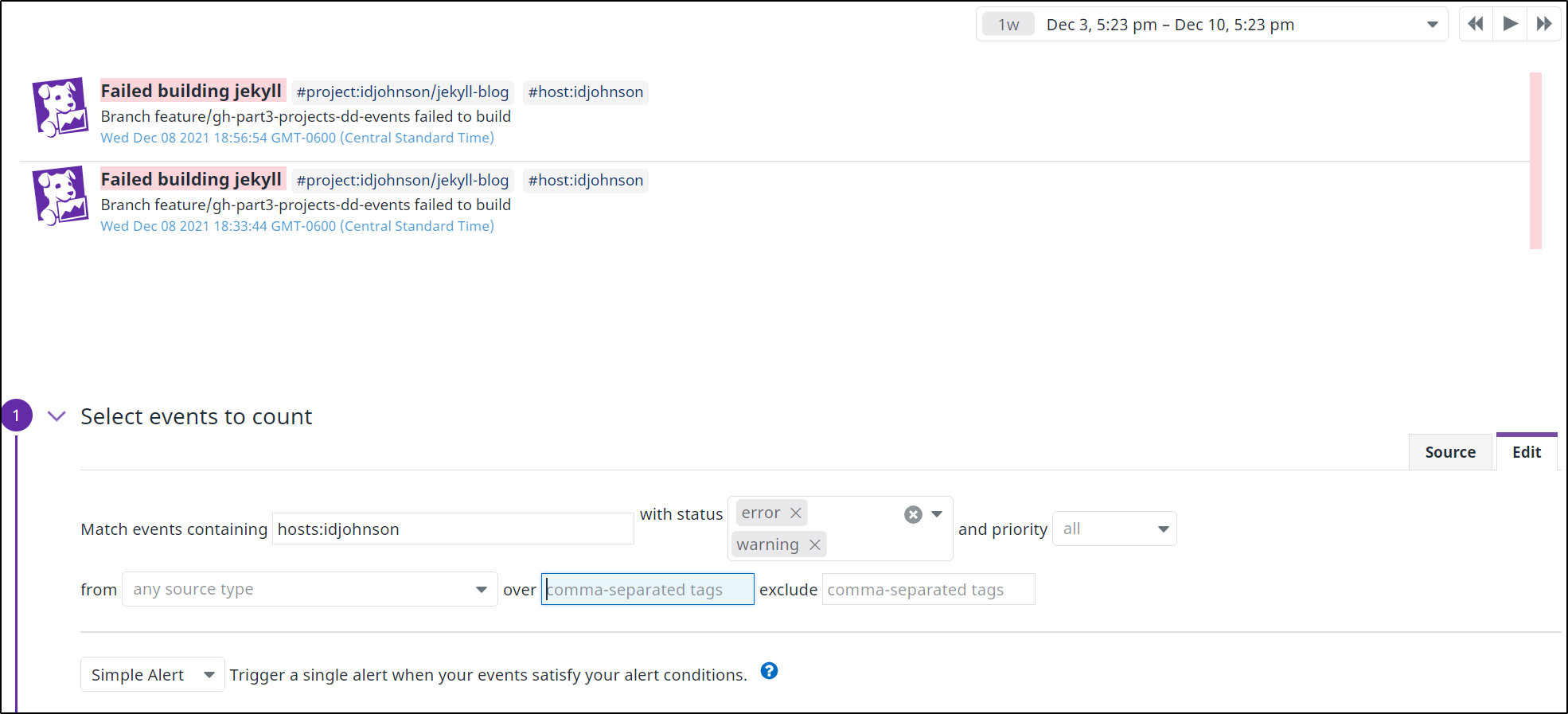
I can use event tracking to create a monitor on events('tags:event_type:build priority:all failed sources:azuredevops').rollup('count').last('5m') > 2
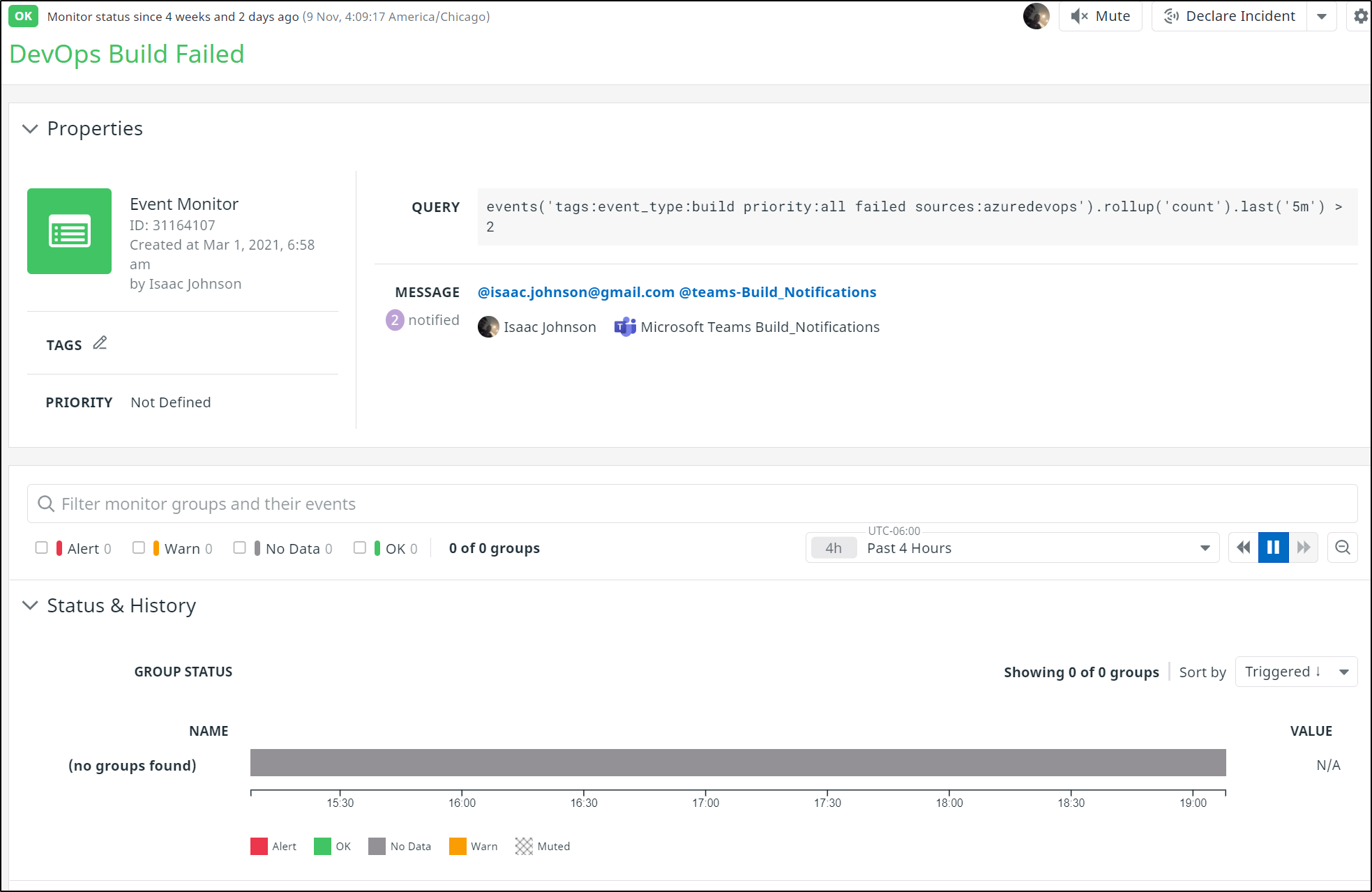
This can email me on failures
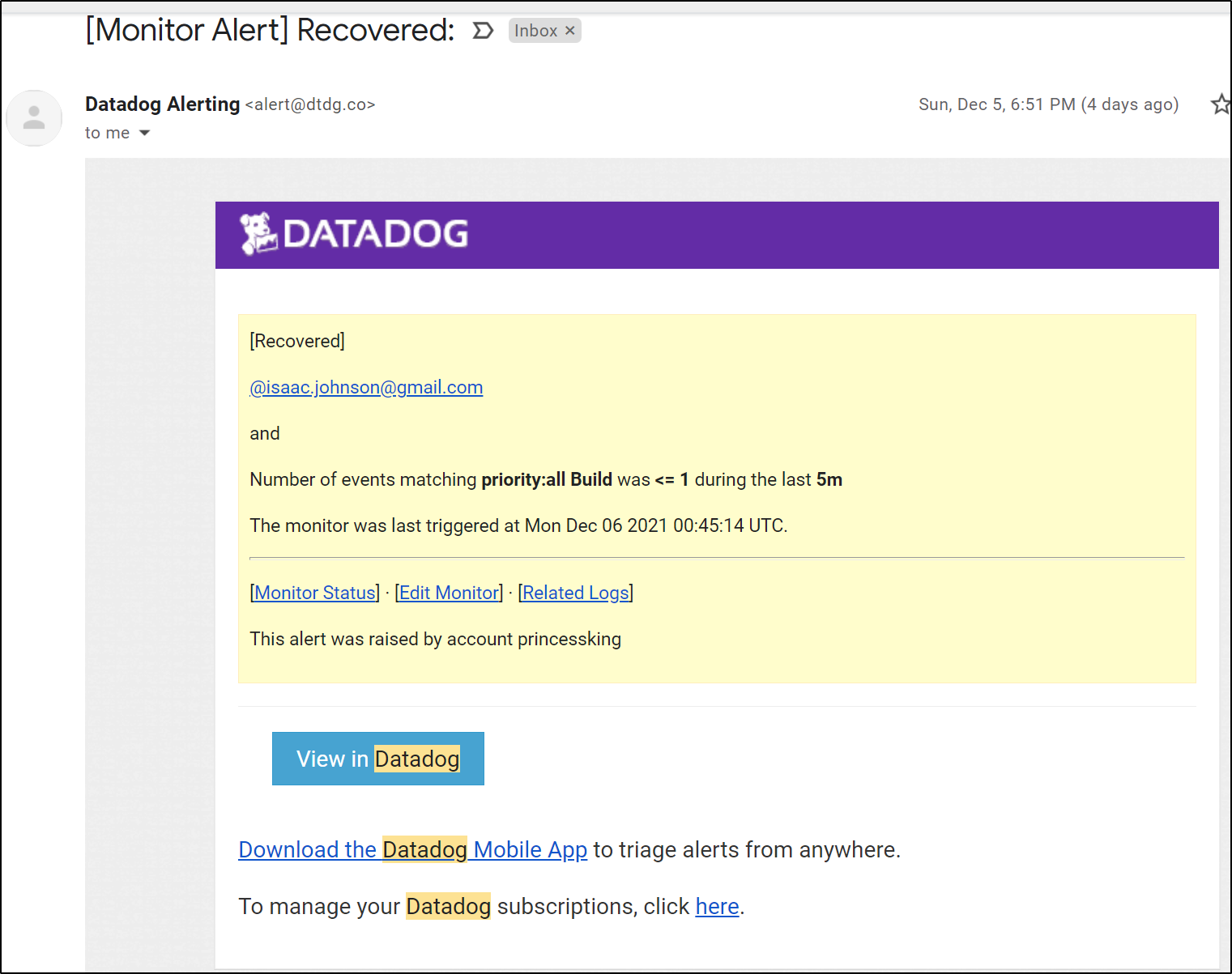
As well as update Teams / Slack.
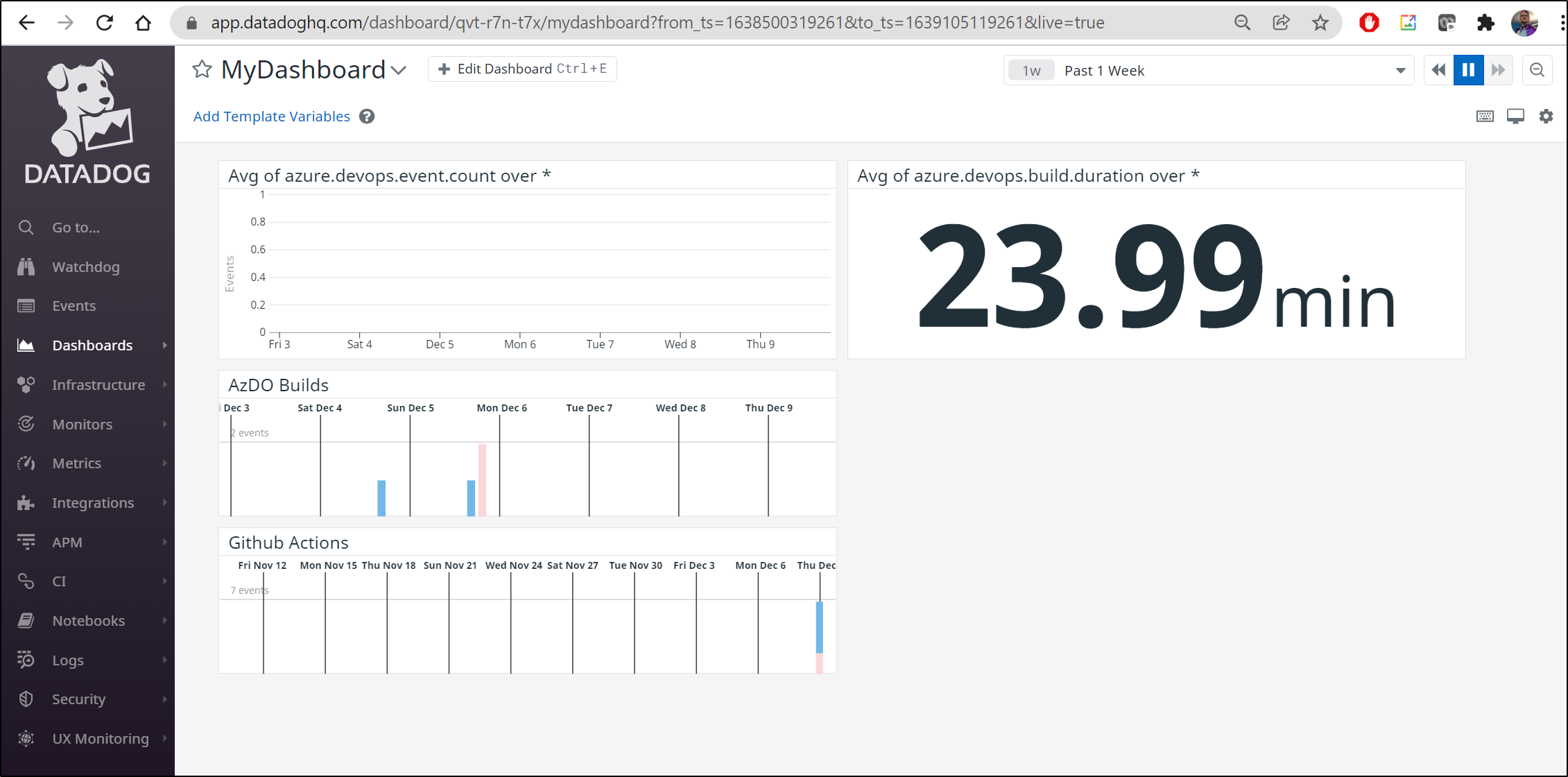
And while it’s not exactly simple, I can bring events from Github Actions and AzDO together in a Dashboard
And lest I forget, I can create a monitor for Github Workflows as I did for AzDO Pipelines:
Once I set conditions and notifications
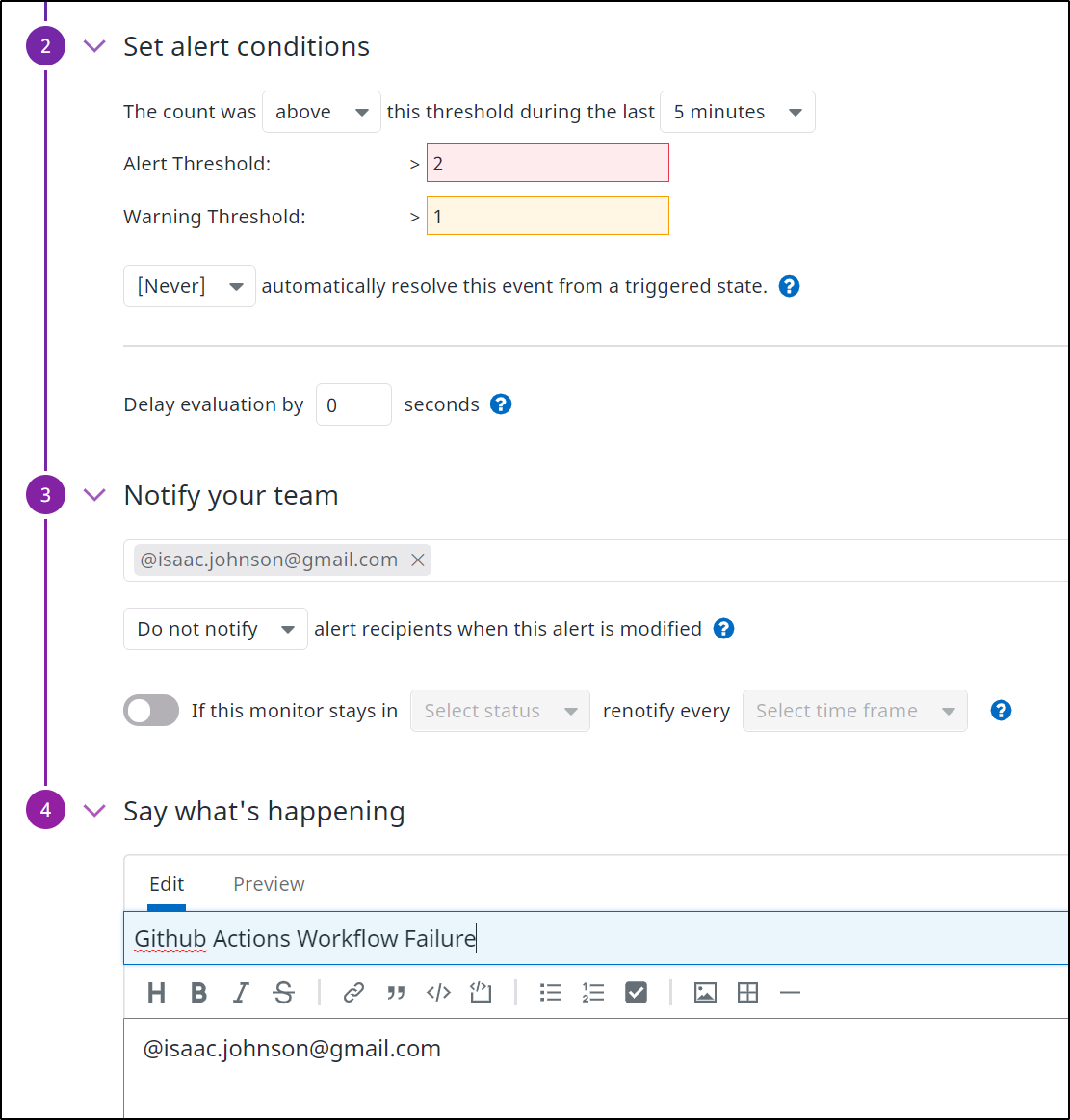
Tracking Failures
As a final note, to properly track errors I’ll want a job that conditionally fails if either prior job fails then sends that error to Datadog as an event
run-if-failed:
runs-on: ubuntu-latest
needs: [build_deploy_test, build_deploy_final]
if: always() && (needs.build_deploy_test.result == 'failure' || needs.build_deploy_final.result == 'failure')
steps:
- name: Datadog-Fail
uses: masci/datadog@v1
with:
api-key: $
events: |
- title: "Failed building jekyll"
text: "Branch $ failed to build"
alert_type: "error"
host: $
tags:
- "project:$"
In fact, if we want to tailor our metrics and track failures as a metric too, we would update our workflow to look as such:
name: PR And Main Build
on:
push:
branches:
- main
pull_request:
jobs:
build_deploy_test:
runs-on: self-hosted
if: github.ref != 'refs/heads/main'
steps:
- name: Check out repository code
uses: actions/checkout@v2
- name: bundle install
run: |
gem install jekyll bundler
bundle install --retry=3 --jobs=4
- name: build jekyll
run: |
bundle exec jekyll build
- name: list files
run: |
aws s3 cp --recursive ./_site s3://freshbrewed-test --acl public-read
- name: Build count
uses: masci/datadog@v1
with:
api-key: $
metrics: |
- type: "count"
name: "prfinal.runs.count"
value: 1.0
host: $
tags:
- "project:$"
- "branch:$"
- name: Datadog-Pass
uses: masci/datadog@v1
with:
api-key: $
events: |
- title: "Passed building jekyll"
text: "Branch $ passed build"
alert_type: "info"
host: $
tags:
- "project:$"
build_deploy_final:
runs-on: self-hosted
if: github.ref == 'refs/heads/main'
steps:
- name: Check out repository code
uses: actions/checkout@v2
- name: bundle install
run: |
gem install jekyll bundler
bundle install --retry=3 --jobs=4
- name: build jekyll
run: |
bundle exec jekyll build
- name: copy files to final
run: |
aws s3 cp --recursive --dryrun ./_site s3://freshbrewed.science --acl public-read
- name: cloudfront invalidation
run: |
aws cloudfront create-invalidation --distribution-id E3U2HCN2ZRTBZN --paths "/index.html"
- name: Build count
uses: masci/datadog@v1
with:
api-key: $
metrics: |
- type: "count"
name: "prfinal.runs.count"
value: 1.0
host: $
tags:
- "project:$"
- "branch:$"
- name: Datadog-Pass
uses: masci/datadog@v1
with:
api-key: $
events: |
- title: "Passed building jekyll"
text: "Branch $ passed build"
alert_type: "info"
host: $
tags:
- "project:$"
run-if-failed:
runs-on: ubuntu-latest
needs: [build_deploy_test, build_deploy_final]
if: always() && (needs.build_deploy_test.result == 'failure' || needs.build_deploy_final.result == 'failure')
steps:
- name: Datadog-Fail
uses: masci/datadog@v1
with:
api-key: $
events: |
- title: "Failed building jekyll"
text: "Branch $ failed to build"
alert_type: "error"
host: $
tags:
- "project:$"
- name: Fail count
uses: masci/datadog@v1
with:
api-key: $
metrics: |
- type: "count"
name: "prfinal.fails.count"
value: 1.0
host: $
tags:
- "project:$"
- "branch:$"
Verification
We can see how that works:
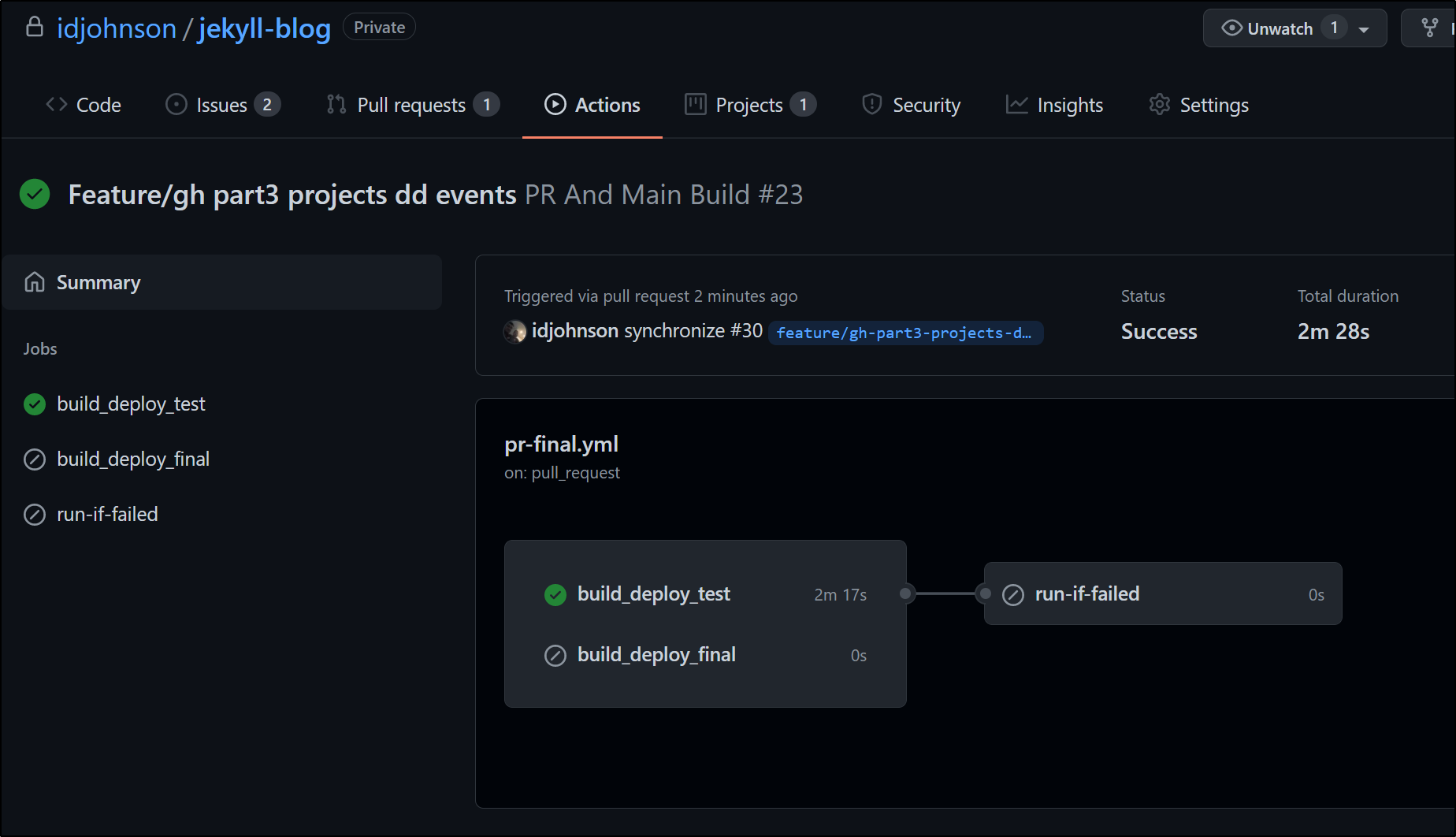
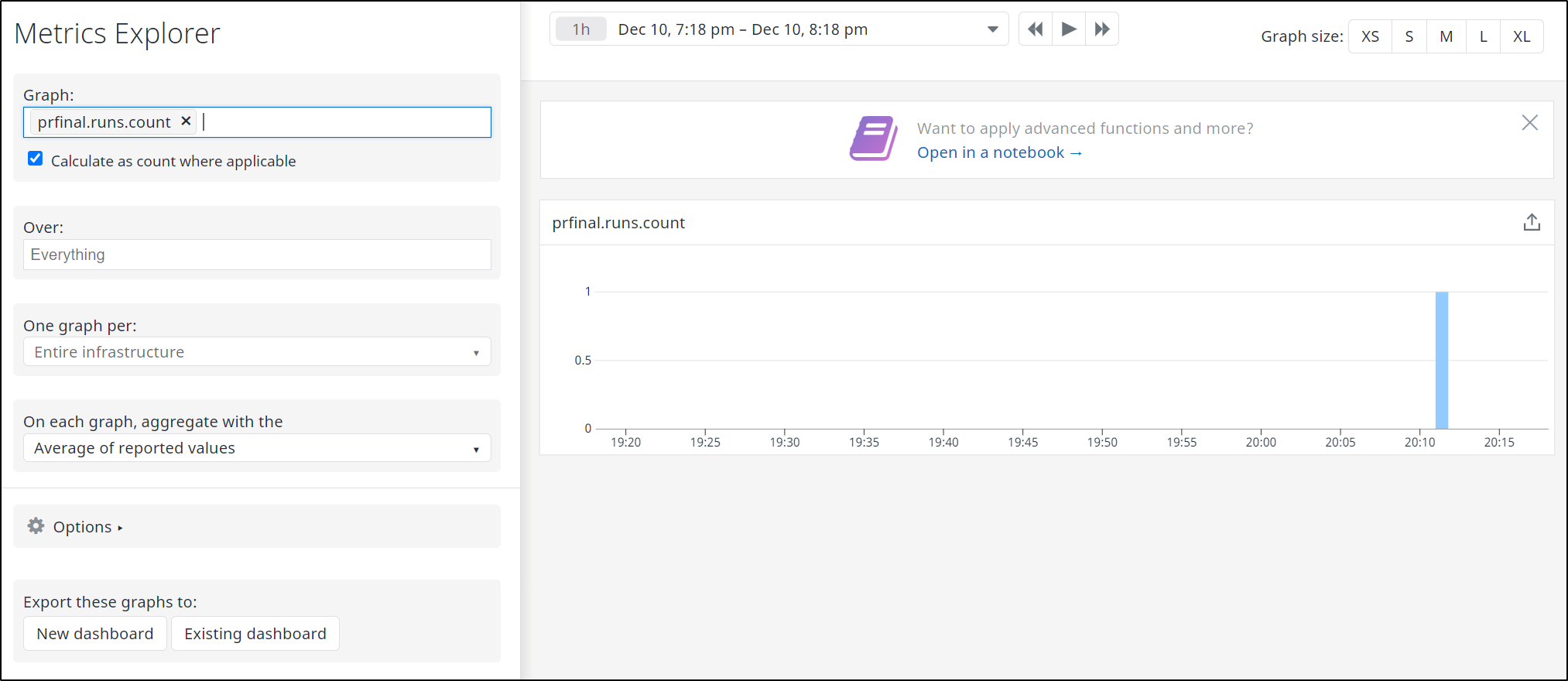
When run, we can immediately see the metric in Metrics Explorer:
Now let’s intentionally fail the process a few times to see what that looks like.
I’ll add an intentional fail on the build job:
jobs:
build_deploy_test:
runs-on: self-hosted
if: github.ref != 'refs/heads/main'
steps:
- name: Check out repository code
uses: actions/checkout@v2
- name: bundle install
run: |
gem install jekyll bundler
bundle install --retry=3 --jobs=4
echo FAIL
exit 1
We can see it properly fails and triggers the trailing ‘if fail’ job
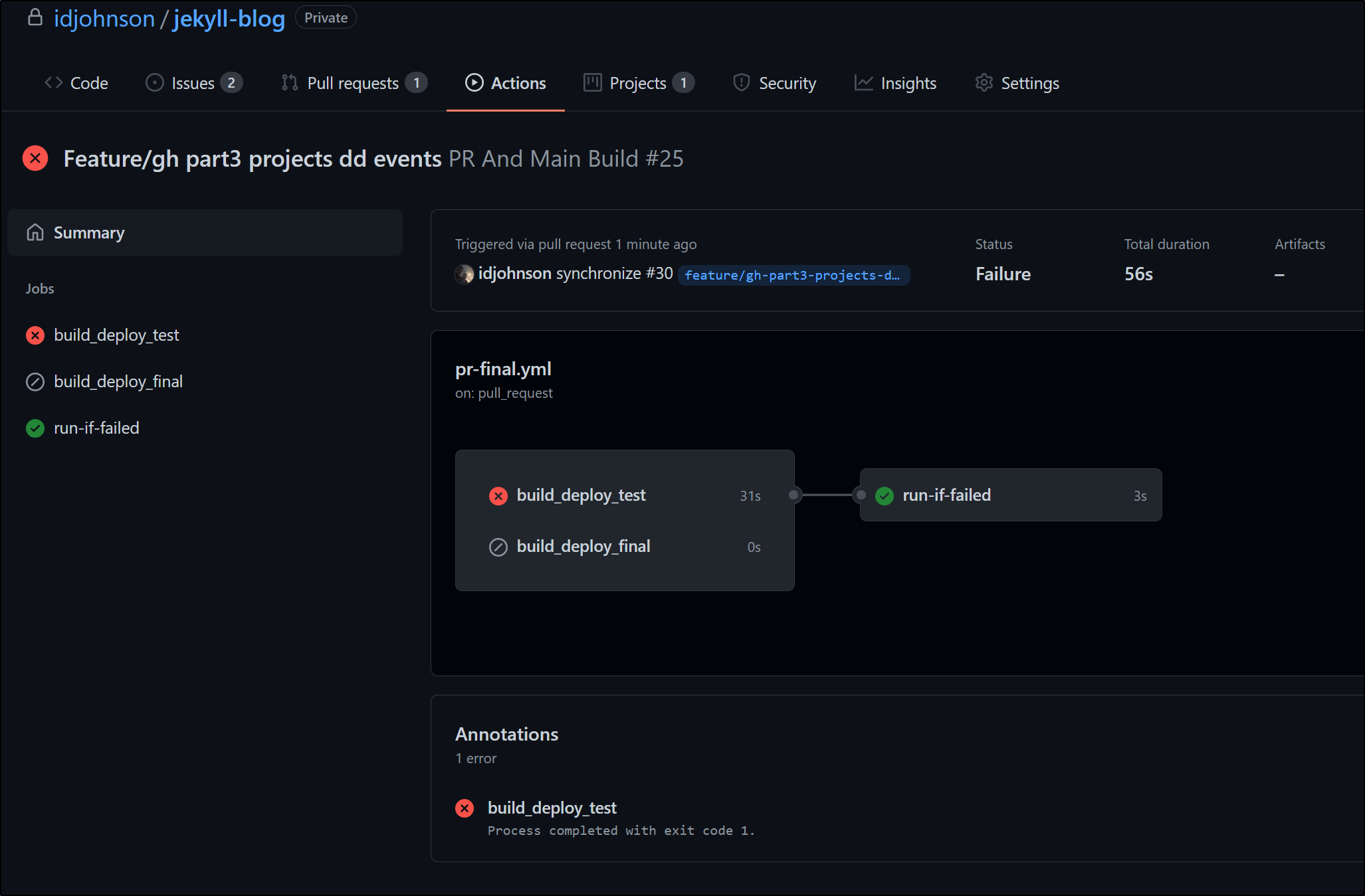
I failed it again and we can see that both instances of fail metrics are captured in Datadog; which we can see in the Metrics Explorer
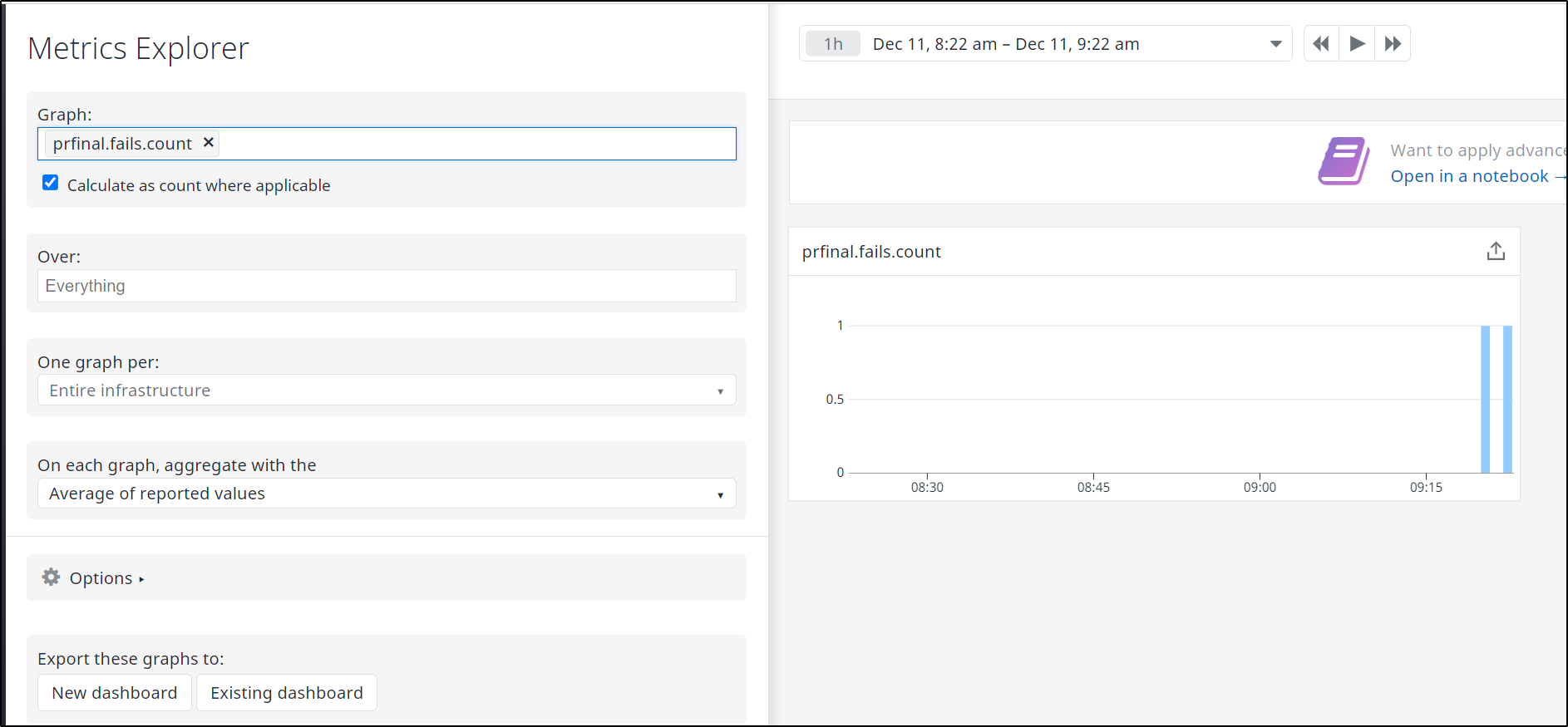
This then triggers the Monitor that updates Pagerduty which is also tied to Slack
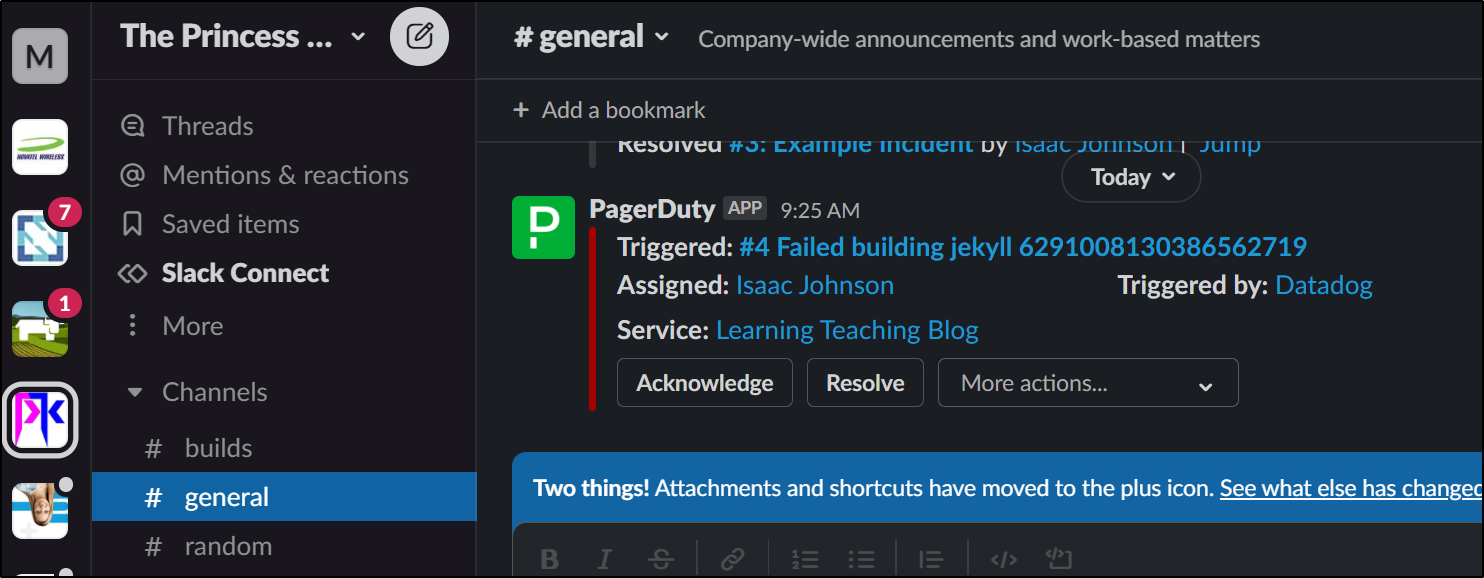
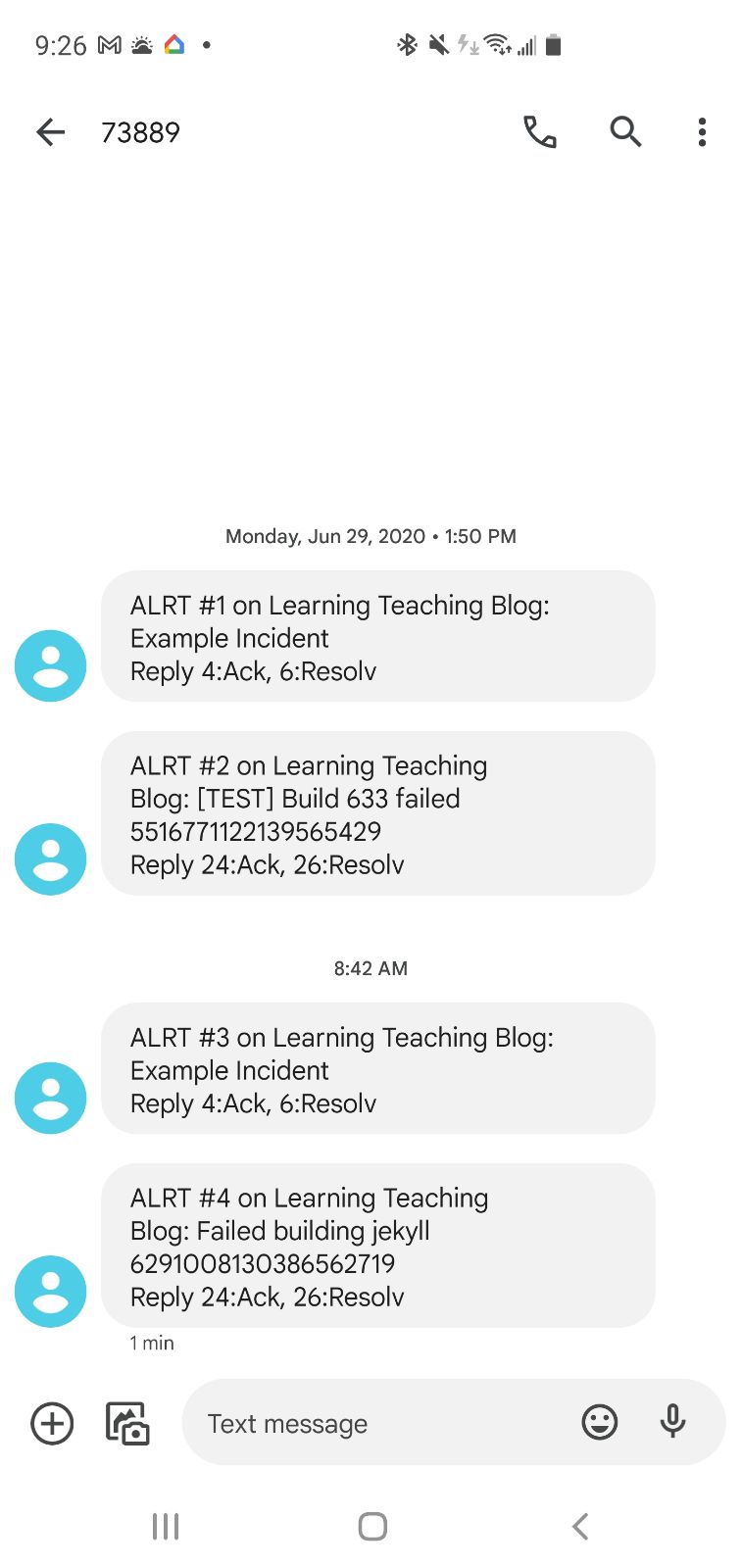
And since this is Pagerduty, I see that alert anywhere I’ve set up my notifications
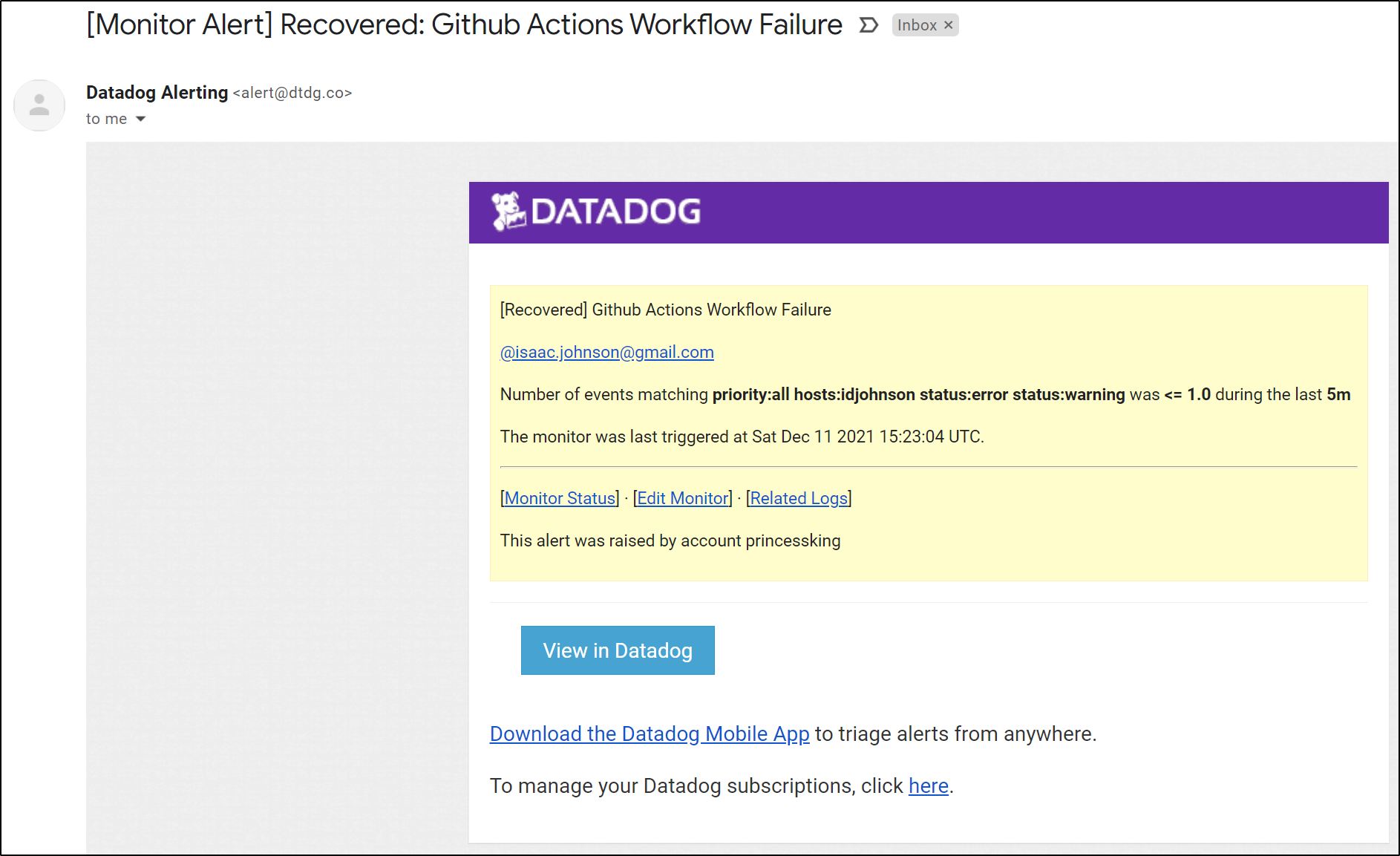
Of course, from the monitor itself we get a notification
Over Alerting is Worse than No Alerting
One word of caution on this. It is easy to over-alert by integrating too many overlapping systems. If we pick “all the options” and send emails, Datadog alerts, then tie to a pager system like PagerDuty, our support staff can be buried by a mountain of alerts anytime something goes amiss

The result is always that if we have too much notification it ceases to be Information and becomes Noise. And Noise always is invariably ignored.
The right solution is to limit alerting to narrow audiences who can action systems.
Escalation Paths
Let’s consider an example to illustrate this point. Something that comes up in my professional life often is being CC’ed on Revision Control System notifications (Github/AzDO Repos). In the last several corporations of which I’ve been in the employ, this has meant all revision control system notifications are filtered to trash.
This means wasted bandwidth, storage and bits and a false sense of “well the DevOps folks are CC’ed” on changes.
The better approach is to limit notifications to just the audience that needs to be aware - that should be approvers on change.
In Azure Repos we would use Global Review Policies to, perhaps, require a Data Team (e.g. DatabasePeople) to review any database type changes:
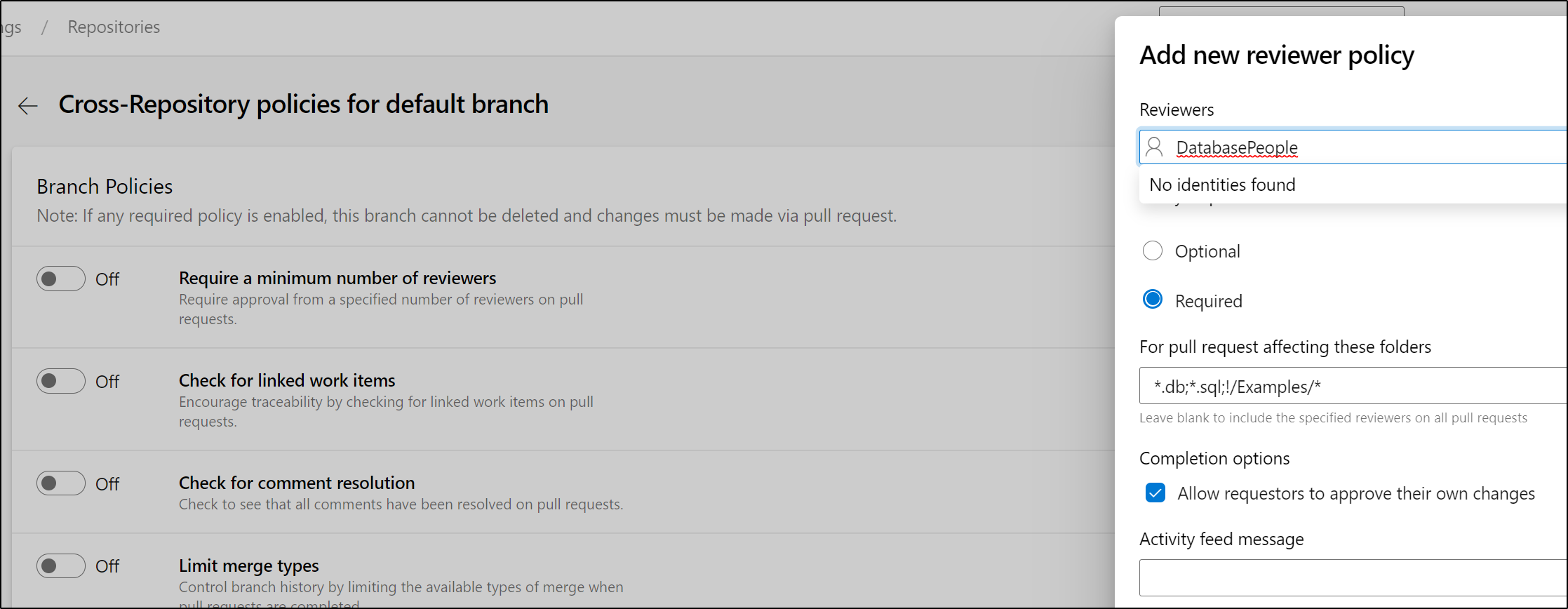
In Github, if you are in a Paid Tier (not available in Free accounts), you can use CODEOWNERS files in private repositories for policies and require a minimum set:
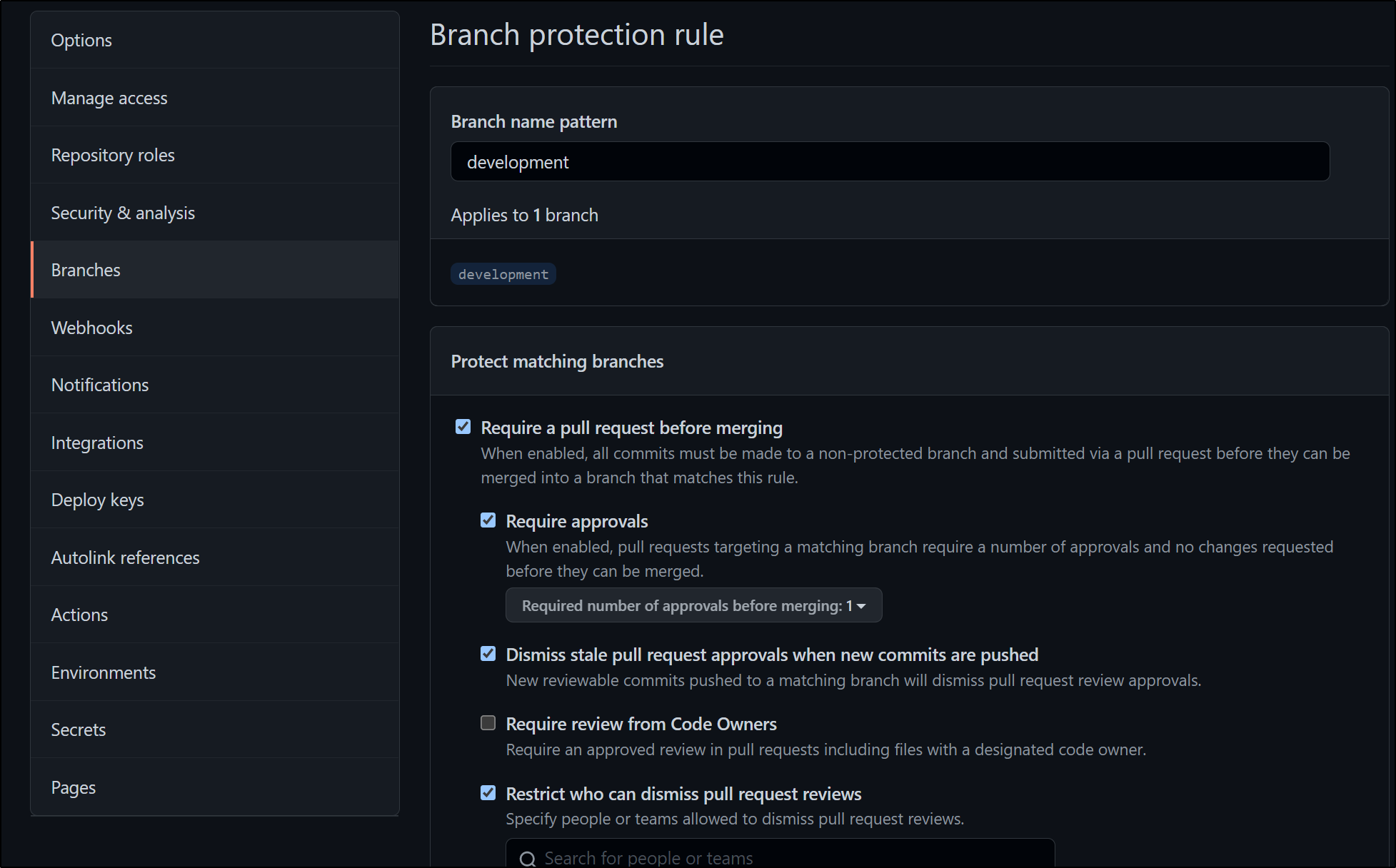
There are solutions for using the Code Owners files using the codeowners-checker GEM which could be integrated into a PR build.
I should note that you can leverage the CODEOWNERS and PR checks in Public Repositories in the free tier:
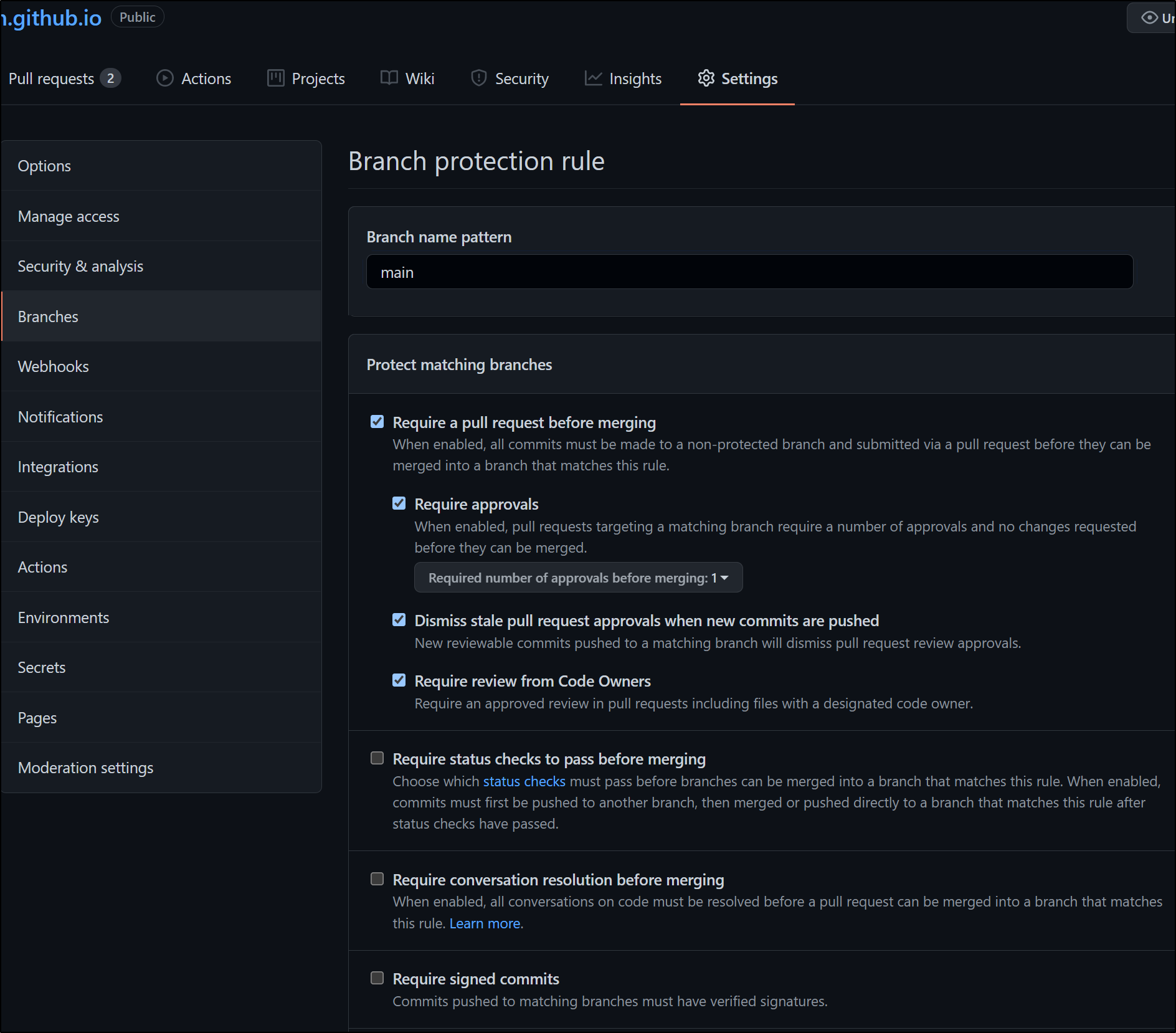
CODEOWNERS Demo
Let’s make a quick public repo and clone it down
$ git clone https://github.com/idjohnson/coTest.git
Cloning into 'coTest'...
remote: Enumerating objects: 3, done.
remote: Counting objects: 100% (3/3), done.
remote: Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
Unpacking objects: 100% (3/3), 593 bytes | 593.00 KiB/s, done.
Next, we make a CODEOWNERS file either at the root of the repo or in a .github folder (I find the latter cleaner).
$ cd coTest/
$ mkdir .github
$ vi .github/CODEOWNERS
$ cat .github/CODEOWNERS
# Default Owners
@idjohnson
*.txt tristan.cormac.moriarity@gmail.com
Now add and push it.
$ git add .github/
$ git commit -m "new codeowners file"
[main 6c510e2] new codeowners file
1 file changed, 7 insertions(+)
create mode 100644 .github/CODEOWNERS
$ git push
Enumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Delta compression using up to 16 threads
Compressing objects: 100% (3/3), done.
Writing objects: 100% (4/4), 406 bytes | 406.00 KiB/s, done.
Total 4 (delta 0), reused 0 (delta 0)
To https://github.com/idjohnson/coTest.git
dfb5309..6c510e2 main -> main
Next, a different user in Github viewing the repo decides to edit a file:
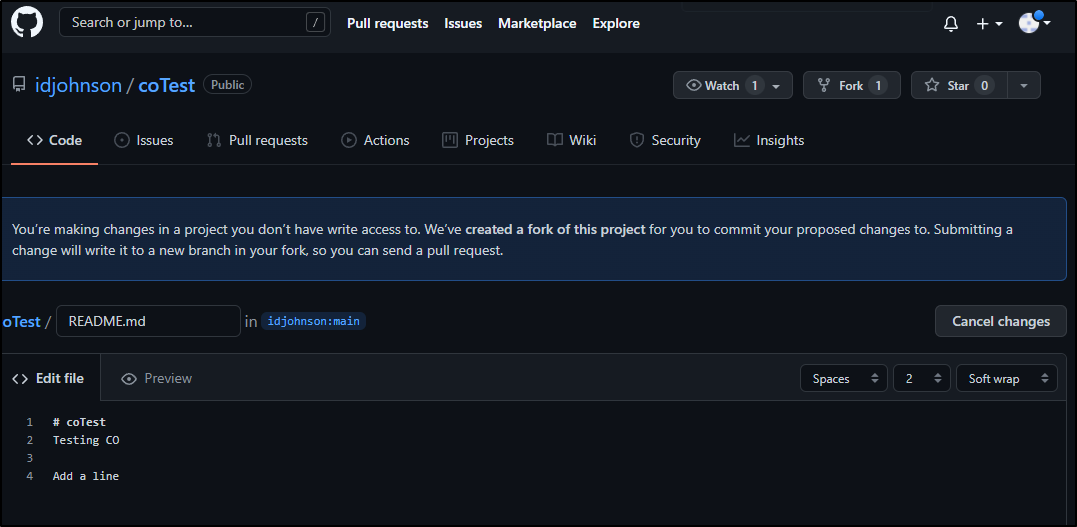
They do not get to commit directly, rather “propose a change”
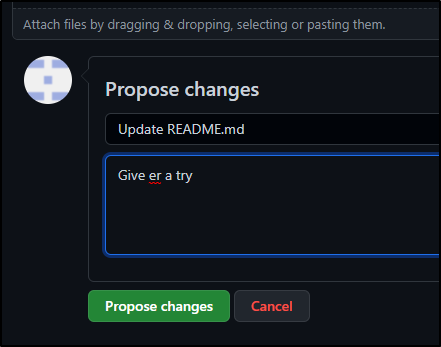
Once proposed (Creating a PR branch in their own namespace), they can “Create a pull request”
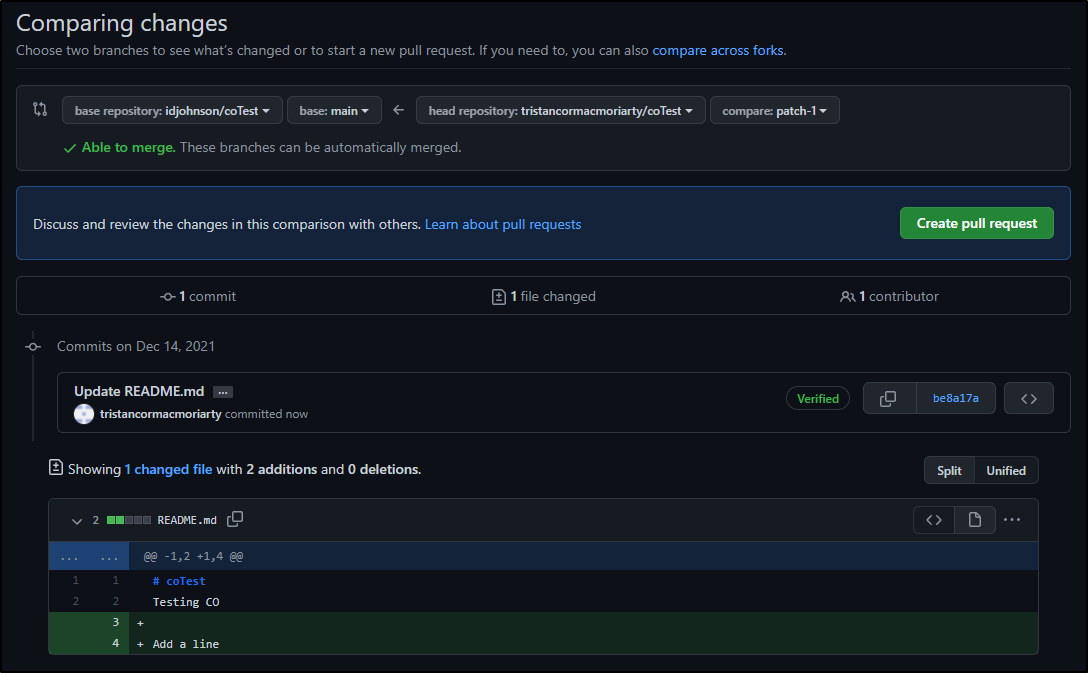
But as they are not codeowners, they have to wait on others to action the PR.
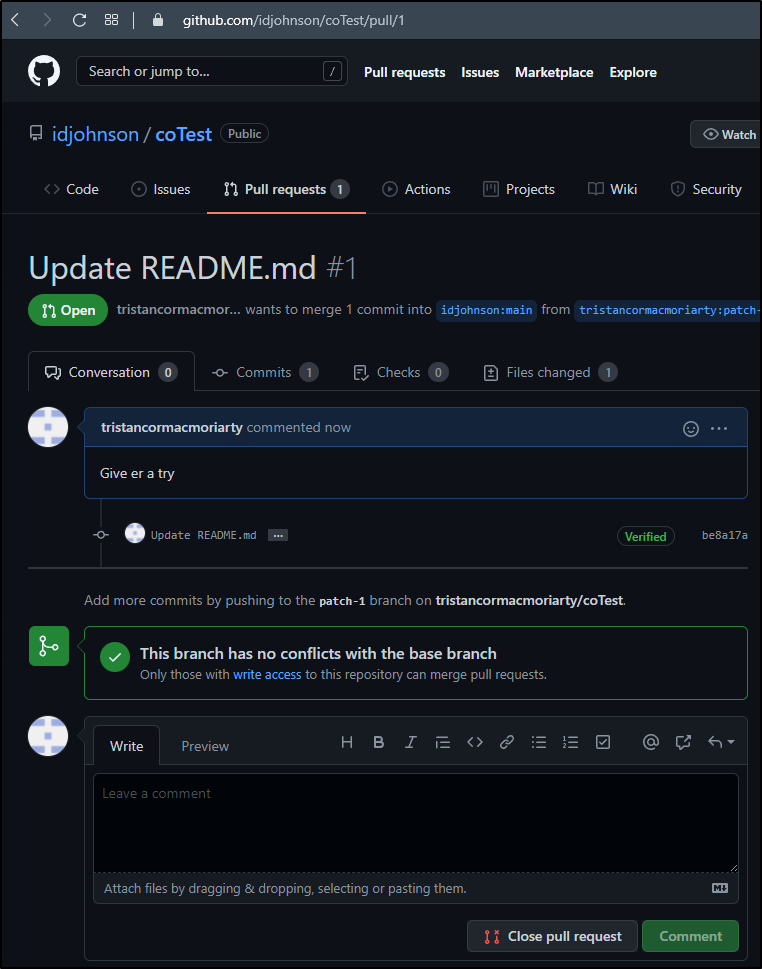
As you recall, I made this user able to update *.txt files.. so what happens when we add one of those.
Our other user (Tristan) will now create a new file
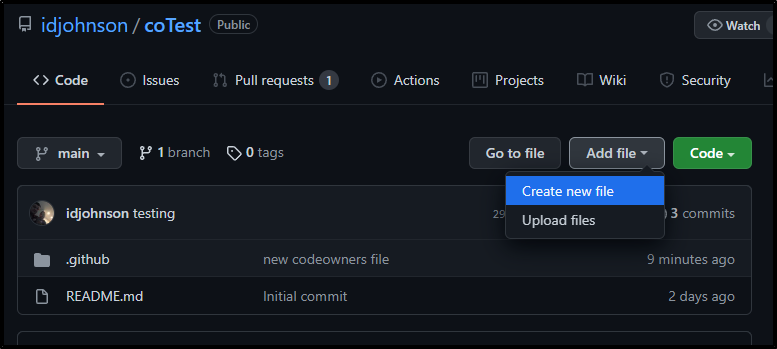
and name it test.txt
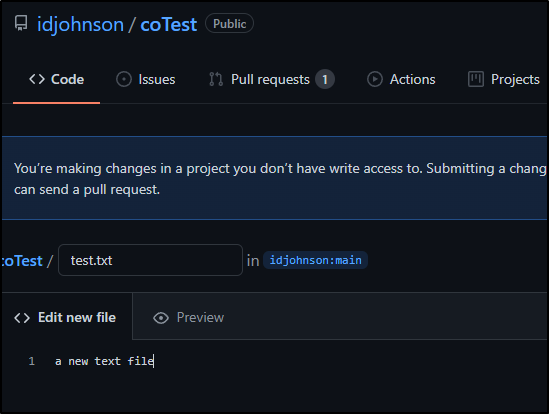
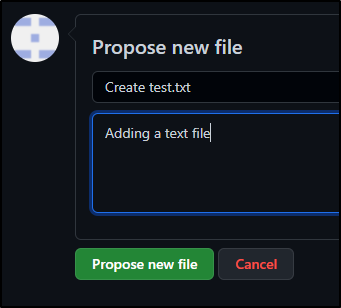
Then propose a change
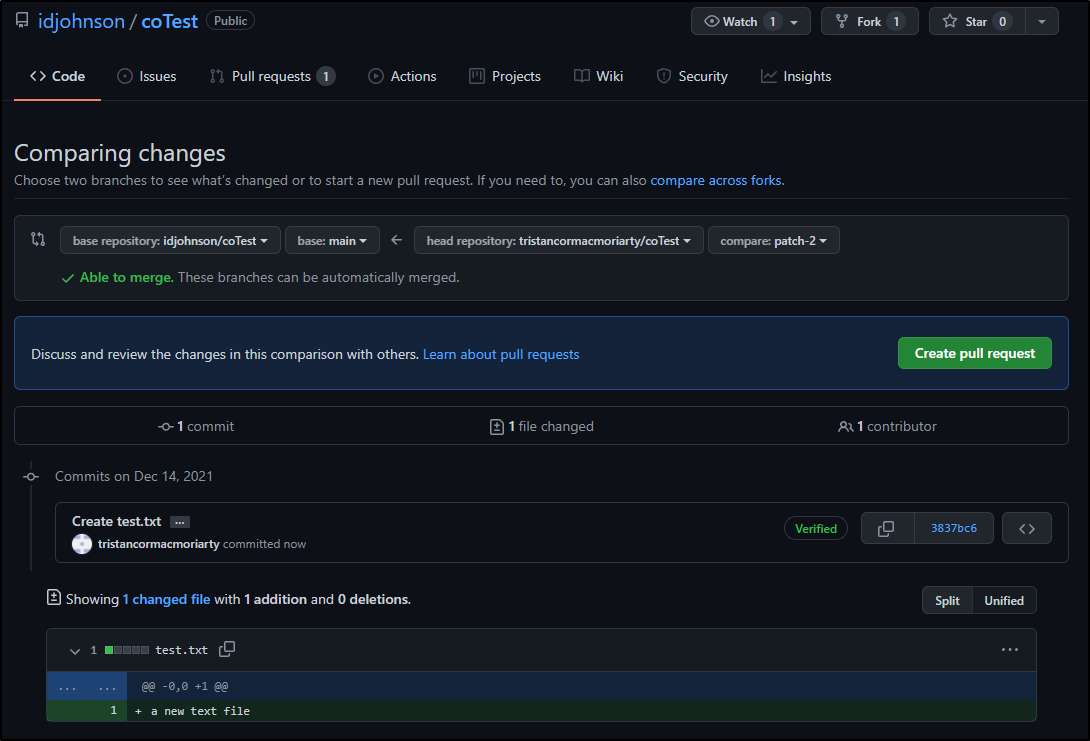
which prompts them to create a PR
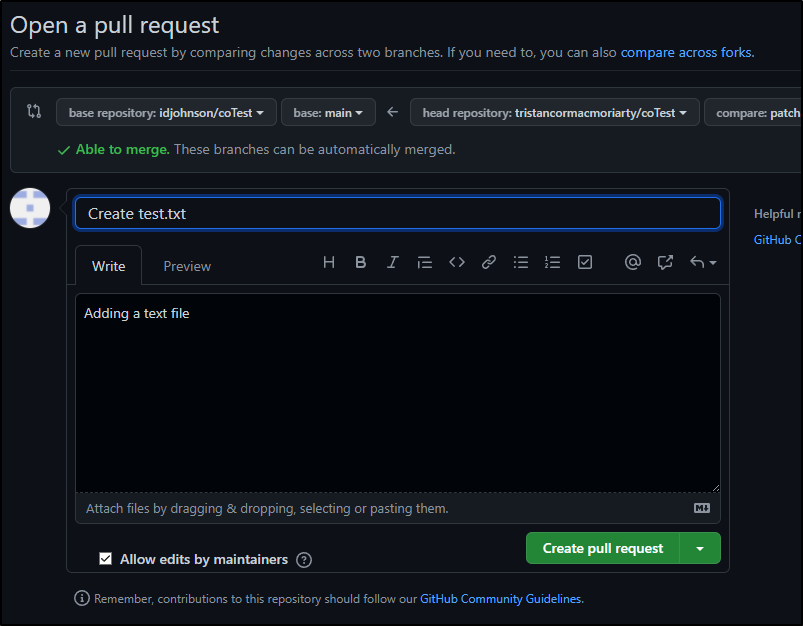
But why can they not action that PR?
This is because the CODEOWNERS file requires those reviewers to have write access to the repo.
We are only blocked now because we neglected to add this user as a contributor with write permissions per the docs
Let’s correct that..
In Manage access, we need to add a “collaborator”
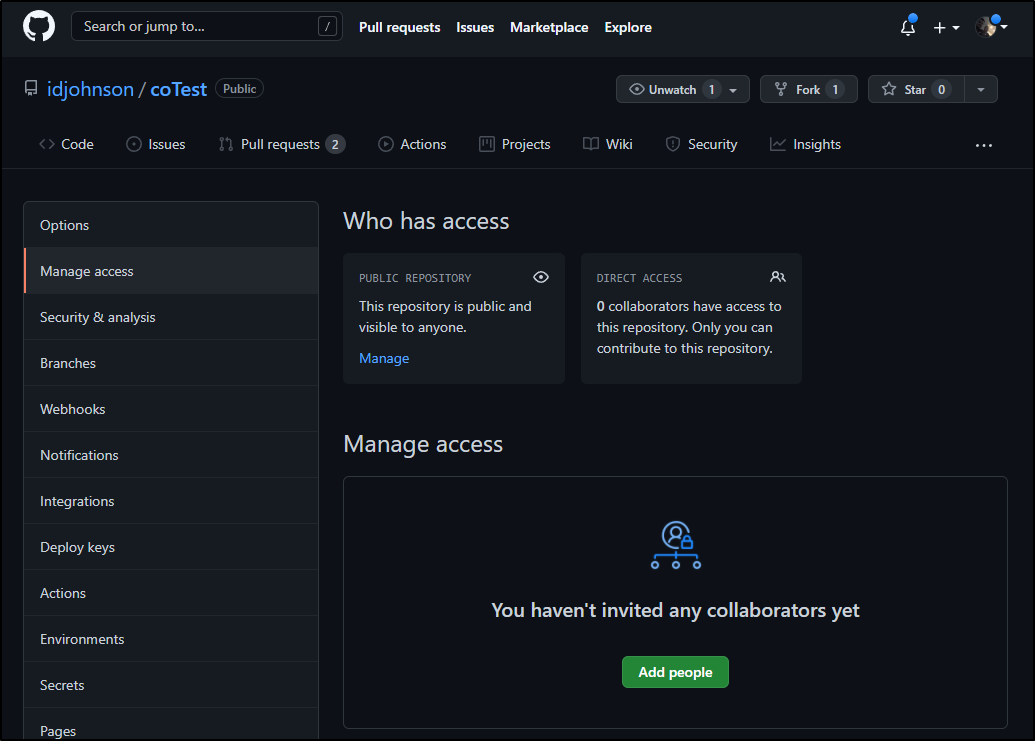
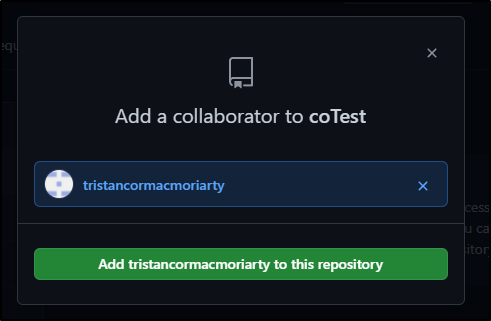
Now select the user and send the invite
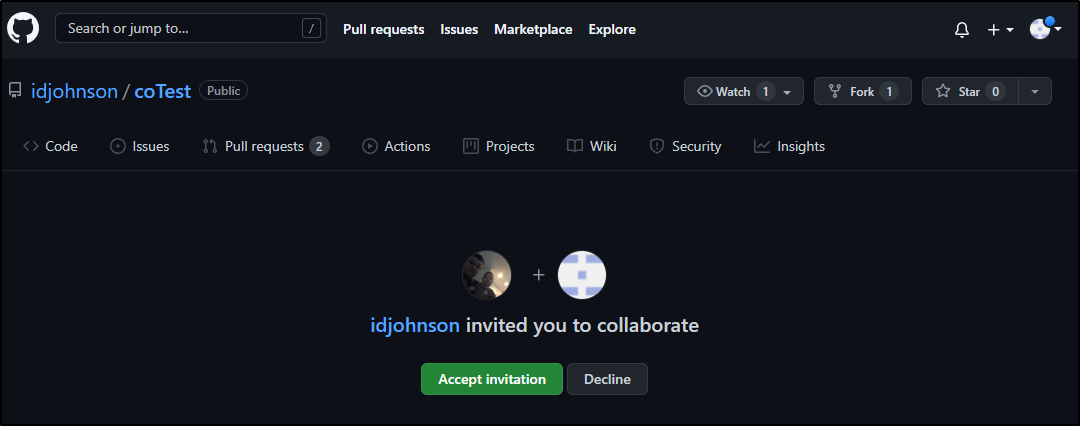
And of course our user has to accept
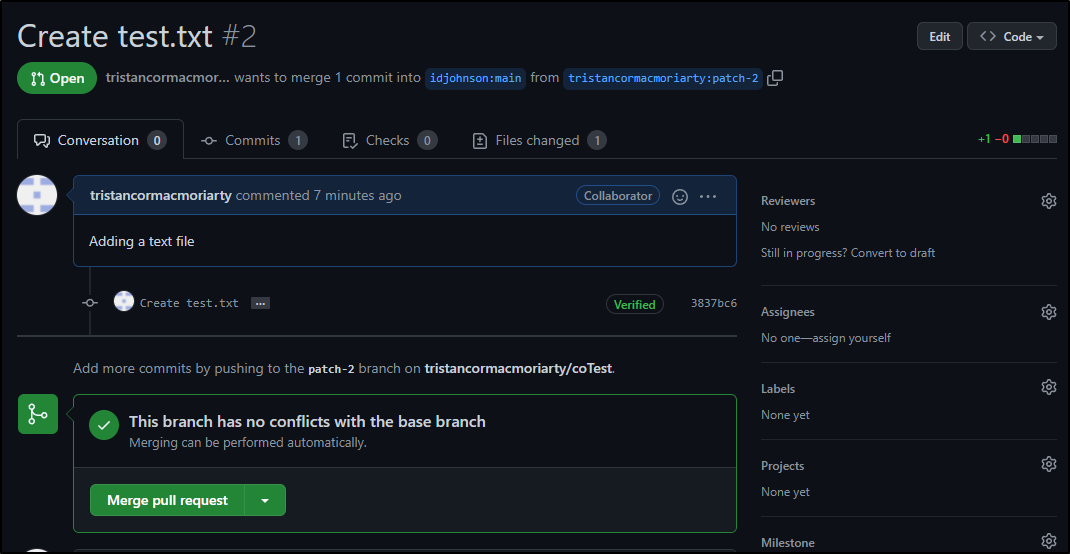
We can see our user now can merge PRs regardless of reviewer state:
Now our owner will edit the text file.
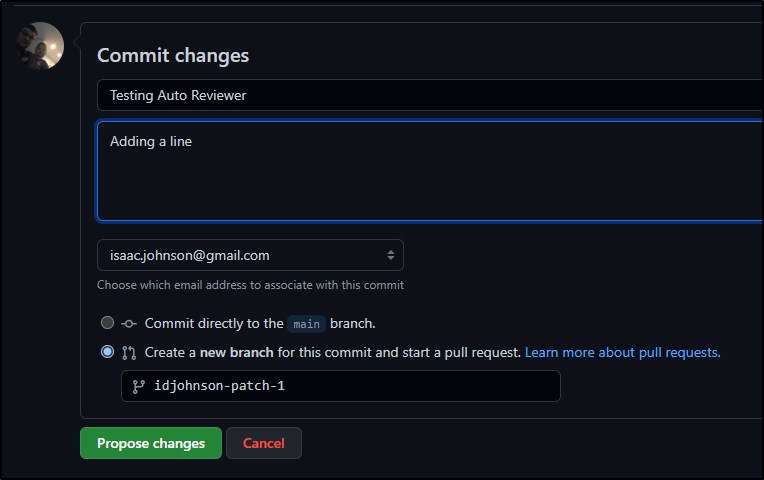
And we see indeed our Tristan user was added as review automatically.
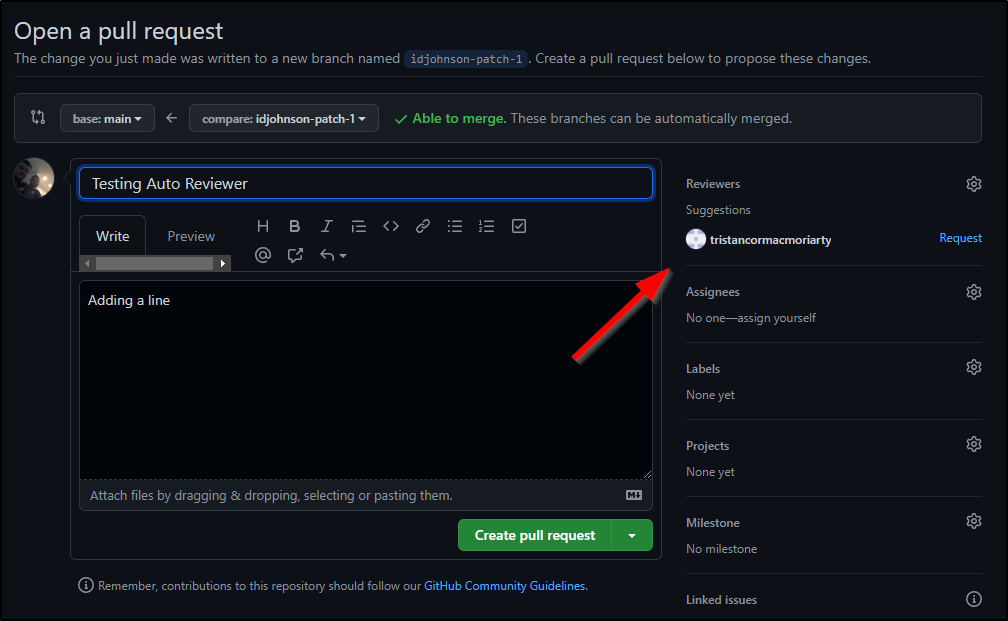
I still needed to click the request button but we can now see that the PR is asking for the person to review:
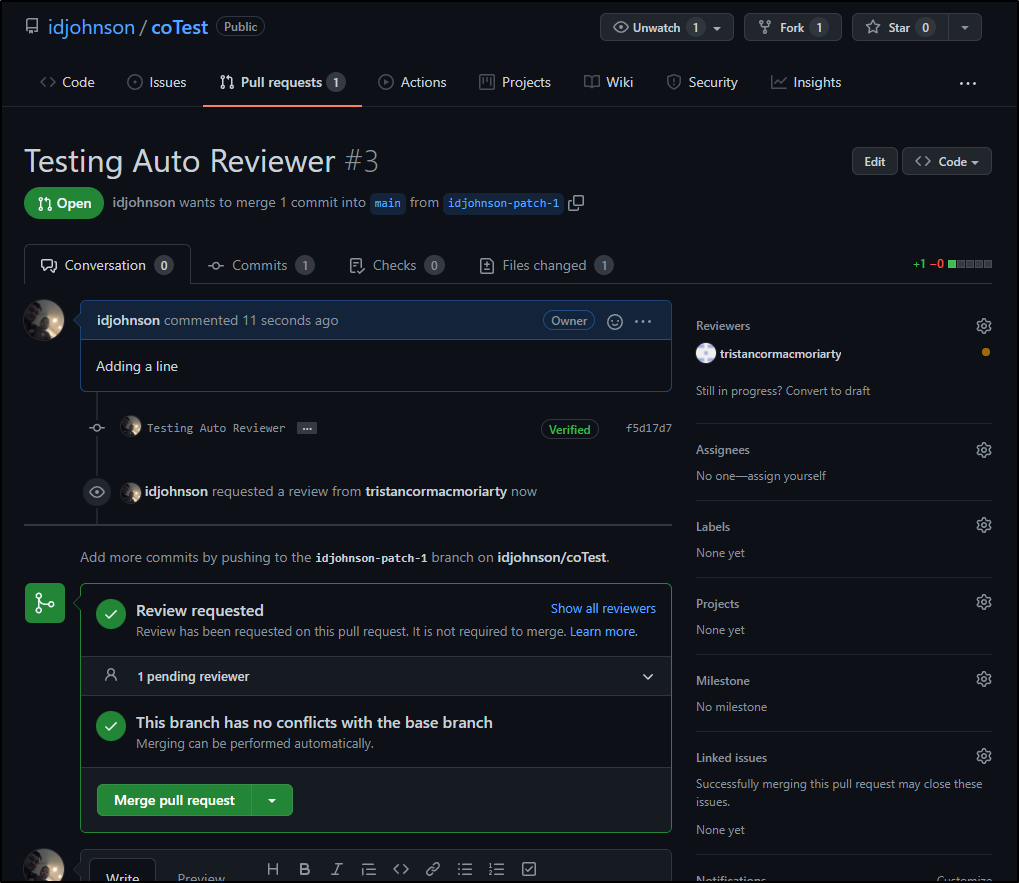
And our reviewer gets emails about being added:
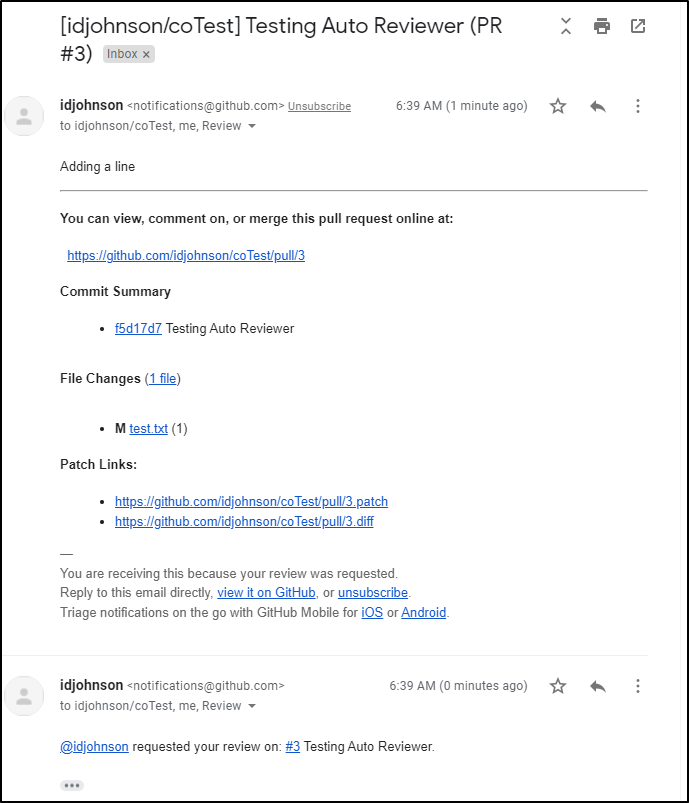
That user can now review and merge
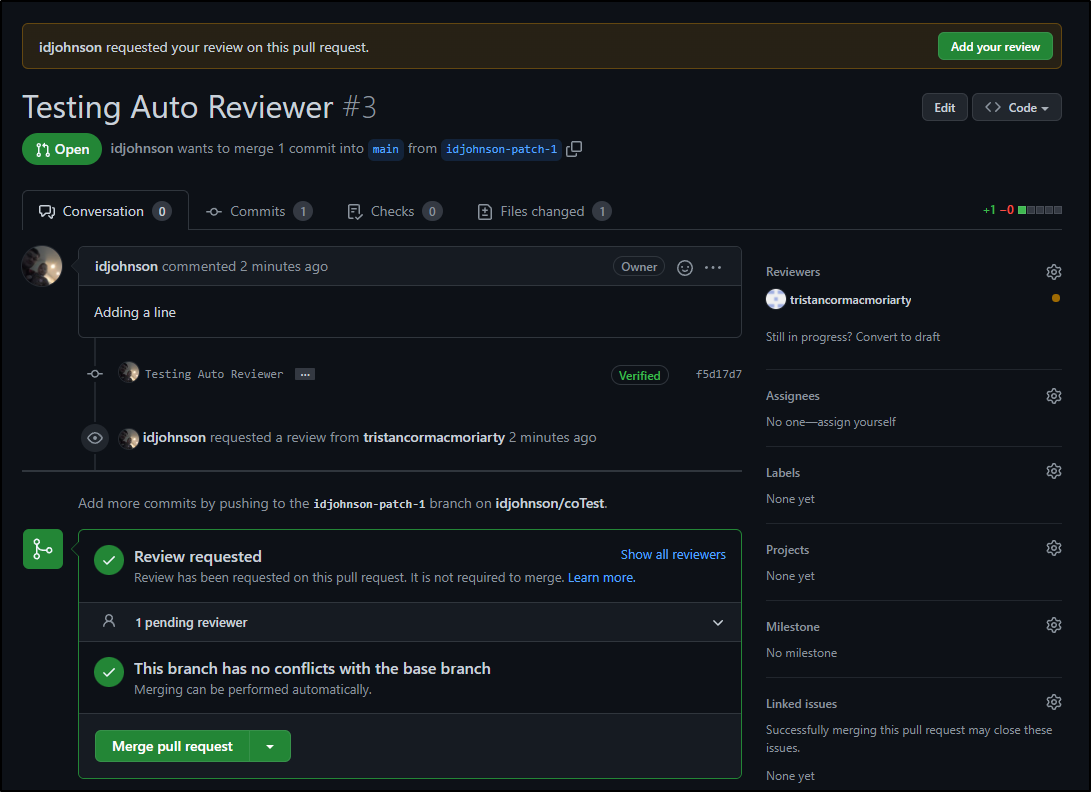
On Notifications / Too Many Optional Reviewers
Getting spammed on updates and reviews might be okay in some cases.
However, in general, I find for the purpose of notification, encouraging users to subscribe to repositories they care about is a far better approach than marking as optional reviewers on PRs.
Summary
In this blog post we covered Project setup in Github with Issue creation and tracking. We compared to Azure Devops and then explored automated reviewers by way of CODEOWNERS vs Branch Policies in Azure DevOps. We walked through a Demo of CODEOWNERS using a Public repo.
Lastly, we focused on Datadog integration, how to use CI tracking as well as tie in Events and Metrics directly in our Github workflows. By way of example, we used a monitor to escalate alerts to Slack and PagerDuty and wrapped by discussing the guiding principles of notifications and escalations in revision control systems.
Github has a lot to offer, even in the free tier. Arguably it takes a bit more work to constrain change outside of the paid levels in comparison to a free tier of Azure DevOps. But this may be worth it as the maturity of Github Actions continues to grow while Azure Pipelines has not had the same level of adoption or updates.
